
One common data type conversion you might encounter when working with Python is converting a string to bytes. This process is crucial when handling files, communicating with network systems, or working with different encodings to ensure the proper representation and processing of your data.
To convert a Python string to bytes in Python, you can use either the bytes() function or the encode() method. Both of them take in string arguments, the preferred encoding format, and return a byte object.
Both approaches are widely used and accepted within the Python community, offering you the flexibility to choose the one that suits your needs best.

By understanding these methods and their usage, you can effortlessly convert your strings into bytes, allowing you to manipulate and process various types of data in your Python code!

What Are Python Strings and Bytes?
In Python, strings and bytes are two built-in data types used to represent textual data and raw binary data, respectively. Understanding their differences and functionalities is key to working effectively with data in Python.
In both Python 2 and Python 3, strings are sequences of Unicode characters represented as str objects. They are used to handle text data, such as words, sentences, or paragraphs. When dealing with strings, you usually work with text-based operations like slicing, concatenation, and formatting.
On the other hand, bytes are sequences of raw binary data represented as byte objects in Python 3 and str objects in Python 2. Bytes are used when working with file I/O, network communication, and other low-level operations that involve raw binary data.
It’s important to note that Python 2 has a separate Unicode data type for Unicode strings, while Python 3 unifies both into the str data type.
3 Ways How to Convert a Python String to Bytes
In this section, we’ll discuss various methods to convert a Python string to bytes. We’ll cover three techniques: the encode() method, bytes() function, and codecs library.

Here’s how you can use them when converting Python strings to bytes:
1. Using Encode Function
The encode() method is one of the simplest and most powerful ways to convert a string to a byte. Let’s look at its syntax:
byte_obj = str_obj.encode(encoding_format)Where:
- encoding_format: Your preferred character encoding format. The default format is UTF-8, but you can also use other Python encoding formats like UTF-16 and ASCII encoding.
Let’s put it to work in an example:
string_var = "your string"
byte_array = string_var.encode('utf-8')
print(byte_array)Output:
b'your string'From the output, we can see that it returns a byte string. Byte strings are simply a sequence of bytes, unlike a string, which is just a sequence of characters.
We can access each byte in the string using list indexing. For example:
print(byte_obj[0], byte_obj[1], byte_obj[2])Output:
121 111 117This is the raw byte representation of the first three bytes in the byte_string byte_obj.
So, as we can see the encode() method is efficient and straightforward for string conversion to bytes.
2. Using Bytes() Function
Another simple way to convert a string to bytes is by using the built-in Python function bytes(). The function takes in an object, an encoding parameter, and returns an immutable byte object.
The syntax for the built-in bytes class function is as follows:
byte_obj = bytes(source, encoding)where:
- source: The first argument is the object, which can be a string, number, iterable, etc.
- encoding: The second argument is the encoding format if the object passed into it is a string.
Here’s an example:
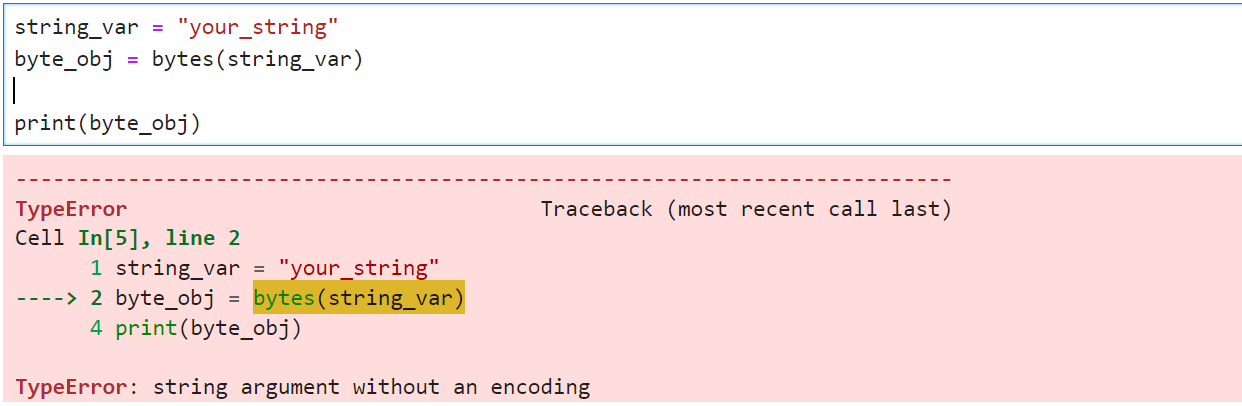
string_var = "your_string"
byte_obj = bytes(string_var, 'utf-8')
print(byte_obj)Output:

b'your string'This method is also quite useful and easy to implement when working with string-to-byte conversions.
Note: You have to pass in an encoding format when the object is a string. If you don’t, you’ll run into an error.
3. Using Codecs Library
The codecs library in Python offers different tools and functionalities for transcoding data in Python. Among these tools is an encode() function that we can use to convert Python strings to bytes.
Its syntax is as follows:
byt_obj = codecs.encode(str_obj, encoding)Where:
- str_obj: String object or stream
- encoding: Encoding method
Let’s test it out with an example:
import codecs
string_var = "your_string"
byte_array = codecs.encode(string_var, 'utf-16')
print(byte_array)Output:
b'xffxfeyx00ox00ux00rx00_x00sx00tx00rx00ix00nx00gx00'The codecs library can be beneficial when working with different types of encodings and character sets. It also works well with Python streams.
By using these techniques, you can easily convert string to bytes in Python. Choose the method that best suits your needs and fits your program’s requirements.
How to Handle Integers in String and Bytes Conversion

In your Python journey, you might come across situations where you need to convert integers or other distinct data types into bytes and vice versa.
To handle these conversions, it’s crucial to implement efficient and readable methods. This section will guide you through the process using Python’s built-in functions and libraries.
When converting integers to bytes in Python, you have two options. First, you can convert the integer to a regular string, then convert the string object to bytes.
You can also convert the integer directly into a bytes object using the to_bytes() function. Let’s look at them in some examples:
Example 1:
num = 32
str_obj = str(num)
byte_obj = str_obj.encode('utf-8')
print(byte_obj)Output:
b'32'As we can see, we first converted the number into a string, before properly converting it into a byte object.
Example 2:
num = 32
byte_obj = num.to_bytes(3)
print(byte_obj)Output:
b'x00x00 'The to_bytes() method takes in an argument that specifies how many bytes can be used to represent the number. You can convert it back to an integer using the int.from_bytes() method.
How to Create Mutable Byte Objects with ByteArray()

When working with Python, it’s essential to understand the difference between mutable and immutable bytes. In general, a mutable object is one that can be modified after it has been created, whereas an immutable object cannot be modified.
In Python, bytes are immutable sequences of integers in the range 0 <= x < 256. However, scenarios can arise when you might need to replace or modify some items in the byte sequence.
This is where byte arrays come in. A byte array is a mutable counterpart of bytes. It represents a mutable sequence of bytes.

You can create a bytearray using the bytearray() constructor:
mutable_bytes = bytearray([72, 101, 108, 108, 111])You can also convert strings into a byte array using the bytearray() function. It uses the exact same syntax as the byte function. However, instead of returning an immutable byte object, it returns a mutable byte array.
Let’s look at an example:
str_obj = 'Hello world!'
byte_arr = byte_array(str_obj, 'utf-8')
print(byte_arr)Output:
bytearray(b'Hello world!')Since bytearrays are mutable, you can modify them using methods like append(), extend(), or pop(). For example:
byte_arr.append(32)
byte_arr.extend([87, 111, 114, 108, 100])
print(byte_arr)Output:
bytearray(b'Hello world! World')One noteworthy point is that when you need to work with a large amount of binary data, especially in a memory-constrained environment, using bytearray can help reduce memory usage by allowing in-place modification of the data.
Using Memoryview with ByteArray
Memoryview is another essential tool in Python when working with mutable and immutable bytes. It provides a way to access the internal data of an object without copying it.
This can be useful when processing large data arrays or when working with multiple bytearray objects. To create a memoryview object, you can use the memoryview() function and pass an object that supports a buffer interface like bytearray:
mem_view = memoryview(byte_arr)Using memoryview, you can slice, delete, or modify parts of the underlying data without making an additional copy. This can be beneficial for performance and memory usage in certain cases.
By understanding the differences between mutable and immutable bytes, as well as the capabilities of bytearray and memoryview, you can efficiently work with the binary data in Python while keeping your code clear and concise.
File Handling with Strings and Bytes

In Python, working with strings and bytes is often necessary when handling files. Let’s explore some general file operations that involve strings and bytes.
To read strings from a text file, use the following code:
filename = "example.txt"
with open(filename, "r", encoding="utf-8") as file:
content = file.read()
In the example above, the with statement ensures the file is closed after the block of code is executed. The “r” parameter indicates the file is opened in read mode.
To write a string to a text file, you can use the following code:
filename = "example.txt"
text = "This is the text content you want to write."
with open(filename, "w", encoding="utf-8") as file:
file.write(text)
Here, “w” indicates write mode. Be cautious, as opening a file in write mode will overwrite any existing content.
When handling binary files, like images or other non-text data, you should work with bytes directly. To read a binary file, open the file in binary mode (‘b’):
filename = "example.bin"
with open(filename, "rb") as file:
content = file.read()Just like the read mode for text files, “rb” indicates read-binary mode. To write bytes to a binary file, use the following code:
filename = "example.bin"
binary_data = b'x42x65x61x75x74x69x66x75x6cx20x62x79x74x65x73'
with open(filename, "wb") as file:
file.write(binary_data)In this instance, “wb” signifies write-binary mode.
Understanding these fundamental file-handling operations with strings and bytes will allow you to manage files effectively and efficiently in Python.
Final Thoughts
In summary, the ability to convert Python strings to bytes and vice versa is a fundamental aspect of Python programming, particularly in scenarios involving data serialization, network communication, and file handling.
By grasping the principles behind encoding and decoding, developers can ensure seamless data exchange in their applications. So, as you delve into the world of Python development, embrace these techniques and unlock the full potential of string and byte manipulation for your projects.
If you’re still curious about datatype conversion, you can check out our article on Python String to Int: A Guide on Easy Conversions! You can also check out our video on how to use Unicode emojis in Power BI:
Frequently Asked Questions
Can I convert a string to bytes without specifying an encoding?
You can only use the encode() method without specifying an encoding, as Python will default to UTF-8. Here’s an example:
my_string = "Hello, World!"
byte_string = my_string.encode()
print(byte_string) Output:
b'Hello, World!'What is the method to convert a hex string to bytes in Python?
You can use the bytes.fromhex() method to convert a hex string to bytes. For example:
hex_string = "5f706974686f6e" # "_python" in hex
byte_string = bytes.fromhex(hex_string)
print(byte_string) Output:
b'_python'How to convert bytes back to a string?
You can convert bytes back to string by using the decode(), bytes.decode(), str(), and codecs.decode() functions. For example:
import codecs
byte_string1 = b'xffxfeyx00ox00ux00rx00_x00sx00tx00rx00ix00nx00gx00'
byte_string2 = b'your string'
print(byte_string1.decode('utf-16'))
print(bytes.decode(byte_string2, 'utf-8'))
print(str(byte_string1, 'utf-16'))
print(codecs.decode(byte_string2))Output:
your_string
your string
your_string
your stringHow to Handle Errors When Converting String to Bytes?
Sometimes, you can encounter decoding errors when converting strings as you might attempt to convert an unsupported character. Luckily, all the three conversion methods we mentioned above have an additional parameter, errors, that you can use to handle it.
The error parameter can take in several values. Three of the most important include: strict, ignore, and replace.
- strict raises an error when it encounters a character that can’t be encoded
- ignore ignores the character
- replace replaces it
Let’s look at them.
import codecs
str1 = 'm??n'
print(bytes(str1, 'ascii', errors = 'ignore'))
print(codecs.encode(str1, 'ascii', errors = 'replace'))
str1.encode('ascii', errors = 'strict')Output:
b'mn'
b'm??n'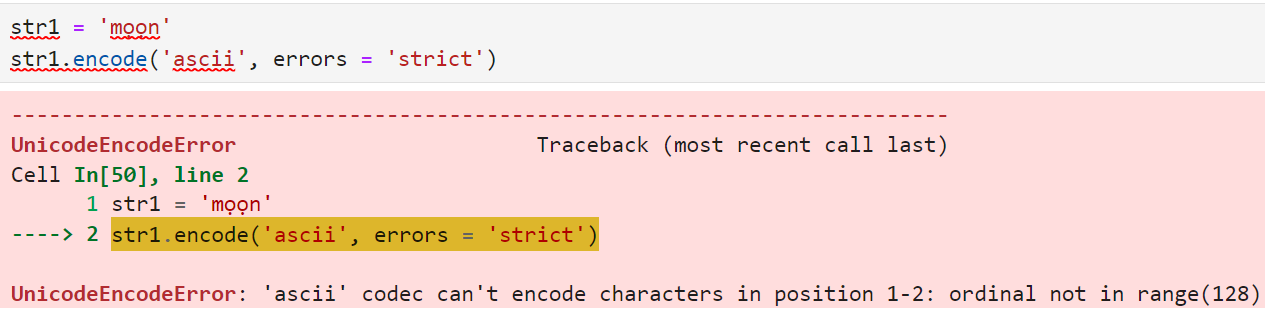
You should note that if you don’t specify an error parameter, it defaults to strict in all three methods.


