
Working with Excel files is a common task in the day-to-day life of many professionals, some of us love it, and others hate it. However, Python provides several libraries to make this process easier, more streamlined, and more efficient.
Both the Pandas Library and openpyxl allow users to open an excel file in Python. Pandas has a built-in method making it easy, whilst openpyxl is great when you need more control over the file’s structure and formatting.
In this article, we’ll explore various methods to open and work with spreadsheets in Python using these libraries. With this knowledge, you’ll be able to efficiently process and analyze Excel data using the powerful tools provided by Python’s extensive ecosystem!


What Are The Prerequisites?
Before diving into the process of opening an Excel file in Python, there are a few prerequisites that need to be in place. First and foremost, you should have a basic understanding of Python programming, including variables, functions, and importing libraries.
This will help you easily understand and work with the code examples provided in the article.
In addition to basic Python knowledge, installing the necessary libraries is also important. There are several Python libraries available for working with Excel files, including:
pandas: A powerful data manipulation library.
openpyxl: A popular library for reading and writing Excel files.
xlrd: A library for reading data and formatting information from Excel files.
xlwt: A library for writing data and formatting information to Excel files.
xlutils: A suite of tools for working with Excel workbooks, including reading, writing, and modifying data.
To install any of the above libraries using pip, open the command prompt or terminal and type the following command, replacing `library_name` with the desired library:
pip install <library_name>Another crucial prerequisite is having an Excel spreadsheet to work with. You should prepare an Excel workbook containing data you wish to manipulate with Python.
You can download sample workbooks from Microsoft and other tutorial sites.

Although the file can have multiple sheets and various formatting, it is advisable to start with a simple dataset for the initial learning process. You can tackle complex spreadsheets once you gain more experience and understanding of the libraries in use.
How to Instal Required Libraries
To work with Excel spreadsheets in Python, you need to install the appropriate libraries. There are several libraries available for this purpose, but two of the most popular ones are openPyXL and xlrd.
OpenPyXL is a Python library that allows reading and writing Excel files (specifically xltm, xlsm, xltx, and xlsx files). It does not require Microsoft Excel to be installed and works on all platforms. To install OpenPyXL using pip, run the following command in your terminal:
pip install openpyxl
On the other hand, xlrd is another widely-used library for reading data and formatting information from Excel files. It specifically supports xls and xlsx file formats.
To install xlrd using pip, run the following command in your terminal:
pip install xlrd
Once the desired library is installed, one can proceed with reading or writing Excel files in Python. Each library has its unique features and syntax, so it is essential to choose the one that best suits your requirements.
2 Ways How to Open an Excel File in Python
In this section, we will discuss two popular methods to open an Excel spreadsheet. We’ll be exploring how you can do this with both the Pandas and Openpyxl libraries.
1.Using Pandas
Pandas is a powerful data analysis library in Python that provides convenient functionalities to read, write, and manipulate data from various formats, including Excel and CSV file formats.
You can check out its capabilities in this video on How To Resample Time Series Data Using Pandas To Enhance Analysis:
To open an Excel spreadsheet using Pandas, follow the instructions below:
First, install the Pandas library if you haven’t already. You can install it using pip:
pip install pandas
Next, import Pandas in your Python script and use the read_excel() function to load the file:
#Read excel spreadsheets with pandas import pandas as pd file_name = "path/to/your/file.xlsx" # Replace with your file path sheet = "Sheet1" # Specify the sheet name or number df = pd.read_excel(io=file_name, sheet_name=sheet) print(df.head(5)) # Print first 5 rows of the dataframeThis will read the specified Excel sheet into a Pandas DataFrame, which can then be easily manipulated using various built-in functions.
Note: If you do not specify a sheet name, the pandas library will import all the sheets and store them in a dictionary. You can access these sheets by using the sheet name as a key.
For example, if you want to retrieve a sheet named ‘monthly_report‘, you can use the code below:
print(df['monthly_report'])2.Using openpyxl
Openpyxl is another popular library in Python for working specifically with Excel files. To open an Excel workbook in Python using Openpyxl, follow the instructions below:
First, install openpyxl if you haven’t already. You can install it using pip:
pip install openpyxlNext, import openpyxl in your Python IDE and use the load_workbook() function to load your Excel workbook:
from openpyxl import load_workbook file_name = "path/to/your/file.xlsx" # Replace with your file path workbook = load_workbook(file_name) sheet = workbook.active # Selects the first available sheet # Read data from the excel sheet for row in sheet.iter_rows(): print([cell.value for cell in row])
This will load the specified Excel file and provide access to its sheets, rows, and individual cells, allowing you to easily work with its data.
Both Pandas and openpyxl are powerful libraries that allow you to efficiently open and manipulate Excel files in Python. Choose the one that best fits your specific needs and requirements.

How to Read Excel Data in Python?
Reading Excel data in Python can be easily achieved using the Pandas library, which provides a powerful and simple-to-use set of methods for working with tabular data. In this section, you will learn how to read Excel data using pandas, focusing on accessing specific sheets and retrieving cell values.
Read Specific Sheet
To read a specific sheet from an Excel file using pandas, you simply need to pass the sheet name or sheet index as a parameter to the read_excelmethod. Here is an example:
import pandas as pd
file_name = 'example.xlsx'
sheet = 'Sheet1'
df = pd.read_excel(io=file_name, sheet_name=sheet)
print(df)
This code snippet imports the Pandas library and specifies the name of the Excel spreadsheet, and the sheet to be read. It then reads the specified sheet using the read_excel() method and prints the resulting DataFrame.
To import multiple sheets into the data frame, just set the sheet_name parameter to be equal to None. This will import all the sheets in the workbook into your dataframe.
Read Cell Values
Once you’re done importing data into a pandas DataFrame, you can access individual cell values using the DataFrame’s iat[] method. The method takes row and column indices as its arguments.
Here’s an example:
cell_value = df.iat[1, 2]
print(f'The cell value at row 2, column 3 is: {cell_value}')This code snippet extracts the cell value at row index 1 and column index 2 (corresponding to the second row and third column) from the previously loaded DataFrame (df). After extracting the cell value, it prints the value.
In this section, you have learned how to read Excel data in Python, with a focus on reading specific sheets and retrieving cell values using the pandas library. This knowledge will enable you to efficiently work with Excel data in your Python projects.
How to Manipulate Excel Data
In this section, we will discuss how to update cell values, and add or delete rows and columns in an Excel file using Python. For these examples, we’ll be using OpenPyXL since it offers several methods you can use to change or insert data in an Excel workbook.
Update Cell Values
To modify Excel cell values, we’ll use the openpyXL library. Next, import the required module and load the Excel workbook:
#Reading excel files with openpyxl
from openpyxl import load_workbook
workbook = load_workbook('example.xlsx')
Select the Excel sheet you’d like to manipulate.
sheet = workbook.activeThe active method selects the first sheet in the workbook. If you want to select a different sheet, use the workbook[<sheet name>] format.
To change a cell value, simply assign a new value to the desired cell:
sheet['A1'] = "New Value"Finally, save the modified workbook:
workbook.save('example_modified.xlsx')Add and Delete Rows and Columns
Adding and deleting rows or columns can be easily done with OpenPyXL. Here’s how:
Add Rows: To insert rows, use the insert_rows() function. The following example adds two rows after the first row:
sheet.insert_rows(2, 2)
Delete Rows: To delete rows, use the delete_rows() function. The following example deletes two rows starting from row 3:
sheet.delete_rows(3, 2)
Add Columns: To insert columns, use the insert_cols() function. The following example adds two columns after the first column:
sheet.insert_cols(2, 2)
Delete Columns: To delete columns, use the delete_cols() function. The following example deletes two columns starting from column 3:
sheet.delete_cols(3, 2)
Remember to save the updated workbook:

workbook.save('example_modified.xlsx')
How to Save an Excel File in Python
To save an Excel file in Python, you can utilize libraries such as Pandas or openpyxl. Both libraries offer different methods for writing data to Excel files. In this section, we will explore each approach and provide examples of how to save an Excel file using Python.
Using Pandas: Pandas is a popular library for data manipulation and analysis. It has a built-in method called to_excel() which allows you to save a DataFrame as an Excel file:
import pandas as pd
# Creating a sample DataFrame
data = {'Column1': [1, 2, 3],
'Column2': ['A', 'B', 'C']}
df = pd.DataFrame(data)
# Saving the DataFrame to an Excel file
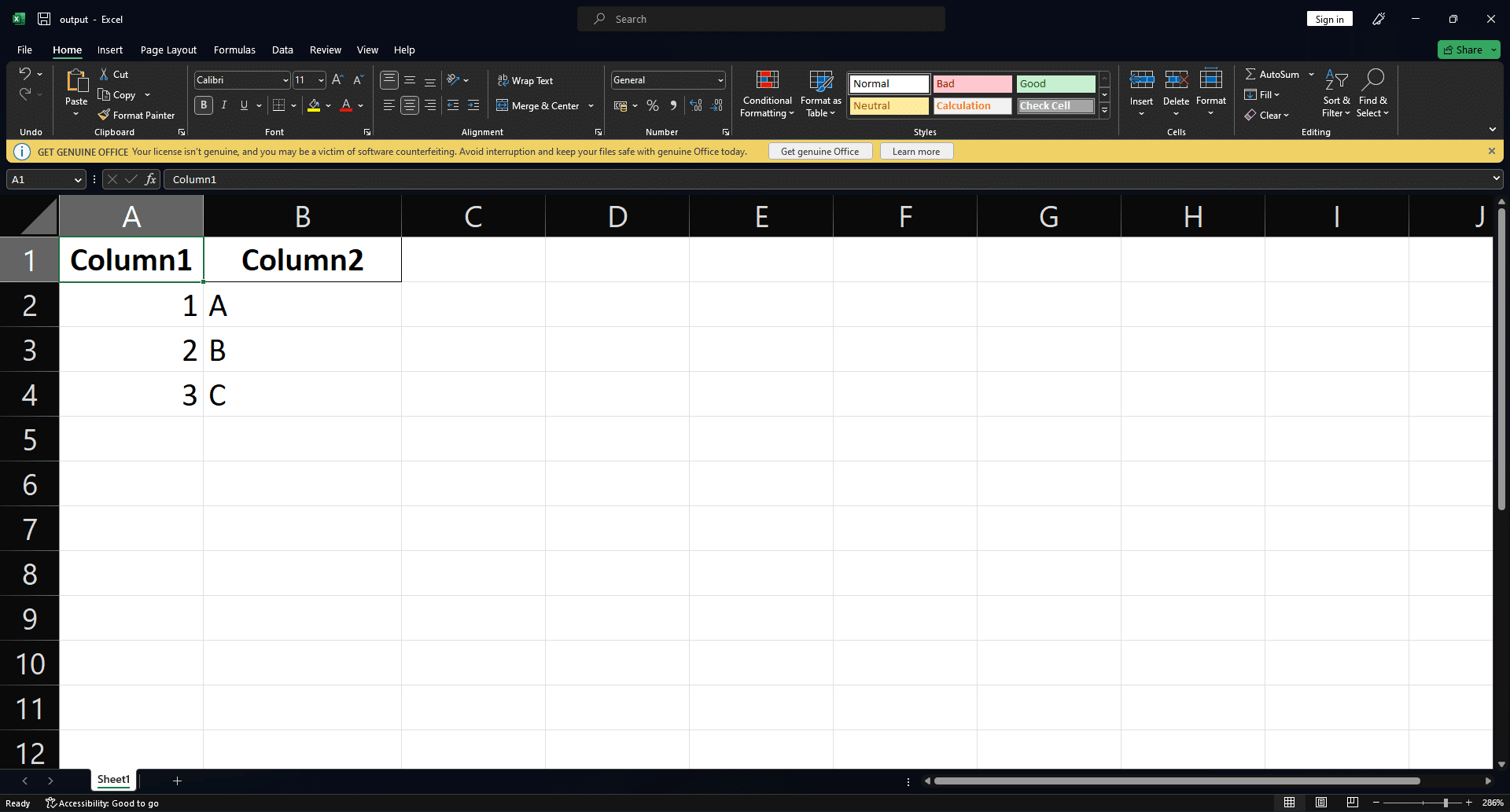
df.to_excel('output.xlsx', index=False)In this example, we create a sample DataFrame and save it as an Excel file named “output.xlsx” using the to_excel() method. You can see the resulting spreadsheet below.
Using OpenPyXL: openpyxl is another powerful library specifically designed for working with Microsoft Excel files. Here is an example of how to save data to an Excel file using OpenPyXL:
from openpyxl import Workbook
# Creating a new workbook
wb = Workbook()
# Selecting the active worksheet
ws = wb.active
# Adding data to the worksheet
data = [
(1, 'A'),
(2, 'B'),
(3, 'C'),
(25, 'Y'),
(26, 'Z')
]
for row in data:
ws.append(row)
# Saving the workbook to an Excel file
wb.save('output_openpyxl.xlsx')
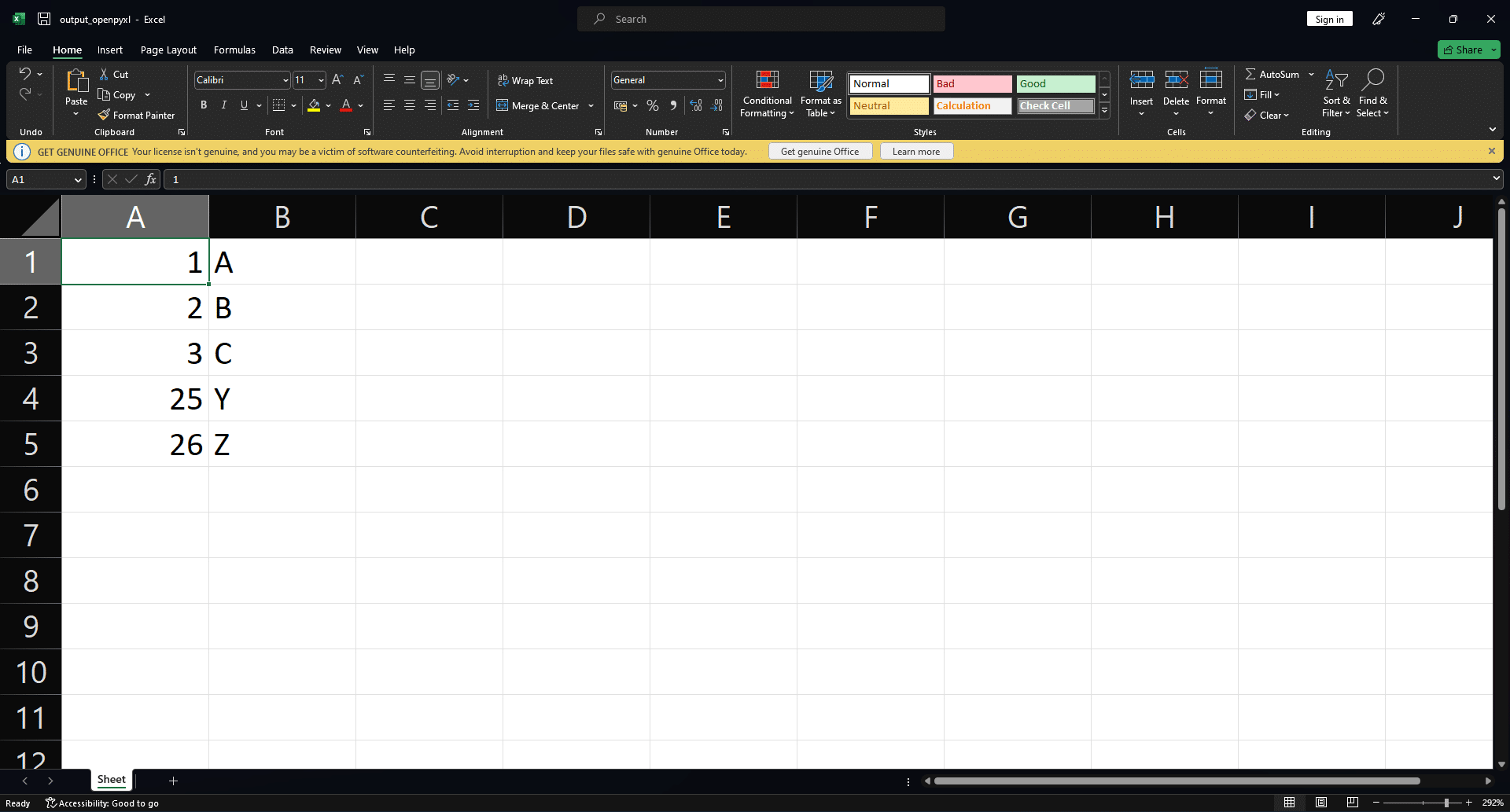
In this example, we create a new workbook and add data to the active worksheet using the append() method. Finally, we save the workbook as an Excel file named “output_openpyxl.xlsx“.
Both Pandas and openpyxl provide robust functionality for saving Excel files in Python. So, your choice depends on the requirements and the complexity of your tasks.
Time To Wrap Things Up
In this article, we explored different libraries for opening and working with Excel files in Python. Each of these libraries has its own unique features and advantages, allowing you to perform tasks such as reading and writing data, accessing sheets, and manipulating cell values.
By incorporating the methods discussed in this article, you can efficiently work with Excel files, expand the capabilities of your projects, and enhance your data analysis and manipulation skills.
As you continue to use these libraries and explore their functionalities, you’ll become more proficient in handling spreadsheets with Python. This article has now equipped you with the skills you need to get the job done. It’s time to test out your new skills!


