
Parquet files are increasingly popular for data storage due to their columnar storage format. It allows for efficient compression and faster query performance. As a result, many data scientists and analysts find it necessary to learn this format. One common task is to load data from a Parquet file into a Pandas DataFrame. This is done for exploration and analysis in Python.
To read a Parquet file into a Pandas DataFrame, you can use the read_parquet() function in the Pandas library, passing the file path of the Parquet file as the argument. This function will read the Parquet file and return a DataFrame containing the data. Ensure that you have the Pyarrow library installed, as it provides the underlying functionality for reading Parquet files.

By using this function, you can easily read a Parquet file into a Pandas DataFrame like any other file. This doesn’t require an extensive setup, such as cluster computing infrastructure or interaction with Hadoop Distributed File System (HDFS).

In this article, we’ll explore how you can read a Parquet file into a Pandas DataFrame.
Let’s get into it!
Understanding Parquet Files and Pandas DataFrames
Before we start writing code for importing a Parquet file in a Pandas DataFrame, let’s quickly review some basic concepts you should know when working with a Parquet file in Python.

What is a Parquet File?
Parquet is a popular column-oriented data file format designed for use with Big Data processing frameworks such as Hadoop, Spark, and Impala.
Parquet stores data in a columnar format, unlike row-based file formats like CSV and Excel.
This provides more efficient storage and retrieval of data.

What Are the Benefits of Parquet Files?
There are many advantages that Parquet files provide when handling large amounts of data in a column-oriented format.
Specifically:
- Faster Access to Data: Storing data in columns allows Parquet to quickly access specific subsets of columns, yielding better performance in data retrieval.
- Encoding Efficiency: Columnar storage enables more efficient data encoding and compression techniques, reducing storage space and IO cost.
- Schema Evolution: Parquet files support changes to the schema over time, allowing the addition or removal of columns without breaking existing code.
- Interoperability: Parquet is a standardized format that is compatible with various big data processing frameworks, including Hadoop, Spark, and more.
What is a Pandas Dataframe?
A Pandas DataFrame is a two-dimensional labeled data structure in Python designed for data manipulation and analysis.
How to Import Libraries for Reading Parquet Files in Python
We’ll now discuss how to read a Parquet file into a Pandas DataFrame.

Specifically, we’ll be using two different libraries:
- Pyarrow
- Fastparquet
1. Importing Required Libraries
To read a Parquet file into a pandas dataframe, you will need to install and import the following libraries:
- pandas
- pyarrow
- fastparquet
The following code shows you how you can install these libraries on your operating system:
pip install pandas
pip install pyarrow
pip install fastparquetThe code below shows you how to import these libraries in your Python script:
import pandas as pd
import pyarrow
import fastparquet2. Using Pyarrow to Read Parquet Files
Pyarrow is an open-source Parquet library that plays a key role in reading and writing Apache Parquet format files.
Once you have Pyarrow installed and imported, you can utilize the pd.read_parquet() function with a file path and the Pyarrow engine parameter.
This function will load the Parquet file and convert it into a Pandas DataFrame:
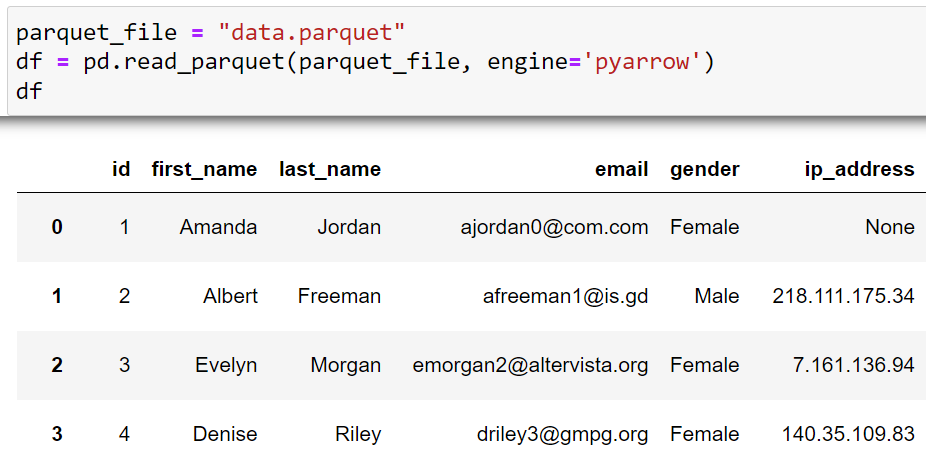
parquet_file = "data.parquet"
df = pd.read_parquet(parquet_file, engine='pyarrow')The resulting dataframe from the above code will be:
3. Using Fastparquet to Read Parquet Files
Fastparquet is another Python library commonly used for reading and writing Parquet files.
You can install Fastparquet using pip, just like Pyarrow:
pip install fastparquetThe above command will install fastparquet onto your system.

After installing Fastparquet, you can use the pd.read_parquet() function and specify the engine parameter to be ‘fastparquet’.
This will load the Parquet file into a Pandas DataFrame:
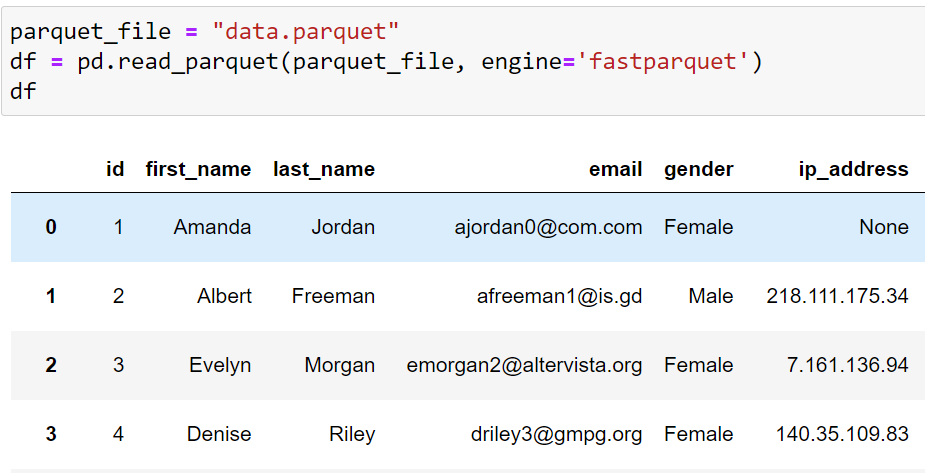
parquet_file = "data.parquet"
df = pd.read_parquet(parquet_file, engine='fastparquet')The code will print the following:
You can read Parquet files into a Pandas DataFrame by using either Pyarrow or Fastparquet libraries.
Advanced Parquet File Reading Techniques in Python
The section above highlights importing a Parquet file into a Pandas DataFrame with default parameters. However, you can customize the parameters to your liking as well.

In this section, we’ll look at some advanced techniques for reading different files into a Pandas DataFrame.
1. How to Specify Columns and Storage Options
You can customize the loading process of a Parquet file by specifying columns or handling different storage options.
To select only a subset of columns from the file, you can pass a list of columns to the columns parameter.
The following example demonstrates this feature:
dataframe = pd.read_parquet("data.parquet", columns=['id', 'first_name','last_name','email'])The output will be:
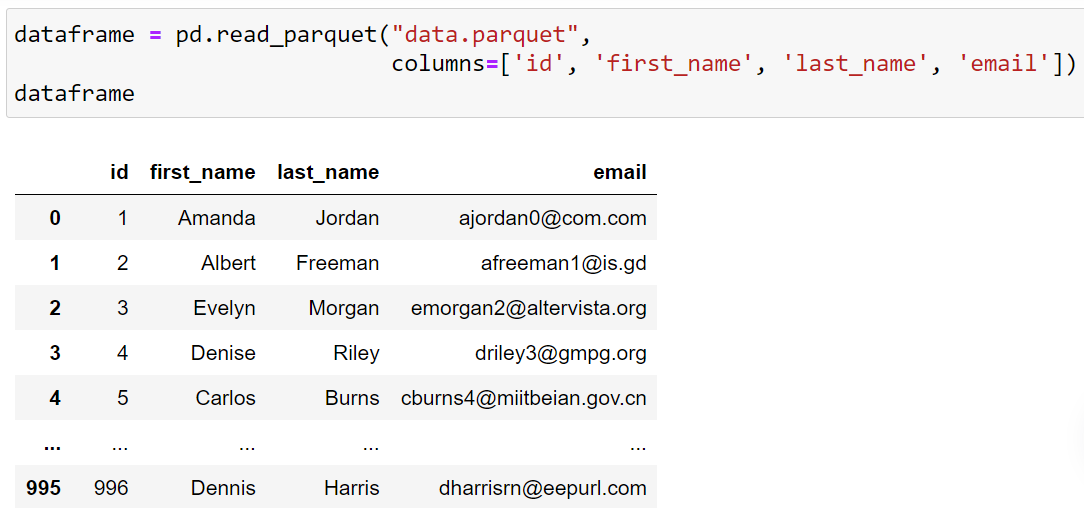
As you can see that the output only contains the specified columns. A common issue that can occur here is that of a missing value indicator. You need to make sure that you are using the exact column names as in the dataset.
Pandas also allows reading Parquet files from various storage systems like S3 by providing the appropriate storage_options.
You can use the following code when reading files from a different storage system:
storage_options = {"key": "your_key", "secret": "your_secret"} # for S3 storage
dataframe = pd.read_parquet("s3://your-bucket/your-parquet/file", storage_options=storage_options)2. How to Handle Compression and Data Storage
You can also use different compression methods on Parquet files, including GZIP, Snappy, and Brotli. The read_parquet() function automatically decompresses the data.
If your data is stored in a different format, like CSV files, you can first read it into a DataFrame.
You can then convert it to a Parquet data using the to_parquet() function as shown below:
parquet_df = pd.read_csv("path/to/your/csv/file")
parquet_df.to_parquet("output/path/your-parquet-file.parquet", compression='gzip')In the code above, the compression parameter specifies the desired compression method for your Parquet file(parquet df). The available options are auto, gzip, snappy, and brotli.
Additional Features and Considerations for Parquet Files in Python
When working with parquet files in pandas, you’ll often encounter roadblocks due to the memory size or the data type formats.

This section will highlight some considerations you should remember when working with parquet files.
1. Working With Larger Data Sizes and Distributed Processing
When working with large datasets or multiple files, libraries like Pandas might not be sufficient. In such cases, you should use specialized libraries for big data processing.

One such library is Dask, which is designed to handle larger-than-memory datasets and parallelize computations across multiple cores or nodes.
For instance, to read a partitioned dataset with Dask, you can provide the root directory path containing Parquet files and use the compute() method to convert it into a Pandas DataFrame as shown below:
import dask.dataframe as dd
df = dd.read_parquet("path/to/directory")
computed_df = df.compute()
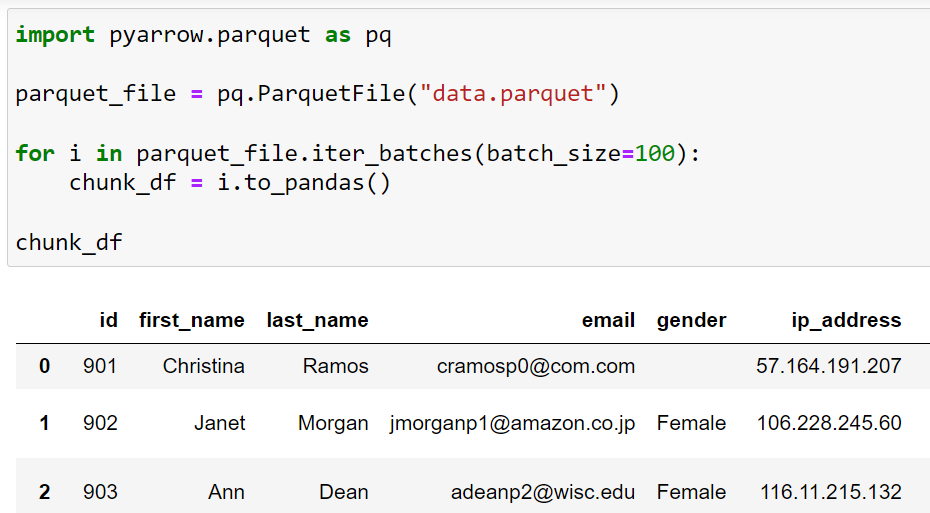
You can also use the pyarrow.parquet module from Apache Arrow library and iteratively read chunks of data using the ParquetFile class:
import pyarrow.parquet as pq
parquet_file = pq.ParquetFile("example.parquet")
for i in parquet_file.iter_batches(batch_size=100):
chunk_df = i.to_pandas()This code will read the entire dataset in chunks, 100 rows in a single iteration.
2. Handling Nullable Data Types and Schema Evolution
Apache Parquet is designed to support schema evolution and handle nullable data types.
You can use the Pandas pd.NA object to represent missing values. You can also use the use_nullable_dtypes parameter in pd.read_parquet() to work compatibly with nullable data types.
For instance:
import pandas as pd
df = pd.read_parquet("example.parquet", use_nullable_dtypes=True)In cases where the schema of a Parquet file has evolved, reading the file using a compatible schema will ensure that your DataFrame contains the correct data:
schema = pq.schema(["student", "marks"])
.parquet_file = pq.ParquetFile("example.parquet", schema=schema)
df = parquet_file.to_pandas()3. Performance and Limitations
While Pandas offers the convenience of providing a user-friendly data analysis environment, it still has some performance limitations when working with large-scale datasets and complex computations.
The performance can be improved by using other libraries or tools like Numba. It increases the performance of Python code by generating optimized machine code using LLVM compiler infrastructure.
You can specify the engine by setting the io.parquet.engine option in Pandas or providing the engine parameter in pd.read_parquet():
import pandas as pd
df = pd.read_parquet("example.parquet", engine="pyarrow")To learn more about data wrangling in Python, check the following video out:
Final Thoughts
Mastering the technique of reading a parquet file into a Pandas DataFrame is an essential skill for any data professional.
By knowing how to do this, you unlock the capacity to handle complex data sets that are often stored in the Parquet format. This knowledge will amplify your ability to analyze, manipulate, and visualize data.
Moreover, Pandas integration with Parquet files can streamline your workflow, reduce data preparation time, and allow you to focus more on critical thinking and solution creation.
Just follow the simple steps and let Pandas do the heavy lifting. Before you know it, you’ll be a Parquet pro, unleashing the full potential of your data for analysis, machine learning, or whatever cool stuff you’ve got in mind!
Frequently Asked Questions

1. What makes Parquet files unique and why should I use them?
Parquet files are a columnar storage file format optimized for use with big data processing frameworks.
They’re unique for their ability to store data in a highly efficient, compressed format, which speeds up read and write operations.
2. Are there any specific packages or libraries required to read Parquet files into a pandas DataFrame?
Yes, to read Parquet files into a pandas DataFrame, you’ll need the ‘pyarrow’ or ‘fastparquet’ engine installed in your environment.
3. What are some common issues or errors that might arise when reading a Parquet file into a pandas DataFrame, and how can I resolve them?
Common issues might include incompatible data types, missing dependencies, or memory issues with large files.
These can often be resolved by appropriate data type conversion, ensuring all required packages are installed and up-to-date, or reading in only a subset of a large file.
4. Can I read only a specific subset of data from a large Parquet file into a pandas DataFrame to save memory?
Yes! You can specify which columns you want to read from a Parquet file. This can significantly reduce memory usage when dealing with large files.
5. How can I handle nested data or complex data structures in Parquet files using pandas?
Pandas can handle complex data structures to a certain extent, but truly nested data might require flattening or specific handling with PyArrow or Fastparquet before you utilize it in a pandas DataFrame.


