
With the advent of ChatGPT, individuals and businesses worldwide have been using it to simplify their daily tasks and boost their productivity. Content writers use it to come up with outlines for their tasks and programmers are using it for code optimization. Similarly, data scientists have been using ChatGPT to make more insightful analyses through their projects.
ChatGPT is a powerful tool for data scientists that can enhance your work and help you find quick, accurate answers to a wide range of data-related questions. It can streamline your workflows and make your analyses more efficient and effective.

In this article, we’ll explore how ChatGPT can elevate your data science skill set by providing dynamic feedback and suggestions. We’ll cover key features, best practices, and valuable tips to help you make the most of ChatGPT in your projects.

Let’s get into it!
ChatGPT for Data Science
ChatGPT has been steadily gaining popularity for its ability to assist data scientists in their daily tasks. It can understand large amounts of data and generate code snippets for robust analyses.

As a data scientist, working with ChatGPT can be a game changer for tasks like project planning, code debugging, code optimization, and data mining.
ChatGPT offers support for almost all the programming languages out there such as SQL, R, and Python. For example, through a correct SQL code prompt, ChatGPT can help you write SQL code for your projects. It can also translate Python, describe regex, and perform unit tests.
You’ll find ChatGPT helpful for the following data science jobs:
Analyzing and summarizing extensive datasets
Content creation with the right data science prompts
Generating insights from the data
Assisting with data preprocessing
Providing code examples for common tasks
If you are looking to increase your productivity, ChatGPT is a must-have tool. It’s a software developer, code translator, code optimizer, data science career coach, and data science instructor in one package!

In the next section, we’ll go over the fundamentals of ChatGPT. This will give you an idea of the strengths and weaknesses of the AI chatbot.
Fundamentals of ChatGPT – 3 Ways to Use it
In this section, you’ll discover the core capabilities and features of ChatGPT that make it an invaluable tool for data scientists.
Understanding these fundamentals will give you insights into how ChatGPT can assist you in various data-related tasks.
1. Text Handling
ChatGPT works with text data to create human-like responses. As a data scientist, you can harness the power of ChatGPT to analyze large datasets, describe graph requirements, and generate insights.
Some important features of text handling include:
Tokenization: Break down input text into chunks or tokens, which ChatGPT then processes.
Preprocessing: Removing stop words, stemming, and other textual cleansing techniques can improve the quality of analysis.
Text generation: Use the chat model to generate text based on your data or specific prompts.
2. Prompts and Responses
Good prompts give you good responses. Prompts are essential in guiding ChatGPT to provide meaningful information. When working with data and code, make sure that you employ detailed prompts to obtain desired outcomes.

We’ve listed some tips for writing good prompts below:
Be specific in your prompt: Clear and detailed prompts help ChatGPT understand your requirements better. For example, if you want to use it as a code explainer for Python concepts, write a Python prompt that specifies everything you want to learn.
Include context in your prompt: Contextual information helps ChatGPT generate accurate responses.
Iteratively refine your prompt: If the generated response isn’t satisfactory, provide feedback, and try again.
Examples of prompts you can use with ChatGPT as a data scientist:
"Provide a brief explanation of k-means clustering algorithm."
"Generate Python code to open a CSV file and display its contents using pandas library."
"Compare linear regression and logistic regression."3. Algorithm Overview
ChatGPT is built on the GPT-3.5 architecture. It is an advanced language model developed by OpenAI that employs deep learning algorithms to generate human-like responses.
Some core components of ChatGPT you should be aware of include the following:
Deep learning: ChatGPT uses neural networks to process and understand the text. These neural networks enable it to generate relevant responses.
Training: The model is trained on vast amounts of text data from various sources, including books, articles, and websites.
Multilingual support: As a result of extensive training, ChatGPT can understand and generate text in multiple languages.
In the next section, we’ll look at specific examples and use cases of ChatGPT for data science.
4 Use Cases of ChatGPT for Data Scientists?
If you’re a data scientist, you can use ChatGPT for several purposes in your projects. You’ll find that each of the use cases will help you write code with the least amount of effort.
Specifically, we’ll look at the following use cases of ChatGPT for a data scientist:
Using ChatGPT for preprocessing and feature engineering
Using ChatGPT for data analysis and data visualization
Let’s get into it!
1. Preprocessing and Feature Engineering
If you want to analyze data, preprocessing and feature engineering play a crucial role in preparing the data for modeling.

This step of the data analysis workflow goes hand-in-hand with data cleaning and transformation, where you have to make changes to your data to make it suitable for the model.
When performing the tasks, we mostly look at the following two aspects:
Handling missing values and categorical variables
Scaling numerical values
Let’s look at each one separately and see how ChatGPT can help.
[wpforms id=”211279″]
1. Handling Missing Values
First, you need to assess the presence of missing values in your dataset.
There are various strategies for dealing with missing data, including:
Removing the records with missing values
Imputing missing values with the mean, median, or mode
Using a machine learning model to predict missing values
To generate code for handling missing values using ChatGPT, you can enter the following Python code prompt in the command prompt:
I want you to act as a data scientist. Write Python code that uses the Pandas library to read a CSV file called ‘data.csv’, checks for any missing values in the data, and then fill any missing values using the mean value of the respective column.
When you enter this prompt into ChatGPT, it will write the following Python code for you, including the code comments:
import pandas as pd
# Load data
data = pd.read_csv('data.csv')
# Check for missing values
missing_values = data.isnull().sum()
# Impute missing values using the mean
data.fillna(data.mean(), inplace=True)Let’s check the above code out on a dataset!
First, we’ll import a dataset into Jupyter Notebook using the pandas library.

Next, let’s check for missing values with the code provided by ChatGPT.
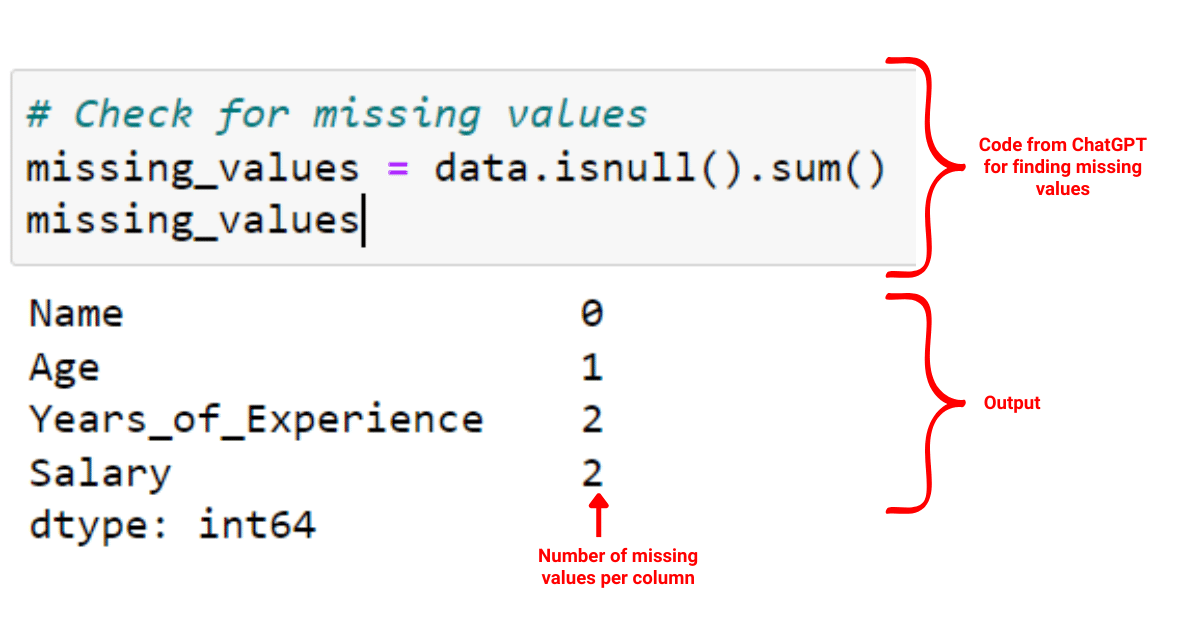
We see that there are some missing values in our dataset.
To handle the missing values, we can use impute missing values using the mean with the code provided by ChatGPT.

In the image above, you can see that there are no longer any missing values in our dataset.
2. Dealing with Categorical Variables
Dealing with categorical variables is another important step during preprocessing. Before you implement a model and use a model’s results, you should encode your target variable to a numerical format that machine learning algorithms can understand.
To do so, you can use one of the following methods:
Label encoding: Assigns a unique integer to each category
One-hot encoding: Creates binary columns for each category
In label encoding, you assign a unique integer to each category. You can use ChatGPT for writing code for label encoding. The following prompt will give you the required code for label encoding:
Act as a data science instructor and write a Python script using the pandas and sklearn libraries that creates a DataFrame with ‘Name’, ‘Age’, ‘Gender’, and ‘Profession’ columns. Then, use label encoding to transform the ‘Profession’ column. After that, perform one-hot encoding on the ‘Profession’ column.
The above code when fed into ChatGPT will give you the following code:

import pandas as pd
from sklearn.preprocessing import LabelEncoder
# Label encoding for the 'Profession' column
encoder = LabelEncoder()
data['Profession'] = encoder.fit_transform(data['Profession'])
# One-hot encoding for the 'Profession' column
data = pd.get_dummies(data, columns=['Profession'])
Let’s check this code out on a dataset and see if it works!
Suppose we have the following dataset that we want to perform label and one-hot encoding on:
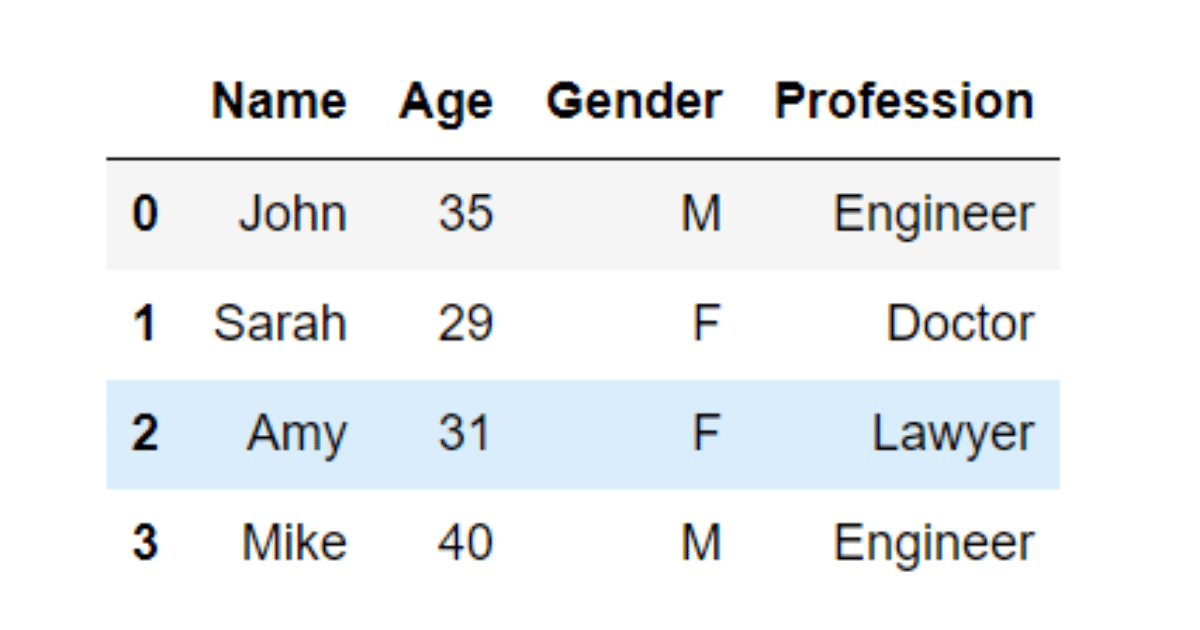
We see that Profession is a categorical variable; therefore, we need to encode this variable before implementing a machine learning model. To encode, we can use the code provided by ChatGPT.
We have assigned a unique integer to each of the Profession categories in our dataset.
To perform label encoding, we can use the code provided by ChatGPT:
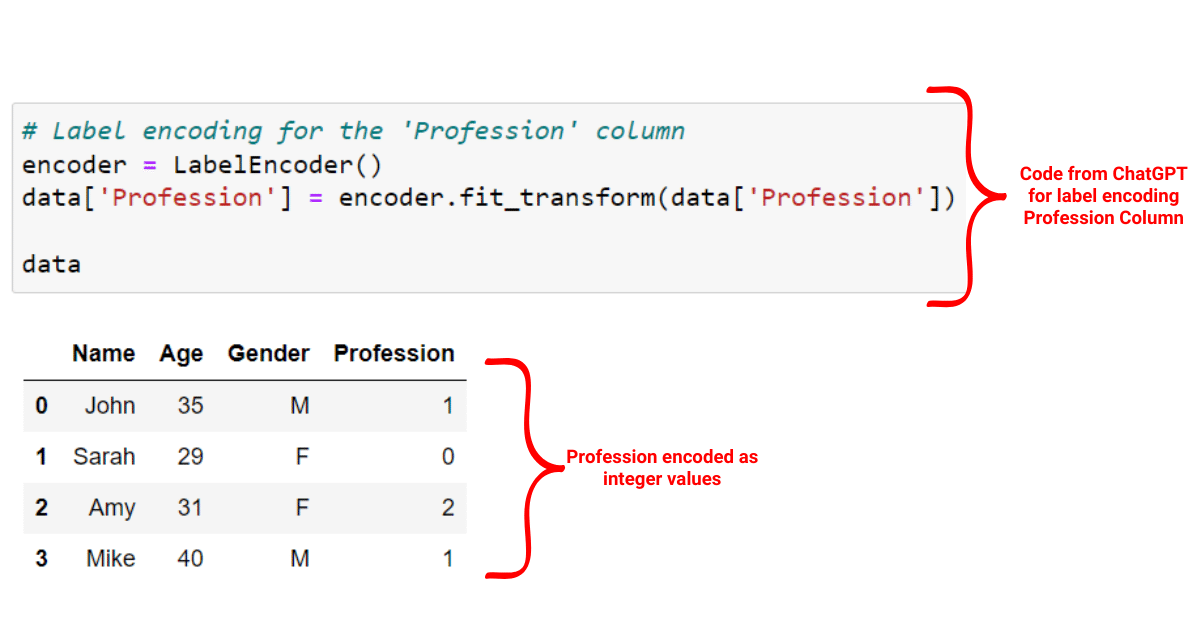
On the other hand, one-hot encoding creates binary variables for each of the Profession categories as shown in the image below:
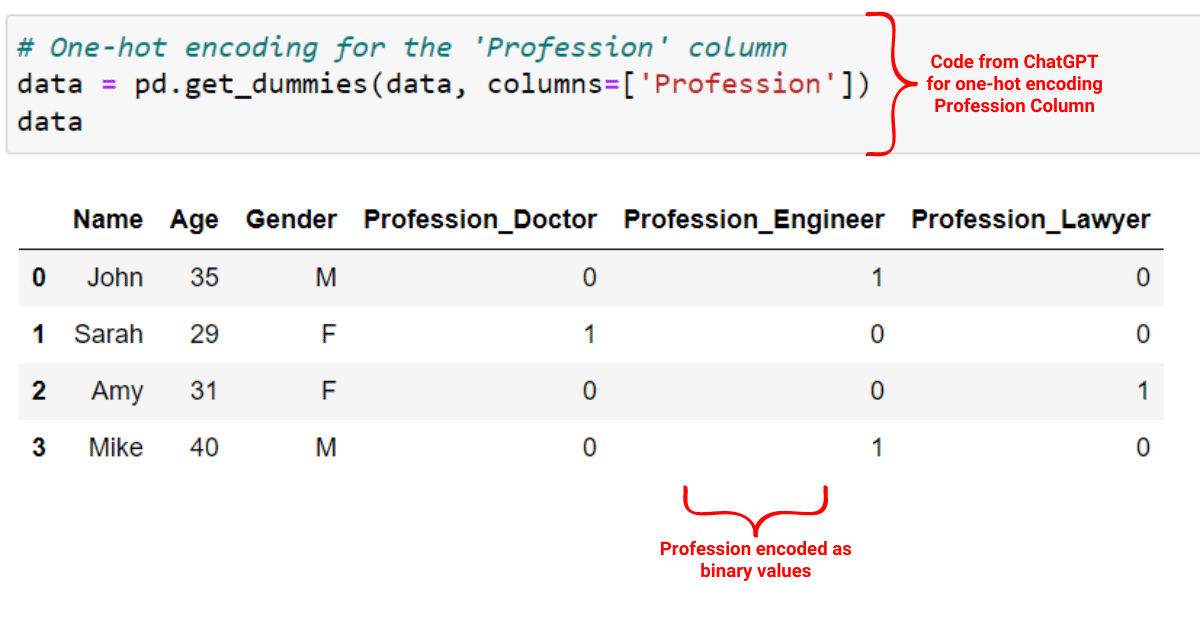
The above examples should give you an understanding of using ChatGPT along with your data science projects.
Another common step that we need to perform before implementing a machine learning model is encoding and scaling, so let’s look at how we can use ChatGPt to help a data scientist with encoding and scaling.
3. Scaling Numerical Variables
Oftentimes, when you are working with data, you might come across numbers that are too small or too large. In such cases, you’ll need to scale your numerical variables. With scaling methods, you can adjust the numerical variables to have a uniform scale.
There are two ways of scaling numerical variables:
Min-max scaling: Scales the values between 0 and 1
Standard scaling: Centers the data around the mean with a standard deviation of 1
Let’s implement the above two numerical scaling methods on a dataset.
Suppose the “Age” column is our numerical variable for standard scaling and min-max scaling. You can use the following prompt to generate code for the above two scaling techniques.
Act as a software developer and extend the previous Python script by adding standard scaling and min-max scaling for the ‘Age’ column in the DataFrame. Use sklearn’s StandardScaler for standard scaling and MinMaxScaler for min-max scaling. Apply standard scaling first, followed by min-max scaling.
ChatGPT will give you a code similar to the following:
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# Standard scaling for the 'Age' column
std_scaler = StandardScaler()
data['Age'] = std_scaler.fit_transform(data[['Age']])
# Min-max scaling for the 'Age' column
min_max_scaler = MinMaxScaler()
data['Age'] = min_max_scaler.fit_transform(data[['Age']])Let’s implement this code on our describe dataset. First, we’ll scale our age variable with the standard scaling technique as shown below:
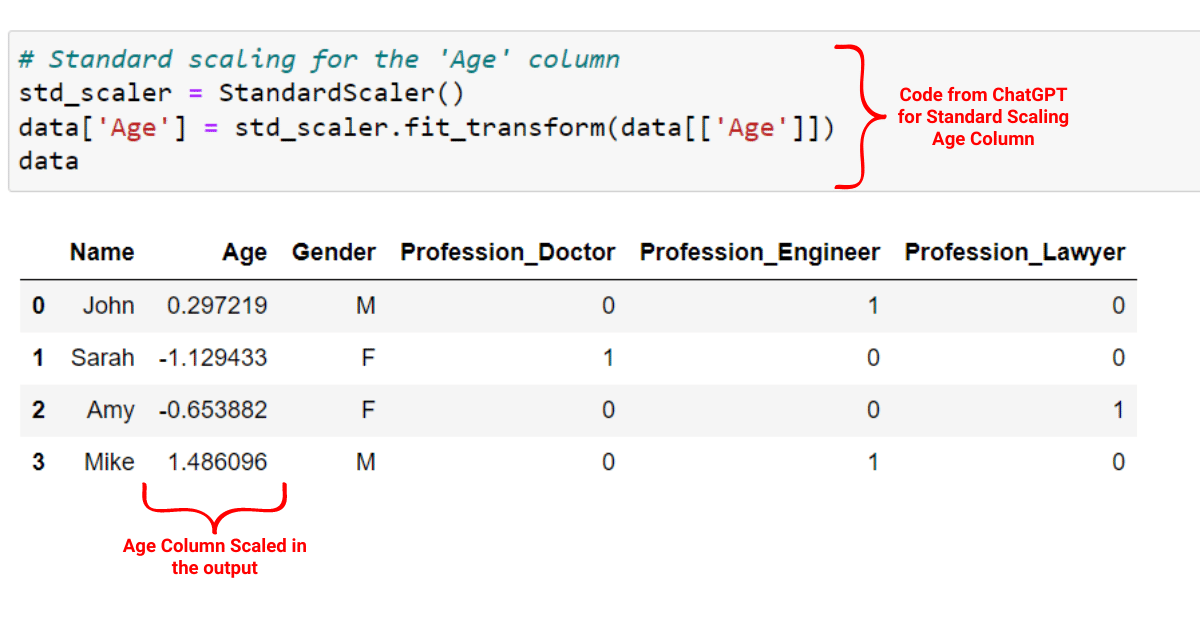
Next, we’ll use the min-max scaling technique to scale our age variable with the code given by ChatGPT:
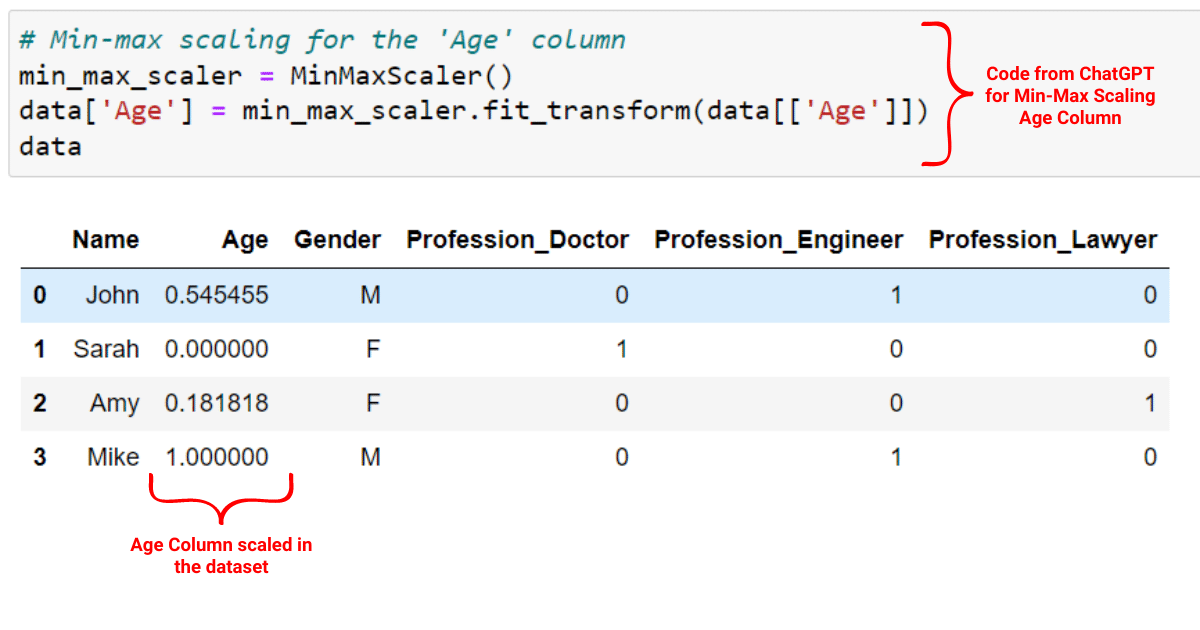
Now, your data is ready for feature engineering. You can now explore the relationships between the variables in your dataset to create new features and improve model performance.
2. Using ChatGPT for Data Analysis and Visualization
As a data scientist, it’s crucial to begin your data science projects by performing Exploratory Data Analysis (EDA). In this stage, you’ll dive deep into your data, cleaning and preprocessing it to prepare for further analysis.
Utilizing a language model like ChatGPT can significantly boost your productivity during EDA. With ChatGPT, you can automate basic tasks such as creating a pandas DataFrame or generating summary statistics. This allows you to focus on more complex tasks.
During the data exploration phase, a data scientist could use ChatGPT to generate code snippets for various tasks, such as:
Loading the data into a pandas DataFrame
Visualizing missing values and handling them appropriately
Creating histograms, scatterplots, or other types of plots to explore variable distributions and relationships
Let’s look at examples of each of the above tasks!
We’ll do EDA on a dataset with the following columns: Age, Salary, Experience, Job_Role
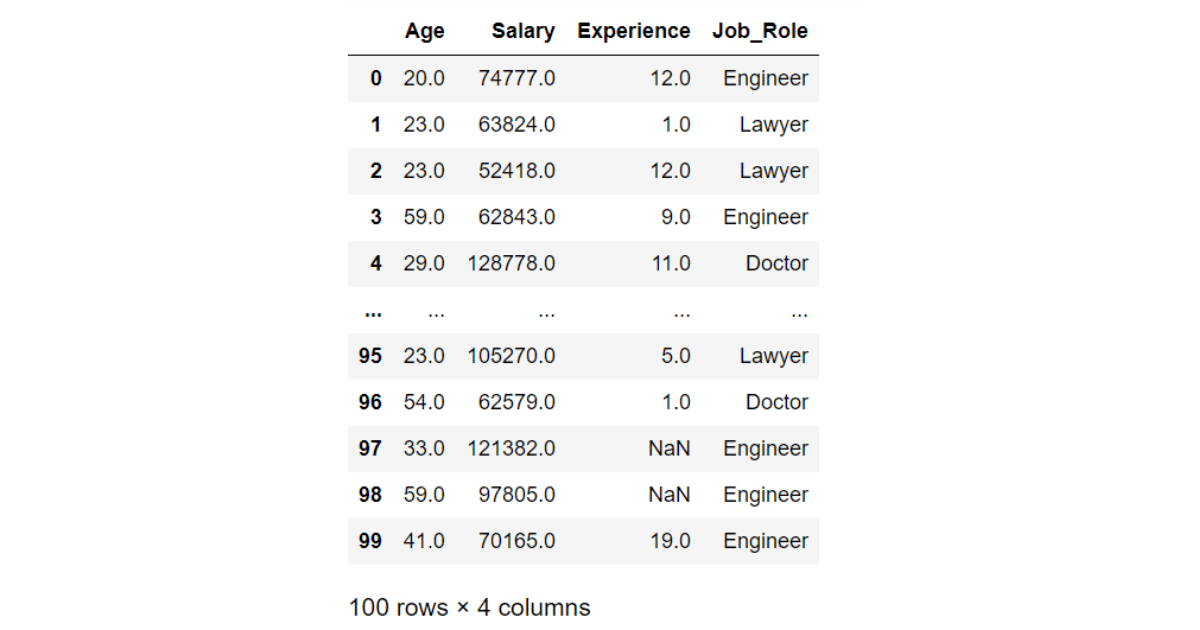
Suppose you have a dataset that you want to load into your pandas DataFrame. You can use the following dataset prompt:
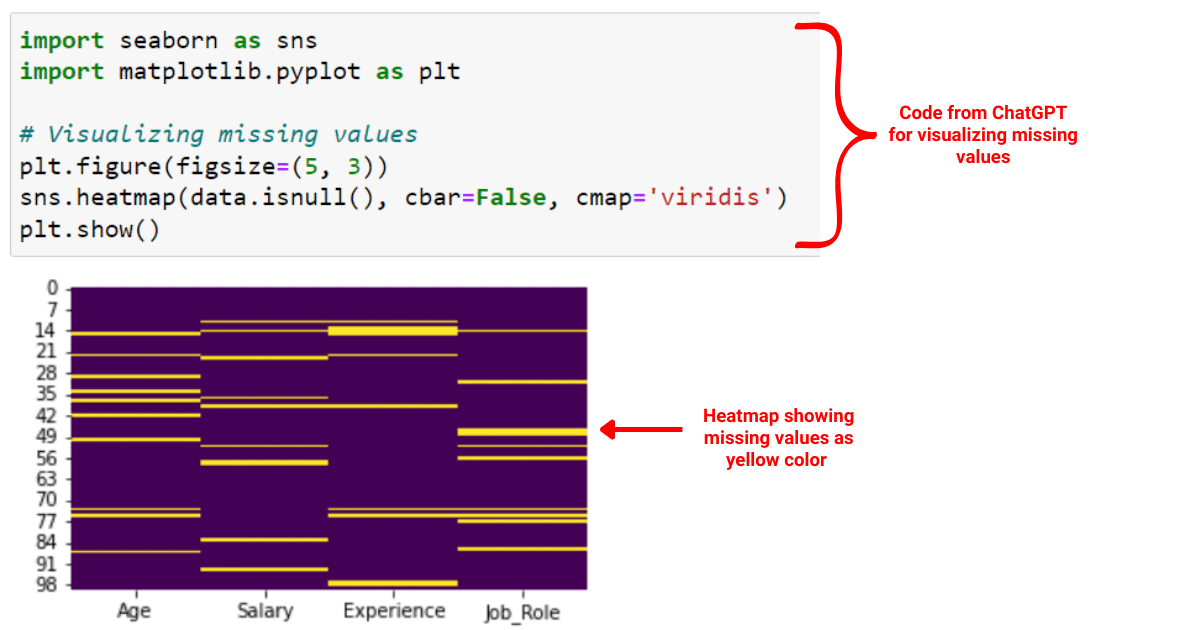
Act as a data scientist and write Python code to visualize the missing values in the dataset using a heatmap from the Seaborn library. After that, handle the missing values by replacing them with the mean value for numerical columns and the most frequent category for categorical columns.
ChatGPT will give you a code similar to the following:
import seaborn as sns
import matplotlib.pyplot as plt
# Visualizing missing values
plt.figure(figsize=(12, 8))
sns.heatmap(data.isnull(), cbar=False, cmap='viridis')
plt.show()
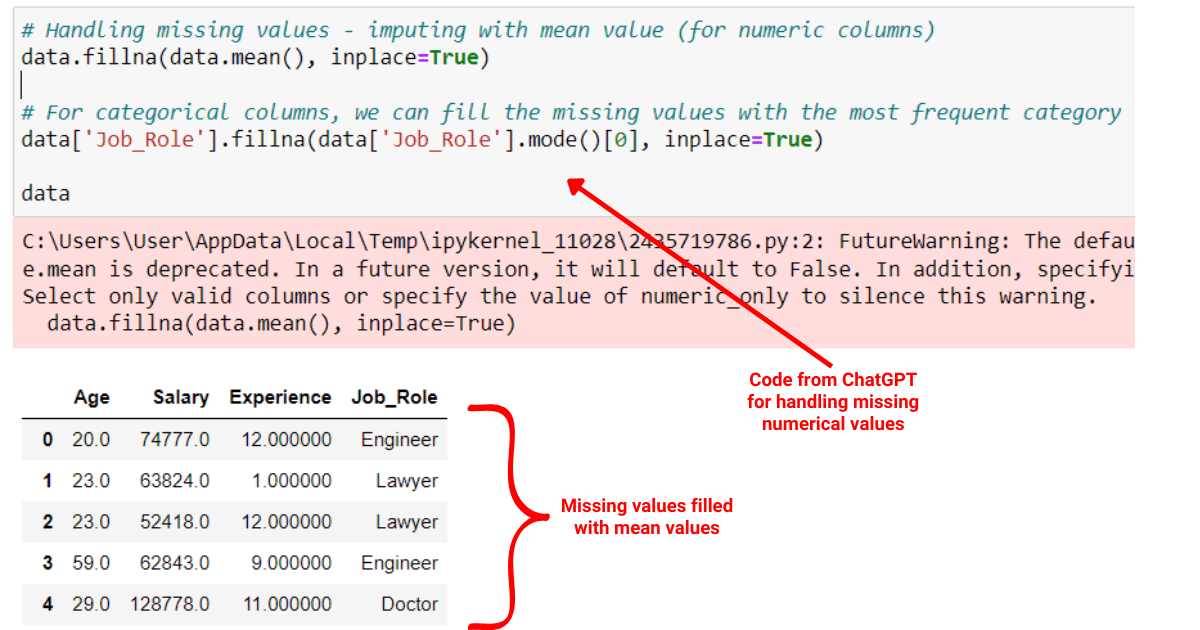
# Handling missing values - imputing with mean value (for numeric columns)
data.fillna(data.mean(), inplace=True)
# For categorical columns, we can fill the missing values with the most frequent category
data['Job_Role'].fillna(data['Job_Role'].mode()[0], inplace=True)The following pandas code will first visualize the missing values in your dataset as shown below:
Then it will handle the missing values by imputing them with the mean values.
To learn more about handling missing values in Python, check out the following video:
To make visualize data, you can give the following prompt to ChatGPT:
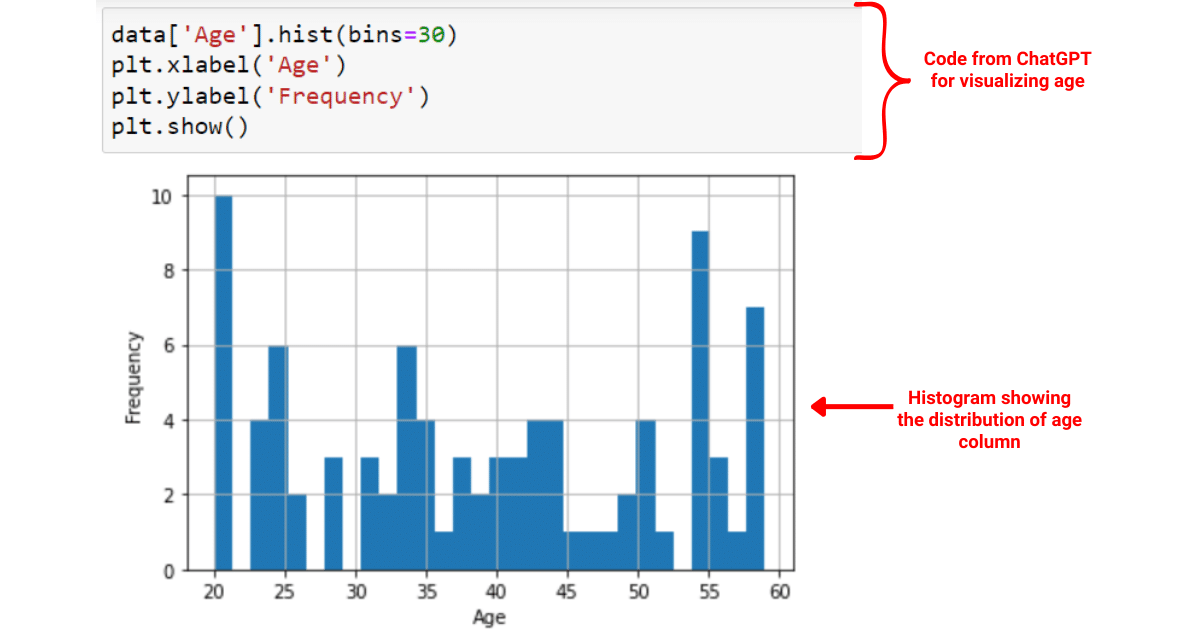
Act as a data scientist and write a Python script to create a histogram for the ‘Age’ column in the dataset using matplotlib
ChatGPT will give you code similar to the following:
data['Age'].hist(bins=30)
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()The above code will visualize the age column in the dataset.
Final Thoughts
ChatGPT offers great value for data scientists. Firstly, it saves time. As we’ve seen, it can quickly generate code for tasks like data loading, handling missing values, or creating plots. This means you can focus on the bigger picture of your project, not just the coding details.
Secondly, it’s easy to use. The key to getting the most out of ChatGPT is learning to ask it the right questions through prompt engineering. As you practice, you’ll get better at framing your prompts, making ChatGPT an even more useful tool.
ChatGPT is a powerful assistant in your data science journey, but you should not completely rely on ChatGPT for doing your projects. Instead, use it as an assistant and learn side by side with it so that your skill set grows with time!








