
Pandas is a widely used Python library for data manipulation and analysis. One essential functionality that pandas can provide you is the ability to modify the structure of a dataset. Specifically, dropping indexes in a DataFrame is a crucial operation when working with datasets. It allows you to remove unwanted rows or columns from the data.
To drop an index with pandas, you can use the .drop() and .reset_index() methods. The .drop() method allows you to remove specific rows or columns. On the other hand, the .reset_index() method allows you to remove the index and reset it to the default RangeIndex.

In this article, we’ll discuss the use of these methods to drop indexes in pandas DataFrames. We’ll go through various examples to demonstrate how to effectively manipulate a dataset’s structure to suit different analytical needs. Through these examples, you’ll gain a deeper understanding of how the pandas library can be utilized for data manipulation.

Let’s get into it!
Understanding Pandas Drop Index
Before we dive into dropping index with pandas, it’s very important that you have an understanding of what a pandas DataFrame is. Furthermore, you should also be familiar with the concept of indexes and columns in a pandas DataFrame.

In this section, we’ll cover the basics of a pandas DataFrame, index, and columns. We’ll then look at an example of dropping an index using pandas.
1. What is a Pandas Dataframe?
Pandas is an open-source Python library that provides high-performance data manipulation and analysis tools. One of its key data structures is the DataFrame.
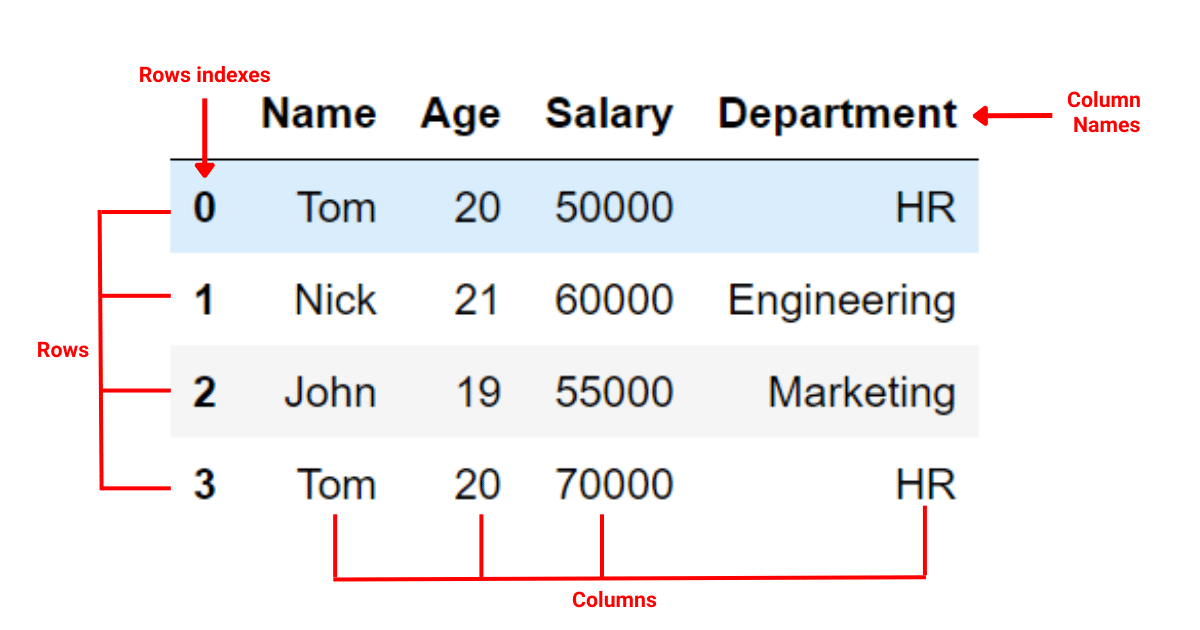
A pandas DataFrame is a two-dimensional data structure with labeled axes (rows and columns). You can think of a DataFrame as a Pythonic object representation of an SQL table or an Excel spreadsheet.
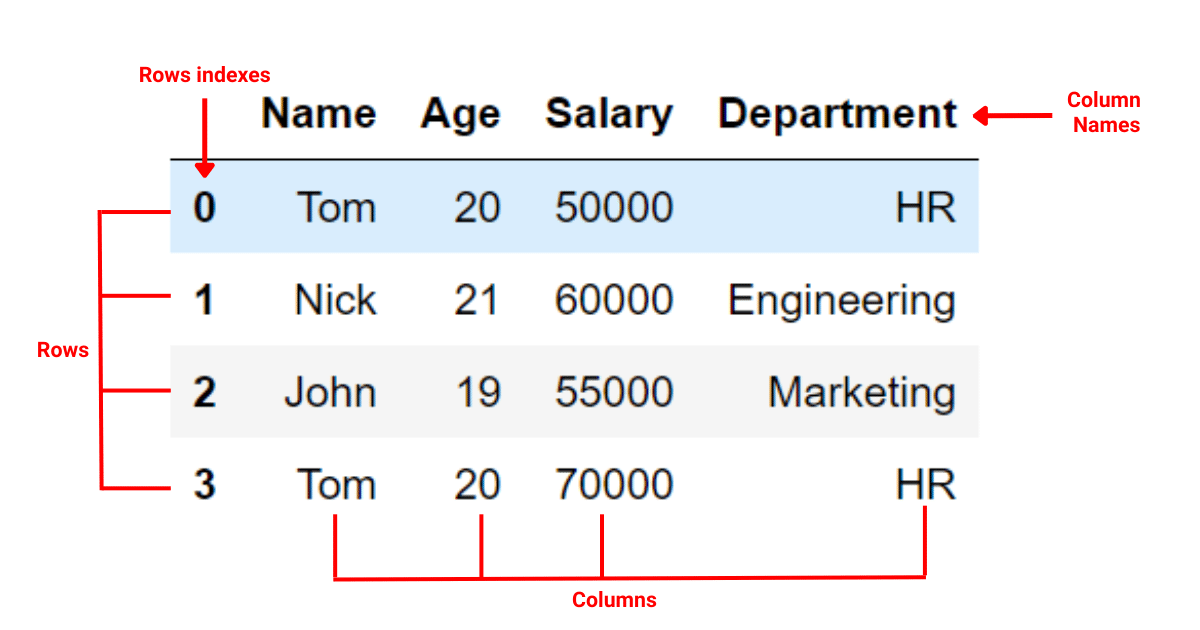
The following is a typical pandas DataFrame:

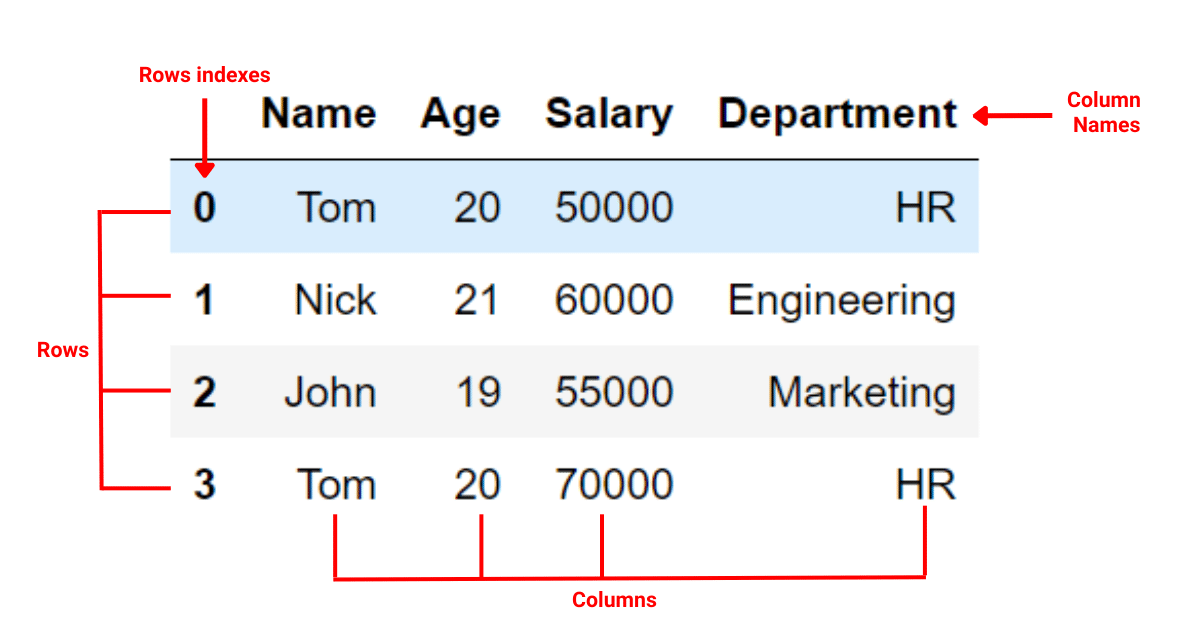
2. What Are Indexes and Columns?
In a pandas DataFrame, the Index serves as an ‘address’ for data points. It provides a means to access and organize data across the DataFrame. It could be either the default integers sequence assigned by pandas or a user-defined custom index.
Columns are the variables that host different types of data in the DataFrame. Each column is essentially a series of data. It can hold diverse data types such as integers, floats, or strings. The label of the column, commonly referred to as the column name, identifies this series of data.
In a pandas DataFrame, data manipulation often involves working with the row labels (indices) or column labels.
Some common operations you can perform with a multi-index DataFrame include selecting, renaming, and dropping rows or columns based on their labels.
3. How to Drop Index Column with Pandas
In pandas, you can use the DataFrame method reset_index() to drop and reset the index.
Suppose we have the following DataFrame:
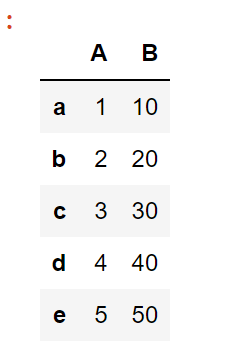
To drop the index column, we can use the following code:
df.reset_index(drop=True)After running this code, you’ll get the below example:
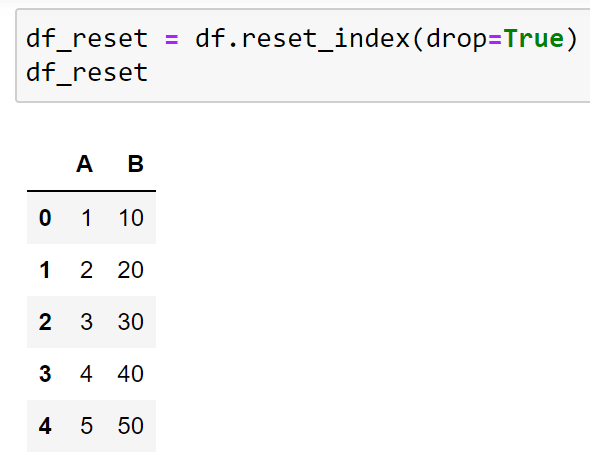
In the output, you can see that the index is dropped and replaced with the original index values.
You can also use the drop method in pandas to remove specified labels from rows or columns.
The syntax for this method is:
DataFrame.drop(labels=None, *, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')Following are the key parameters of the drop method:
labels: The labels to remove. It can be either rows or columns depending on the axis parameter.
axis: Determines whether to drop from rows (0 or ‘index’) or columns (1 or ‘columns’).
index: An alternative to specifying axis=0. Allows indicating the row labels to remove.
columns: An alternative to specifying axis=1. Allows indicating the column labels to remove.
inplace: If set to True, the operation will be performed in place, meaning that the original DataFrame will be modified. If False (default), a new DataFrame with the specified labels removed will be returned.
errors: Controls how to handle missing labels. If ‘raise’ (default), an error will be raised when labels are not found. If ‘coerce’, missing labels will be silently ignored.
Suppose we have the following DataFrame:
We would like to drop the row with index 1. To do this using the drop method, you can write the following code, starting with import pandas:
import pandas as pd
# Drop row with index 1
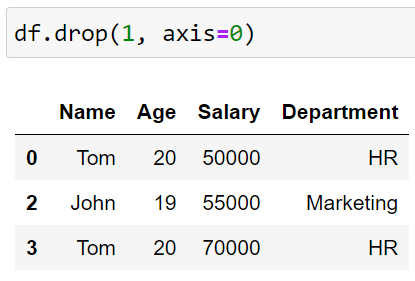
df.drop(1, axis=0)The axis=0 argument of the drop function tells the interpreter that we are performing a row-wise operation. The second argument 1 is the row index. It tells the interpreter to drop the row with index 1.

After the above operation, we get the following DataFrame:
Now, let’s say we would like to drop the column with Age as the column header from our DataFrame. To achieve this, we can write the following code:
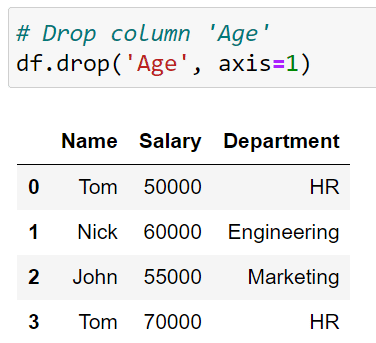
# Drop column 'Age'
df.drop('Age', axis=1)The argument axis=1 tells the interpreter that we are performing a column-wise operation. The argument ‘Age’ tells the interpreter to drop the column with the name ‘Age’.
After running the above code, you’ll get the following DataFrame:
How to Drop Multiple Rows and Columns
The above example demonstrates dropping a single row or column. What if you’d like to drop multiple rows or columns?
To achieve this, we’ll use the same code with some slight changes. Instead of using a single value, we can provide a list of arguments to the drop function to remove multiple rows and columns at once.
Let’s say I want to drop the first 2 rows in our DataFrame. To achieve this, we can use the following code:
# Dropping first 2 rows by index
df = df.drop([0, 1], axis=0)In this code, we are telling the interpreter to drop rows 0 and 1. The output of this code is given below:
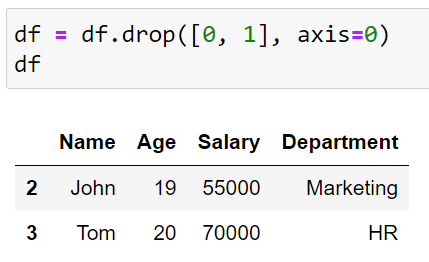
You can see that rows 0 and 1 are no longer in the DataFrame.
Let’s also drop the Department and the Salary columns. To do this, we can use the following code:
# Dropping columns by name
df = df.drop(['Salary', 'Department'], axis=1)In this Python script, we are asking the interpreter to drop the columns with Salary and Department as the column headers. The output of this code is given below:
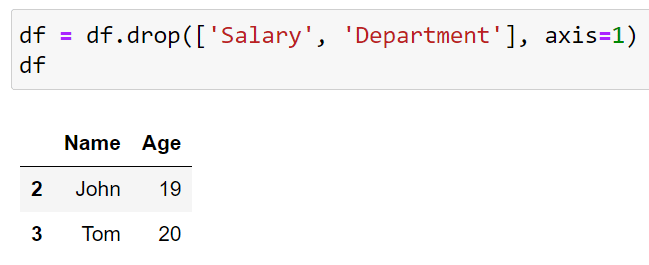
This is our final DataFrame. In total, we deleted two rows and two columns from our DataFrame using the drop method.
To learn more about MultiIndex in pandas, check out the following video:
How to Drop Rows and Columns with Inplace
In the previous example, you can see that we first make changes to the DataFrame and then save it as a new DataFrame. However, this is not an efficient way of dropping rows and columns.
Another alternative to dropping rows and columns is to set the inplace argument of the drop function to True.
By setting the inplace parameter to True, you can permanently modify the DataFrame without having to reassign it.
This is useful when dealing with large DataFrames, as it can save memory by avoiding the creation of a new DataFrame.
The following is an example of dropping rows and columns with inplace:
# Dropping rows by index inplace
df.drop(labels=[0, 1], axis=0, inplace=True)
# Dropping columns by name inplace
df.drop(['Salary', 'Department'], axis=1, inplace=True)
The output of the above code is given below:
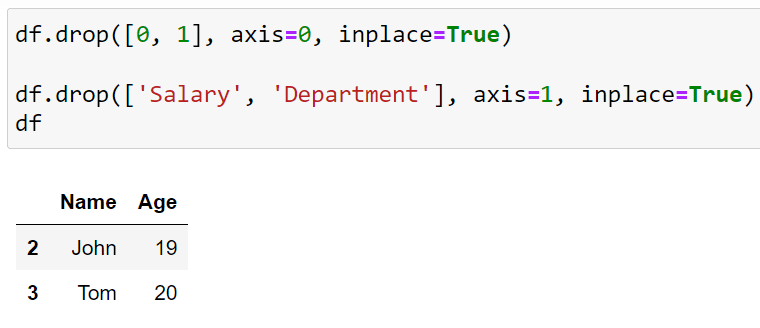
Here, you can see that we are not creating any new DataFrame but making changes to the original one.

How to Work With Indexes in Pandas
In this section, we’ll discuss how to work with indexes in a pandas DataFrame. We’ll cover the following two sub-sections:
Set and reset Index
ID and index Column
1. How to Set and Reset Index
One important aspect of working with pandas is understanding how to set and reset index columns. An index is a key identifier for each row, and there are instances when you might want to change it.
Setting a New Index
To set a new index, you can use the set_index() method. The syntax of set_index is given below:
df.set_index('column_name', inplace=True)The argument inplace=True here means we are making changes to the existing DataFrame.
To demonstrate this, we’ll use the following DataFrame:
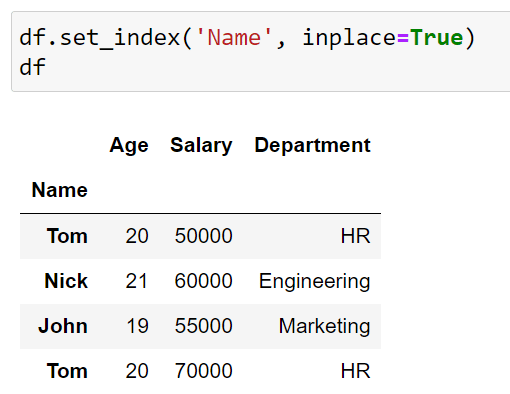
Let’s say we would like to make the Name column the index of our DataFrame. To achieve this, we can use the following code:
df.set_index('Name', inplace=True)This Python script will make Name the index of our DataFrame. The output of this code is given below:
Resetting the Index values
To reset the index to its default format (i.e., a RangeIndex from 0 to the length of the DataFrame minus 1), you can use the reset_index() method.
The syntax of reset_index() is given below:
df.reset_index(drop=True, inplace=True)By setting drop=True, the current index column will be removed, while inplace=True ensures the changes are applied directly to the DataFrame without creating a new one.
When we apply this code to the previous DataFrame, we get the following output:
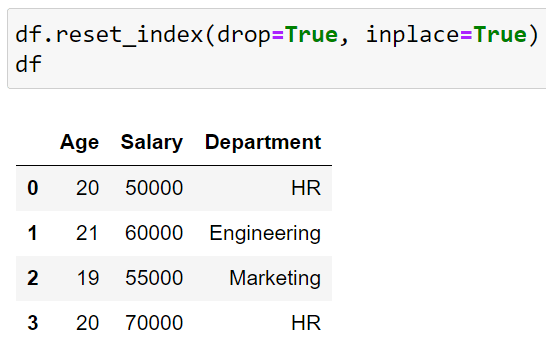
You can see that the Name, which was previously our index, is reset to the default values.
2. Further Operations With Index Column
When you’re importing a DataFrame from, say, a CSV file, you can use the index_col parameter to specify a column to use as your index.
The syntax of index_col is given below:
df = pd.read_csv('data.csv', index_col='column_name')Furthermore, if you want to export a DataFrame without the index column, you can set the index parameter to False.
The syntax for this method is given below:
df.to_csv('output.csv', index=False)Now that you understand the method for dropping index, let’s look at how you can handle errors when using the drop function in the next section.
How to Handle Errors When Using Drop Function in Pandas
In this section, we’ll explore how to handle errors and special cases when using pandas’ drop function to remove index columns from a DataFrame.
Specifically, we’ll discuss the following:
Handling KeyError
Working with duplicate rows
1. How to Handle KeyError
When using the drop function in pandas, you may encounter a KeyError if the specified index or column is not found in the DataFrame.
To prevent this error from occurring, you can use the errors parameter. The errors parameter has two options: ‘raise’ and ‘ignore’. By default, it is set to ‘raise’, which means that a KeyError will be raised if the specified index or column is not found.
However, you can set it to ‘ignore’ if you want to suppress the error and continue executing the code.
Suppose we have the following DataFrameLet’s try dropping a row which does not exist in the DataFrame and see what happens:
# Attempt to drop a non-existent index, will raise KeyError
# df.drop(5, inplace=True)The Python script will give the following error:
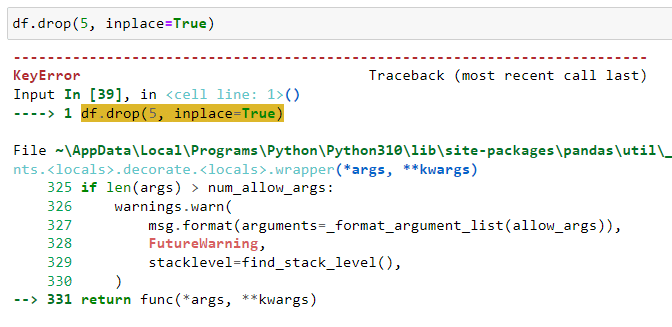
To handle such errors, make sure you are referring to rows that are present in the dataset.
2. How to Work With Duplicate Rows
When cleaning data, an important task is to look for duplicates and remove them.
Dealing with duplicate rows in a DataFrame can add complexity when using the drop function.
If you want to drop rows based on duplicated index values, you can use the duplicated function, and then use boolean indexing to select only the non-duplicated rows.
Suppose we have the following DataFrame:
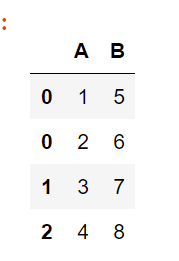
You can see that we have duplicate indexes in our dataset. To remove the duplicates, first, we’ll identify the duplicate values with the following code:
# Find duplicated index values
duplicated_rows = df.index.duplicated(keep='first')After this, we’ll select only the non-duplicated rows and store them in the previous DataFrame with the following code:
# Select only non-duplicated rows
df = df[~duplicated_rows]The final output is given below:
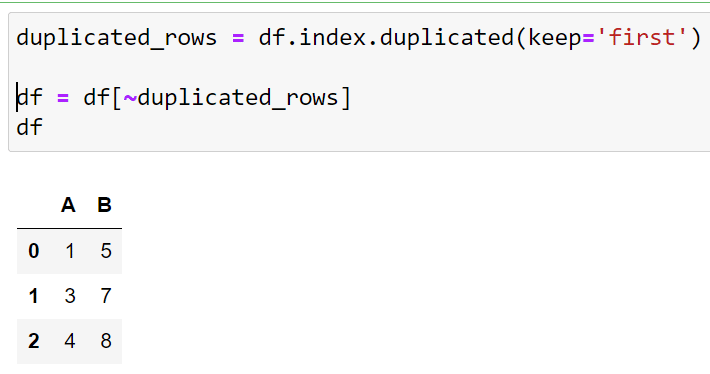
The final output no longer has duplicate rows.
Final Thoughts
As you continue your data science and analytics journey, understanding how to manipulate and manage data is a skill that will prove the most important.
Mastering operations like dropping indexes in pandas is a key part of this. Knowing how to reset or drop an index is a stepping stone toward cleaning, transforming, and deriving valuable insights from your data.
By learning how to drop indexes, you’ll be able to reshape your DataFrames more effectively. You’ll also be able to create cleaner datasets that are easier to read and analyze. Additionally, resetting indexes can be crucial when merging or concatenating multiple DataFrames, where index conflicts could arise.
The ability to drop indexes enables you to have greater control and flexibility over your datasets!


