
In this tutorial, you will learn how to resample time series data using Pandas. You can watch the full video of this tutorial at the bottom of this blog.
What is this idea of resampling? This is related to time series data and what we’ll do is change the frequency at which that data is reported. For example, changing yearly value into monthly or weekly, or changing hourly data into daily. In short, we are changing the level in the hierarchy.
This can be used for a number of reasons such as getting more reliable trends, sample sizes, and seasonality. At some reports, it will make more sense if we use some level of the hierarchy versus another.

Additionally, resampling can help if you have different data sources and you need to perform joining of time series data. This will also help when dealing with a mismatch in the hierarchy.

To break this down further, we have downsampling and upsampling.
Downsampling is to decrease the frequency of reporting. It can be things like converting from a second to an hour in order to have fewer values or downsampling month to quarter.
On the other hand, upsampling is to increase the frequency of reporting from the month level down to the day. We will have more examples of this later.

How To Resample Time Series Data Using Pandas
How are we going to do this in Pandas?
First of all, we will change the index to our time series data column. Then, we can upsample using interpolation, which will fill in the values, and we can downsample to roll up by aggregating the values.


Let’s go over to Jupyter Notebook Python and check this out with Pandas.
To start with, we will use Pandas by typing in import pandas as pd, followed by import seaborn as sns to visualize it, and import matplotlib.pyplot as plt to customize the Seaborn visualization.
The next thing to do is to get the data from vega_datasets import data. It’s a nice place to get sample sources. Also, we are going to get sp = data.sp500 ( ) and sp.head ( ) library.
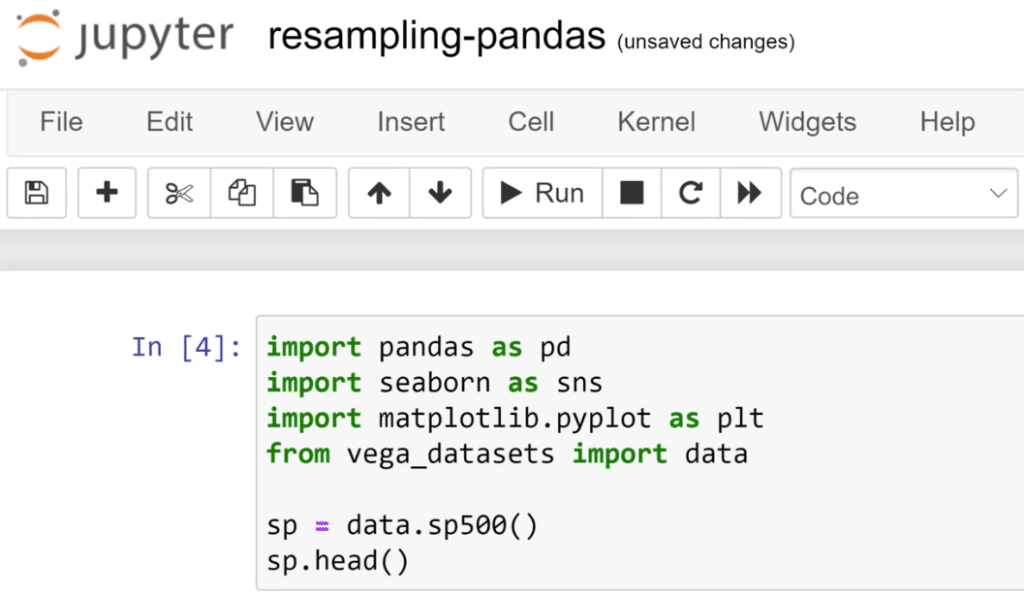
Here’s our data so far. We have the daily returns and price for each day.
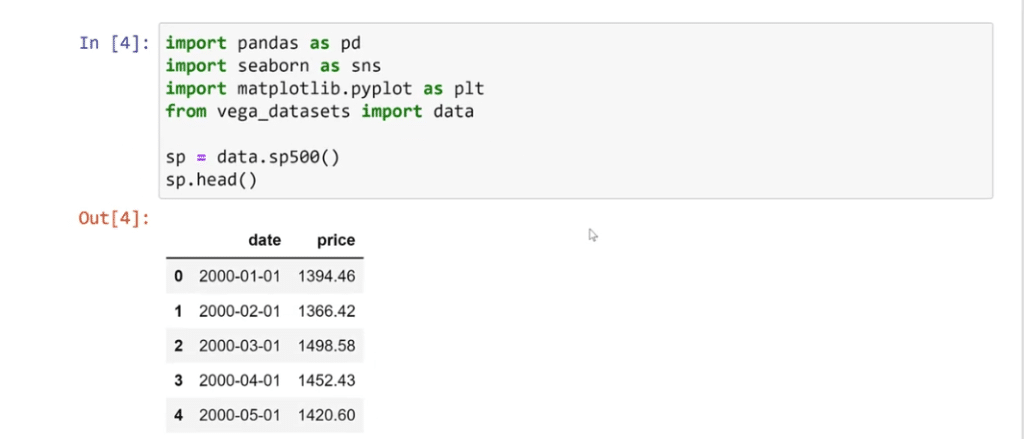
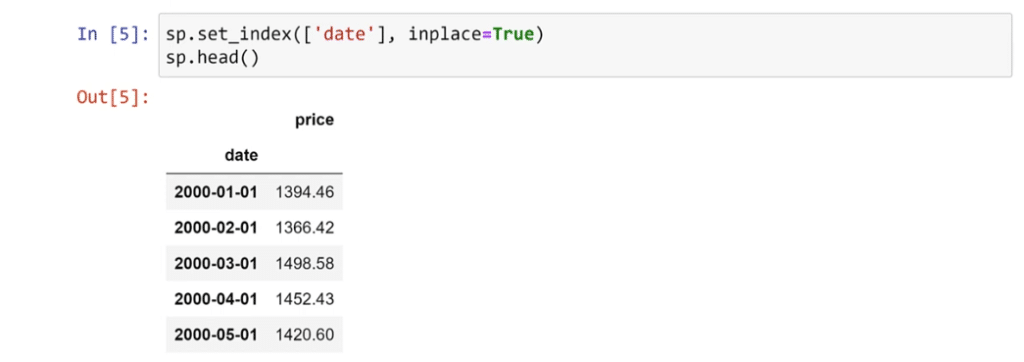
To set the index to date column, type in sp.set_index([‘date’], inplace=True) then call sp.head again.
Using Upsampling To Get Values
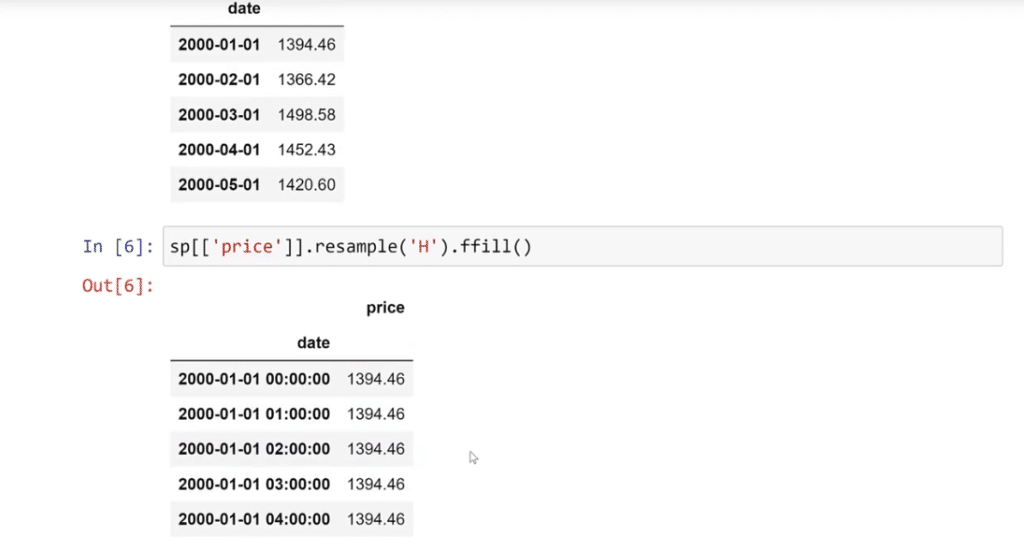
Then, to have more values, let’s use upsampling. Since we have the data for every day, we can go down to the hour by using the simplest function which is sp [[‘price’]]. resample (‘H’).ffill ( ), then run it. H stands for hour, M for month, D for the day, and so on. You can learn more about this in the Pandas documentation.
As we can see, on January 1st at midnight, the price is 1394.46, same as the succeeding hours from 1:00 AM to 4:00 AM. Another example is on January 2nd, where the closing price is 1366.42.
There are other ways to do this even if the value is not available at the hour level. Also, there are more sophisticated ways than just doing a forward fill. For our example, what we did is the basic way to do upsampling interpolation.
Next, let’s go to downsampling by typing in avg_month = sp [[‘price]].resample (‘M’).mean ( ), then avg_month.head ( ) and run it to check.
As illustrated, we can see the last day of each month and the average price. We can decrease the samples to have fewer values, or what we call downsizing.
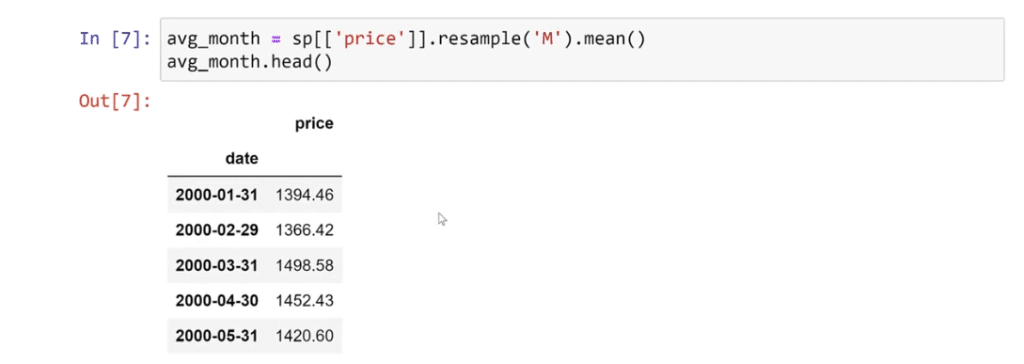
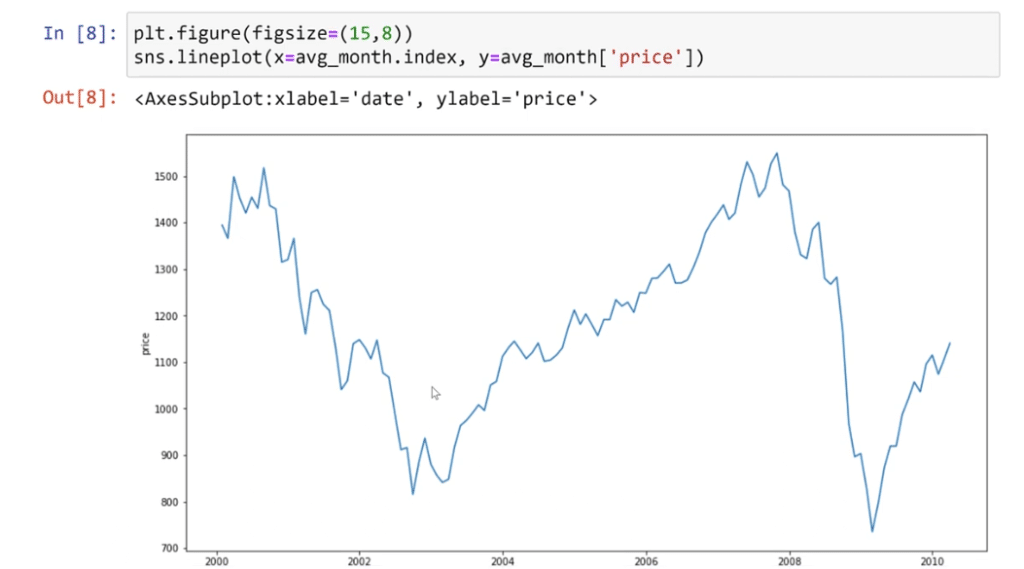
To visualize this, let’s type re-plot the dimensions that is drawn. Then, followed by sns.lineplot. The line plot works better with a longer X-axis, while the Y value is the average monthly price.
To see the average price for the month plotted, let’s run this.
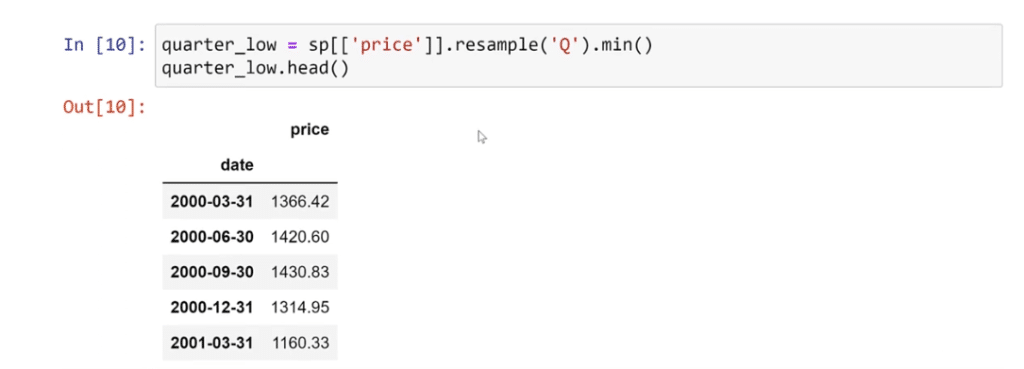
Again, there are a lot of different ways we can do this. For example, if we want to know the lowest price per quarter, all we need to do is type in quarter_low, then quarter_low.head to run it.
So there, we can now see the quarterly lowest value found in each quarter. This is how you do a resample.
***** Related Links *****
Handling Missing Data In Python Using Interpolation Method
MultiIndex In Pandas For Multi-level Or Hierarchical Data
Datasets In Pandas With ProfileReport | Python In Power BI

Conclusion
To cap it off, Pandas is really built for resampling and time series data. If you are working on time series data and have different granularities, resampling can be very helpful.
In addition, make sure to read the Pandas documentation on the resample method to learn a lot of different ways to do this. We looked at the basic ones, but you can do things such as bi-weekly, the last working day of the month, and more options for resampling.
All the best,
George Mount
[youtube https://www.https://www.youtube.com/watch?v=IyHZ3VOd_KE&w=784&h=441]


