
Interpolation is a method for generating points between given points. In this tutorial, I’m going to show how you can use Interpolation in handling missing data in Python. You can watch the full video of this tutorial at the bottom of this blog.
In Python, Interpolation is a technique mostly used to impute missing values in the data frame or series while preprocessing data. I’ll demonstrate how you can use this method to estimate missing data points in your data using Python in Power BI.

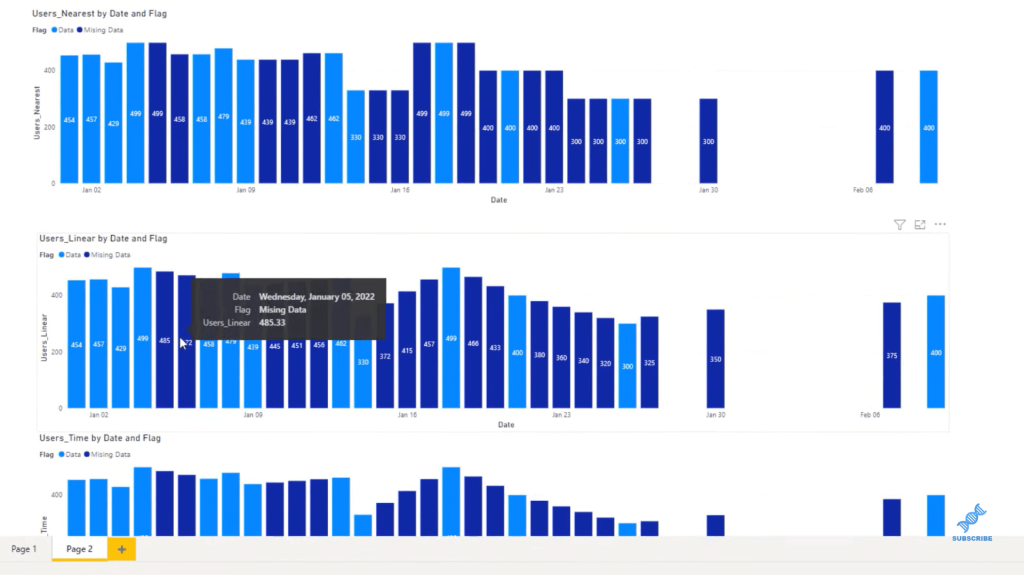
If we look at our original data here below that’s represented in the top graph, we can see that there are a lot of holes or missing data that we cannot graph because there’s nothing there. But in the bottom graph, we can see that we’ve done some estimation to figure out what that data could look like. The actual data is represented in light blue, while the Interpolated data is in dark blue.
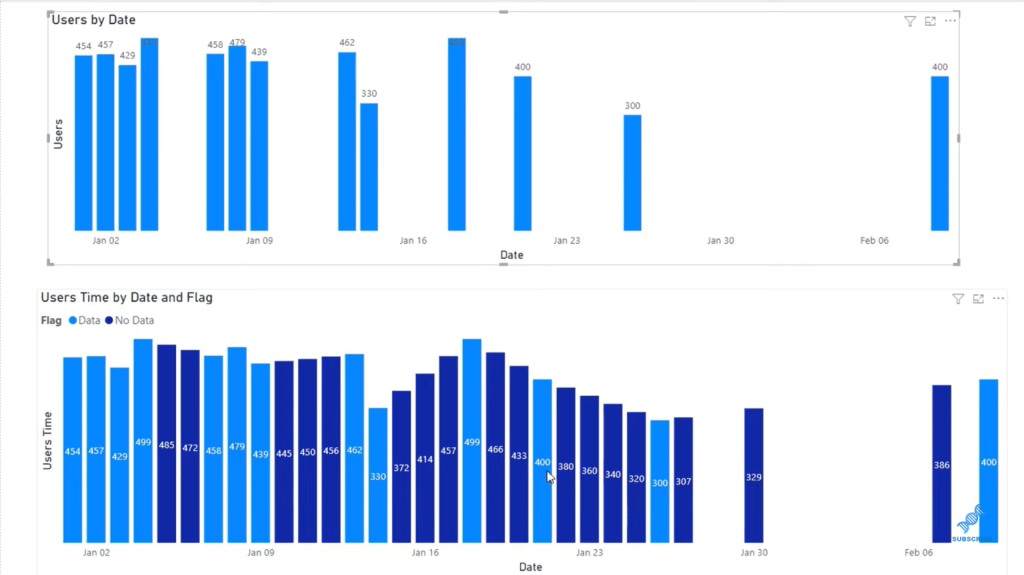
There are a couple different types of estimation we’re going to do. We’re going to do a Linear Interpolation, a Nearest Interpolation, and then a Weighted Time Interpolation. Each of those is going to give us slightly different results.
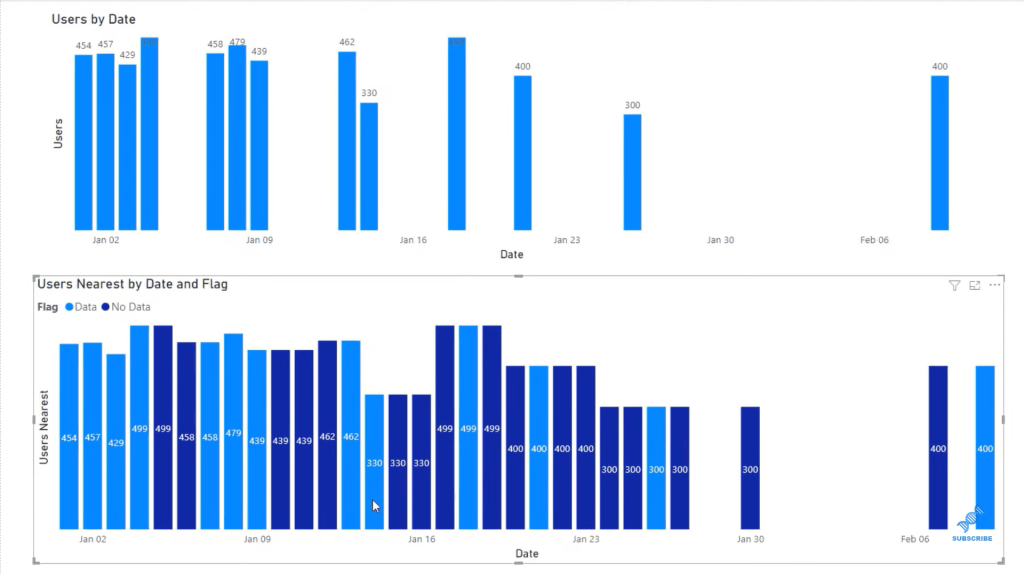
The example above is using the Weighted Time Interpolation, which looks almost the same as the Linear Interpolation, with the exception that this is weighted based on the days. Linear estimated the data based on the slope between these two data points. Nearest Interpolation has a flatter type of estimation, as you can see below, where we looked at the nearest value and were able to estimate what exists between those two.
So, let’s jump over to a Jupyter notebook and bring that in.
How To Use Interpolation In Handling Missing Data In Python
You could use the Script Editor to script everything out, but it’s easier. You get more feedback in your Jupyter notebook. So, let’s document what we’re doing. When we copy and paste this over to our Python Script Editor, it’ll be very clean and clear.
Let’s import the libraries that we want, and we’re going to import Pandas and save them as a variable PD. We’re going to import Numpy and save it as the variable NP. Pandas is a data manipulation library, while Numpy allows us to do data manipulation as well and gives us some linear algebra.

We want to bring in our dataset, and we’re going to save that as a variable df. And we are going to just use the Pandas variable (pd) and use the read.csv function. Then, we’re going to copy and paste where that file exists on our PC. Mine is in my working directory, so all I need to do is write machines.csv and encapsulate that in parenthesis.
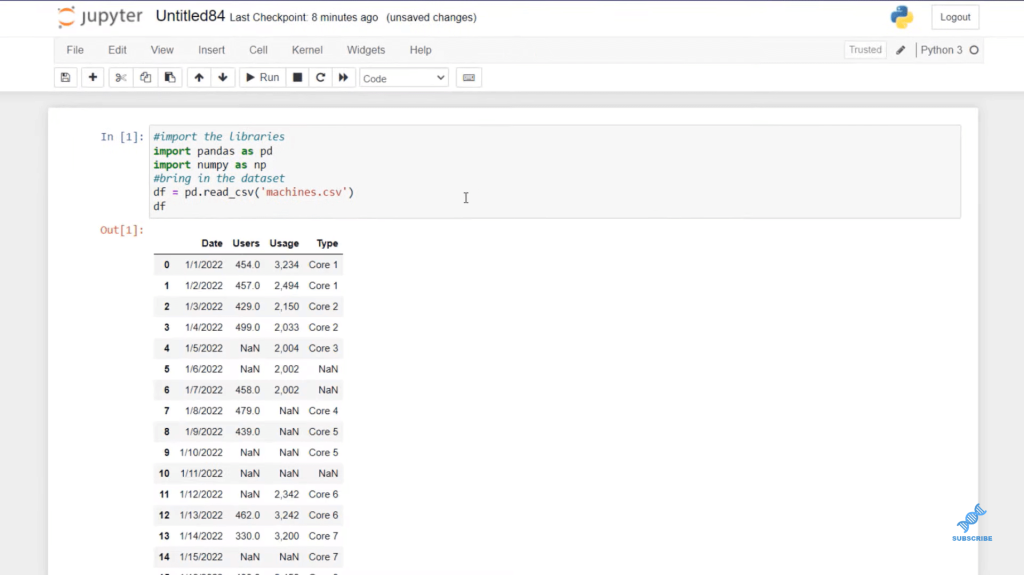
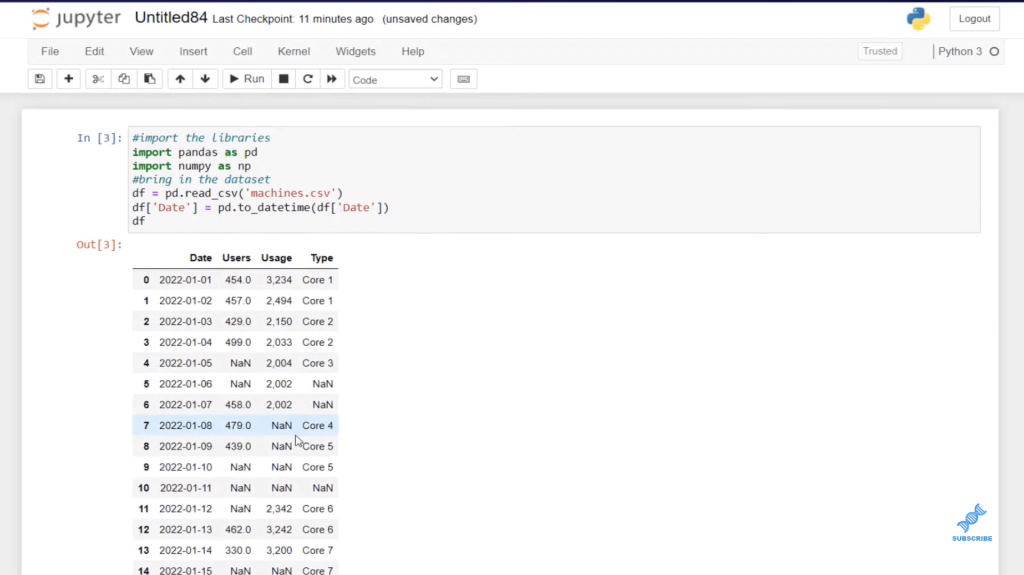
And let’s take a look at our dataset just by using the variable df. You can see this goes from the 1st of 2022, all the way to the 25th. It’s consecutive days all the way to the 15th, and then there are four days missing on the 19th, and then there are three days missing when we get to the 22nd, and two days missing on the 25th.
The days that are skipped are not missing data. That’s just not data in our dataset. What we’re going to deal with is missing data, which you see represented with these NaN or no values.
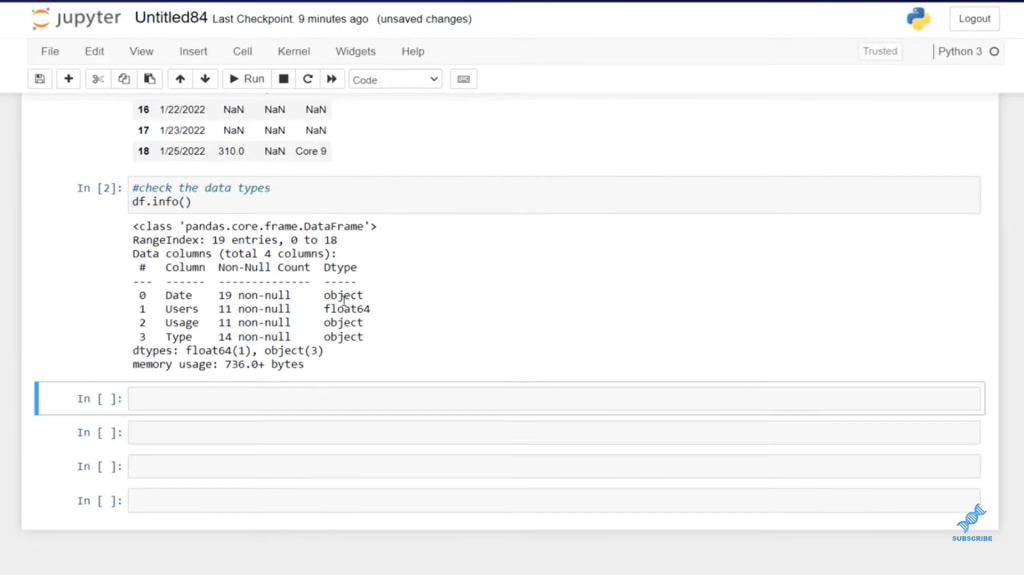
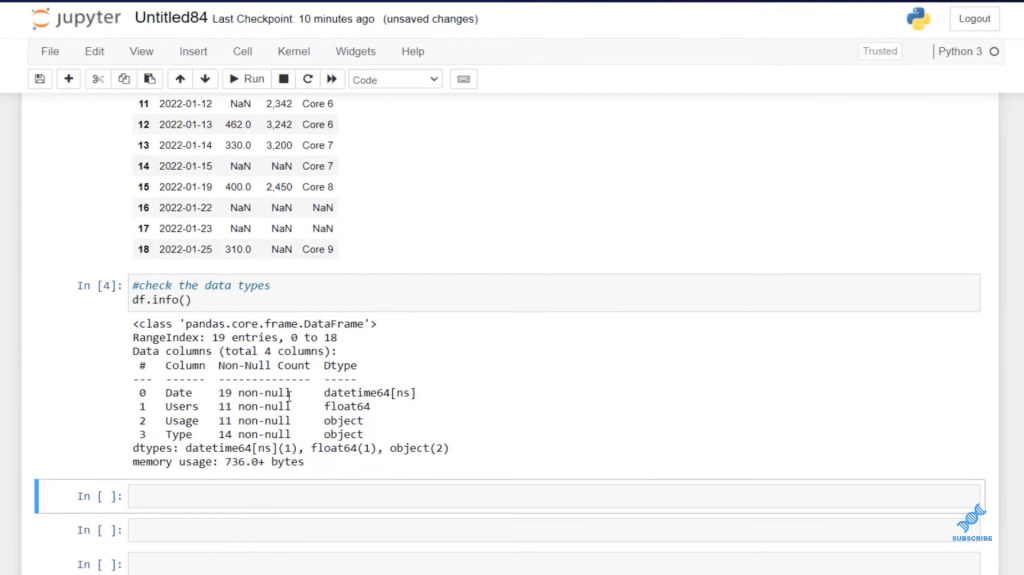
Now that we have our dataset in, let’s use our different types of interpretation and save them as different columns. We can see that we have object, which is represented by a text, and we have a float as well.
I’m going to isolate the Date column by using bracket notation. Then, I’m going to use equals to assign this. I’m going to use pd variable, and then I’m just using the function to_datetime. And then, I’ll close off that function with the parenthesis and add in the Date column.
We can see that now we have the Date as the proper data type.
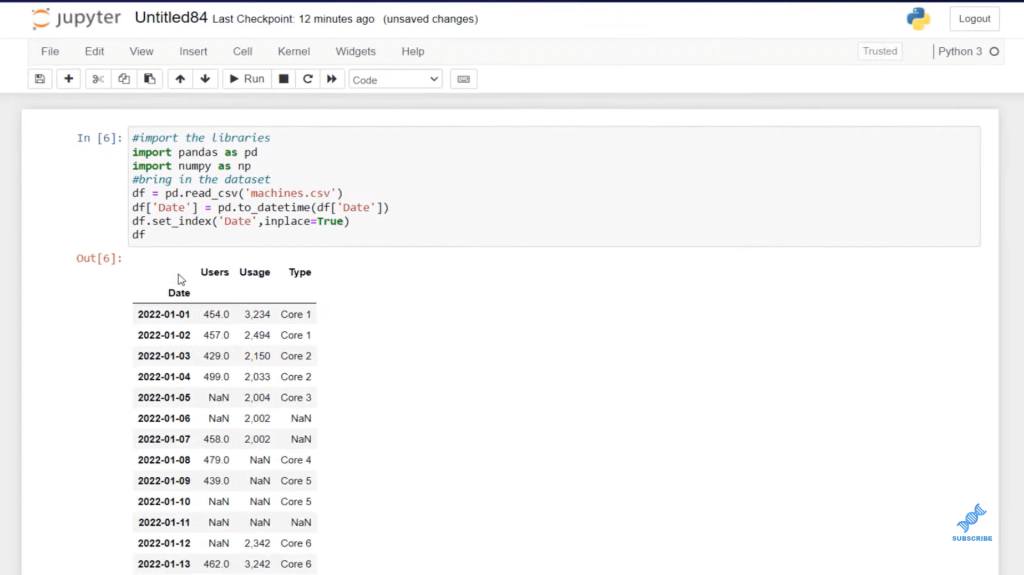
We have an index here, which is indicated by numbers 1 to 18. When we do Linear, it will be using these numbers to create a linear connection between the existing data points. But we also want to be able to use a Time-weighted Interpolation, which looks at time and gives us the results based on the actual days. We want to set the Date column as the index, so we can utilize it.
I’m going to use my data frame (df) variable, and do set_index. We need to pass in a parameter called inplace to make sure it’s permanently passed in. So, I’m going to use inplace equals true, and then I’m going to hit shift and enter. And with that, you can see that the numerical index disappeared, and we have a Datetime index.
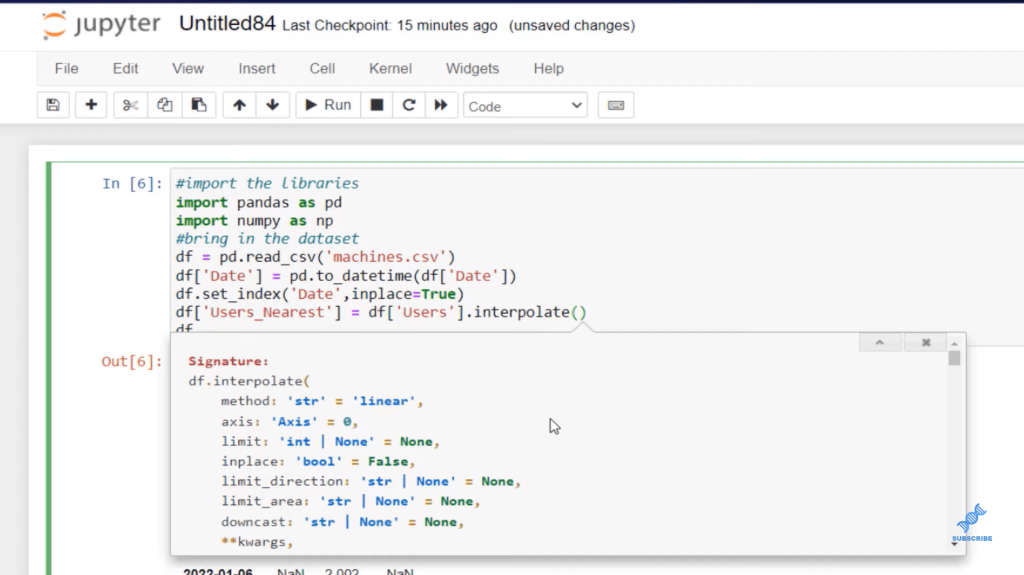
Now, we can start building those columns that we want. Let’s build a column where we are interpolating the nearest data point, which will fill these missing values with the nearest value. We want to create a column called users_nearest, and we want to assign that to a Users column.
We want to create a column called user_nearest, and we want to assign that to a user column. And now that we have that column isolated, we can use interpolate function, and we can press shift-tab to see what parameters this function takes. There are many different types of methods.
You can see that the default is linear, and if you want it to see all the different methods, there’s information within this. You can open this all the way up and there’s a lot of information here that will give you a lot of insight. But it’s always better to go down to the Pandas site and just see what all the different types of interpolations are.
Now we’re going to pass in the method that we want, and we’re going to use the Nearest Interpolation method. All we have to do is run this, and you can see that a column is created. If we look at that particular line, we can see that as a missing value. And you can see that it has been interpolated where it’s taken the nearest value and added it here. As you can see, we don’t have missing values anymore for that particular row.
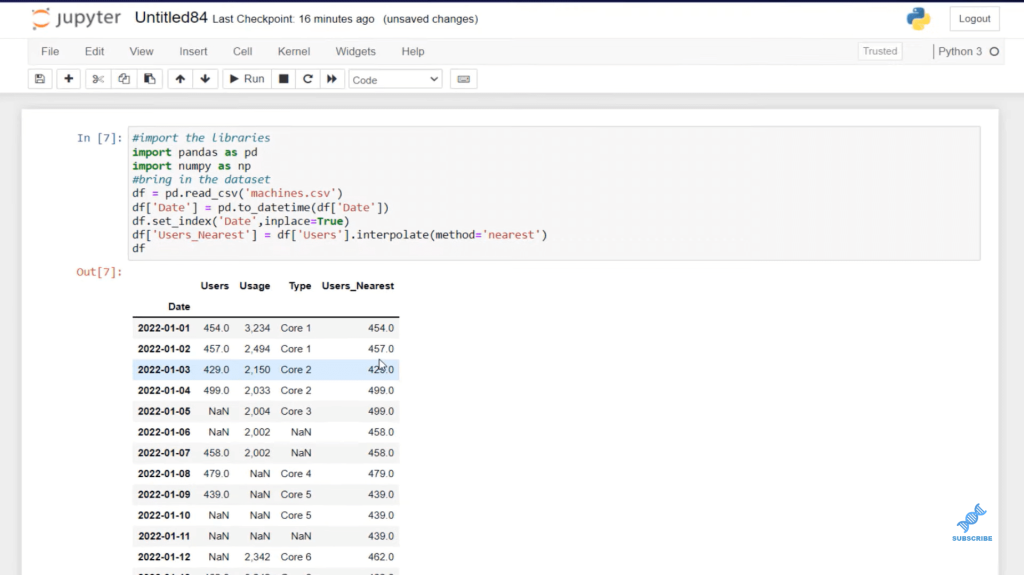
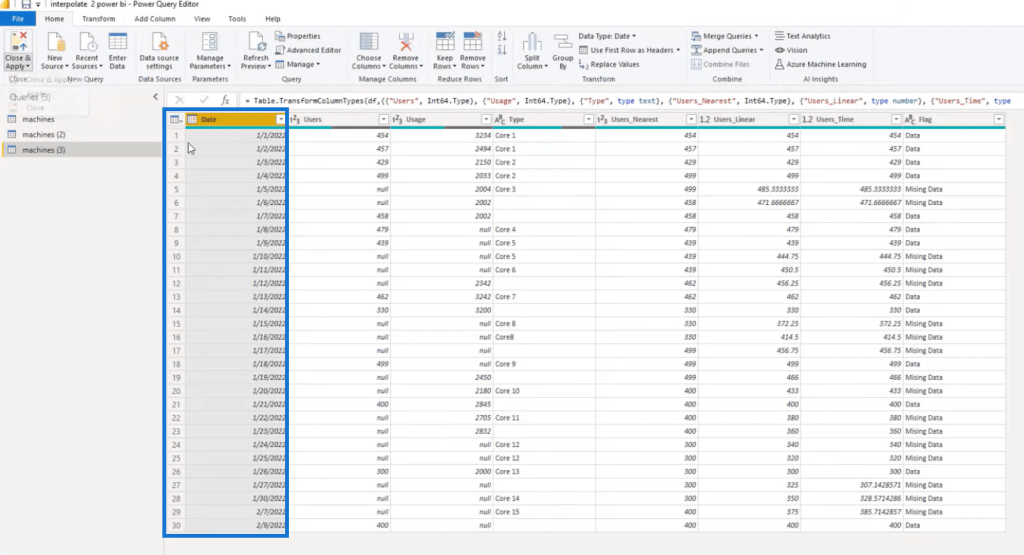
Now, let’s copy this twice, and let’s change the name of these columns to user_linear and user_time. We’ll change the methods as well to match our headings. We can shift and enter, and you can see that we have created three columns based on different types of interpolation methods.
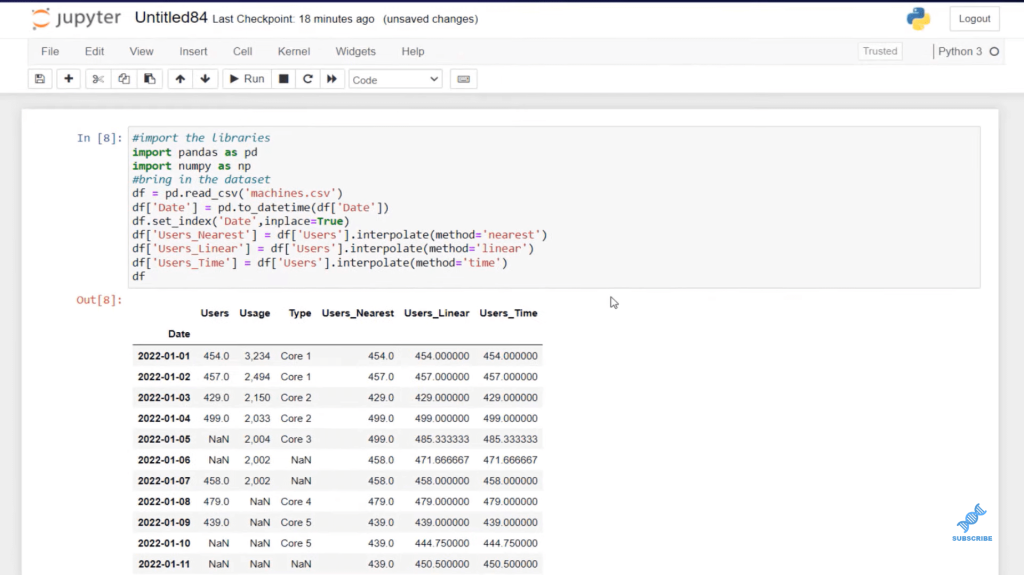
Next, I want to create one more particular column that allows us to indicate which of these are empty, like a flag in our data. We are going to use Numpy for that.
So, we’re just going to create a new column called df, and then we’re going to call it flag. We’re going to assign that with that equal sign. Then, we’re going to use np, which is our Numpy variable. And then, we’re going to use the where function, which is a conditional function. We set the condition and then we get an example for true and false. We use double equals, which is equal in Python. When it’s true, we want to say Missing Data. The other option will be Data.

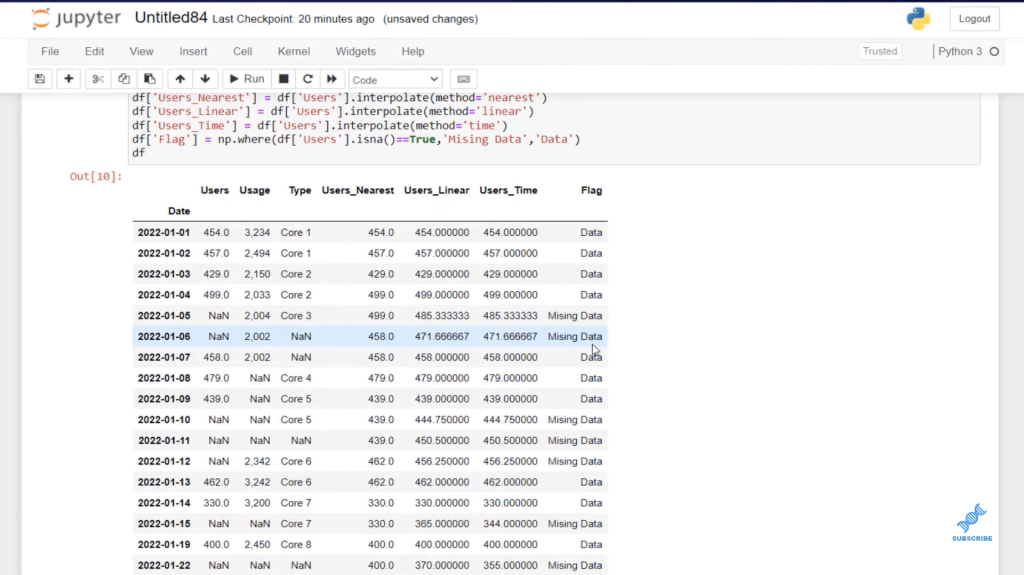
We can use that flag in our visual. Once we are in your notebook, go over to transform, and hit run Python script. Now there are a couple different steps. We need to get this to work within the Power BI environment.
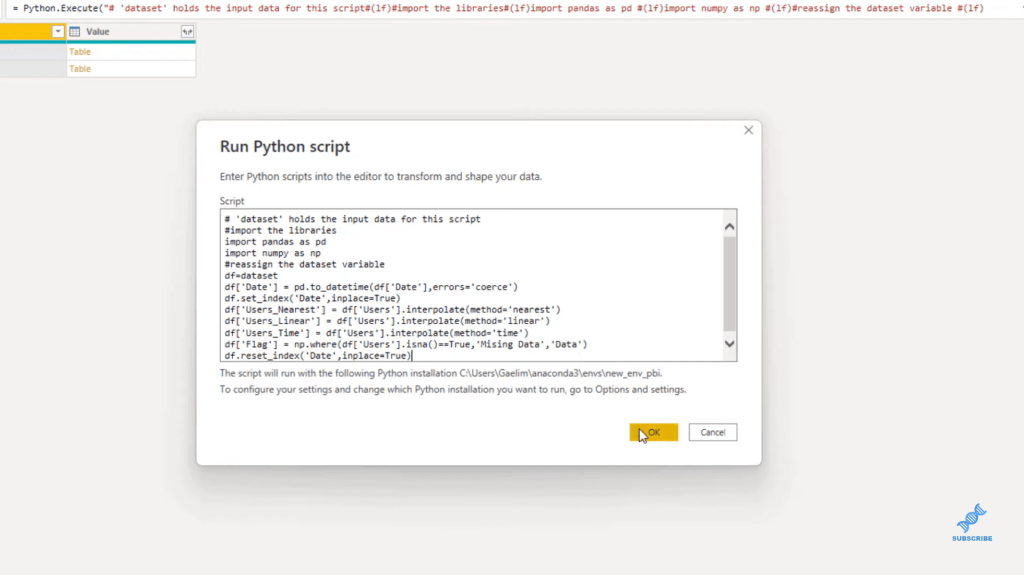
We have all our codes here and we need to add a few more steps. One, when we are dealing with date-time, we need to add an error parameter that says, if we have any errors, you can coerce or attempt to change it. So, I’m going to put here errors equal, and then parenthesis coerce. Next, we need to reassign the dataset variable as df.
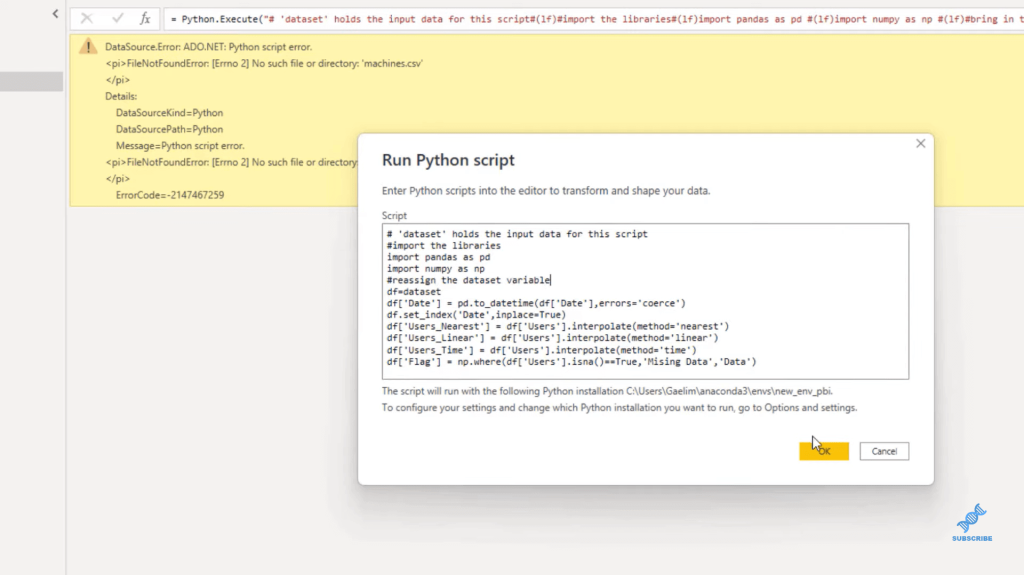
When we click OKAY, we’ll get another error, and this is what we need to do to fix this. If we go over our steps, we need to not have our date formatted. We’ll let Python work with the dates because dates are unique for each platform. The first thing that we need to do is get rid of Changed Type.
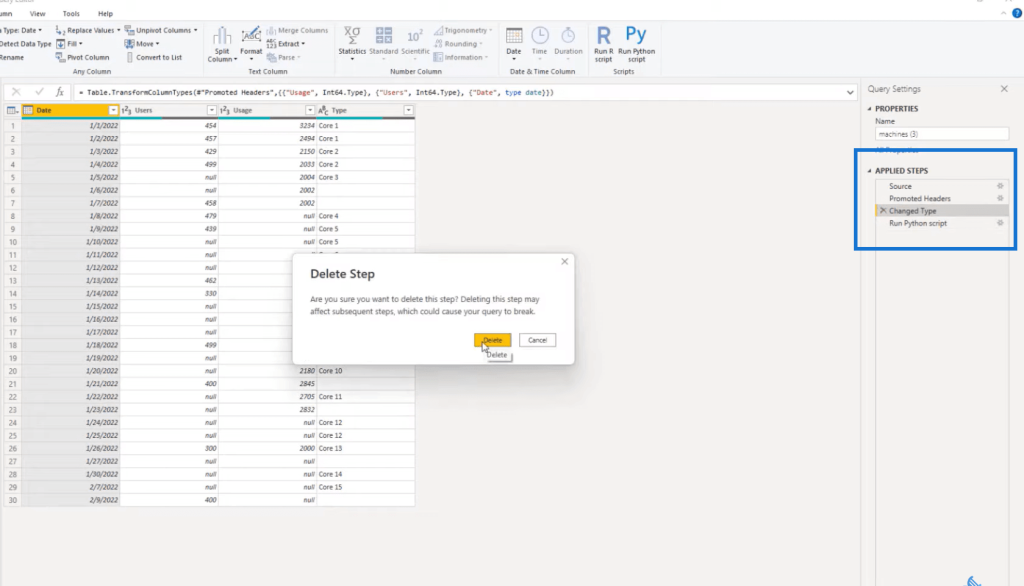
We don’t have the Date column because the date is the index. So, we go back to our Python script and then we just reset our index, df.reset_index. We say we want to reset it to the Date column bypass in that parenthesis, and then we want to do inplace = true.
And now, we have the Date and all our other data types are complete.
If we put that in a visual, this is how it looks in three different interpolation methods in handling missing data in Python.
***** Related Links *****
Currency Rates In Power BI: Handling Missing Data
Python Scripting In Power BI Data Reports
How To Load Sample Datasets In Python
Conclusion
You’ve learned in this tutorial three methods of interpolation in handling missing data in Python. We have discussed the Linear, Nearest, and Weighted Time Interpolation methods.
I hope you find this useful and apply it in your own work. You can watch the full video tutorial below for more details and check out the links below for more related content on handling missing data in Python.
All the best!
Gaelim


