
When handling SQL databases, navigating vast datasets can often prove to be a challenging task. This is where the SQL ROW_NUMBER() function comes into play. It not only simplifies data navigation but also enhances its overall structure.
The SQL ROW_NUMBER function is a window function that assigns a unique, sequential number to each row within the same partition of a result set. The numbering starts at 1 for the first row in each partition and continues without gaps as it will assign row numbers in a sequential rank number order.
In this article, we will delve deep into the ROW_NUMBER() function, an invaluable tool in the SQL toolkit.

We’ll start by understanding its basic syntax and purpose, followed by a series of practical examples that demonstrate its versatility in real-world scenarios.
Let’s dive in!
SQL Row_Number Basic Syntax

The general syntax of the SQL ROW_NUMBER() function is as follows:

Let’s break down each part of the syntax means:
- ROW_NUMBER(): This is the function we’re focusing on. It generates a unique number for each row.
- ORDER BY clause: This clause determines the order in which the rows in each partition are numbered. The numbering starts at 1 for the first row in each partition and increments by 1 for each subsequent row.
- OVER clause: This clause defines the window over which the ROW_NUMBER() function operates. In other words, it specifies the range of rows used to calculate the row number for each row in the result set.
To use the SQL ROW_NUMBER() function, you simply include it in your SELECT statement, like in the following example.
The OVER clause is used in conjunction with the ROW_NUMBER() function to assign unique rows sequentially to each record in the result set.

CREATE TABLE Orders (
OrderId INT,
CustomerId INT,
OrderDate DATE
);
INSERT INTO Orders (OrderId, CustomerId, OrderDate)
VALUES
(1, 3, '2022-01-01'),
(2, 1, '2022-02-01'),
(3, 2, '2022-03-01'),
(4, 2, '2022-04-01'),
(5, 1, '2022-05-01');
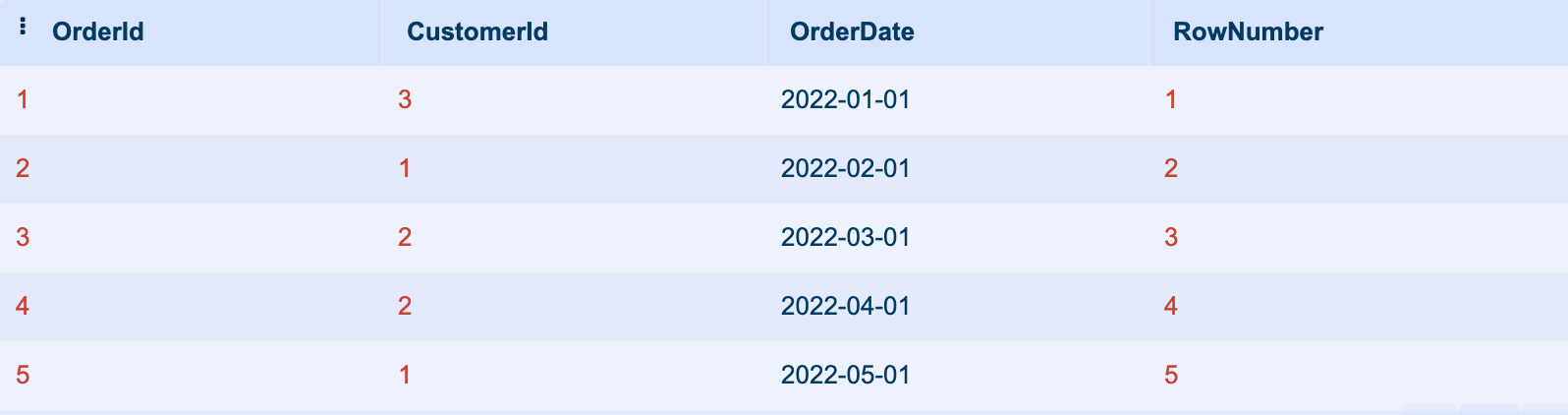
SELECT OrderId, CustomerId, OrderDate, ROW_NUMBER() OVER (ORDER BY OrderDate) AS RowNumber
FROM Orders;This given statement above will return a result set with all the columns arranged in a sequential number order from the original table. It also has an additional column named “RowNumber” that contains the row numbers as its integer data type values as this picture shows:
To give you an idea of how this works, we’ll go over some examples in the next section.
6 Examples of SQL ROW_NUMBER() Function in Use
The SQL row number does more than its simple syntax and basic usage than you think.
This window function operates on a set of rows and treats them as a window or group, making it possible to perform calculations across these related rows.
In this section, we’ll go over 6 examples illustrating the ROW_NUMBER() function in action.
1. Assigning Unique IDs to Rows
Sometimes, data does not have a unique identifier. In such cases, you can use ROW_NUMBER() to assign a unique ID to all subsequent rows:
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS RowNumber, *
FROM Orders;This is handy in scenarios where you need to uniquely identify each record, but your data doesn’t have a unique ID.
2. Pagination with ROW_NUMBER()
When dealing with large datasets, it may not be efficient to display all the data at once. ROW_NUMBER() can be used to split the data into smaller, more manageable chunks or pages.
By assigning each row a unique number and using the BETWEEN keyword, you can easily fetch a specific range of rows, which is especially useful when displaying large amounts of data in smaller, more manageable chunks.
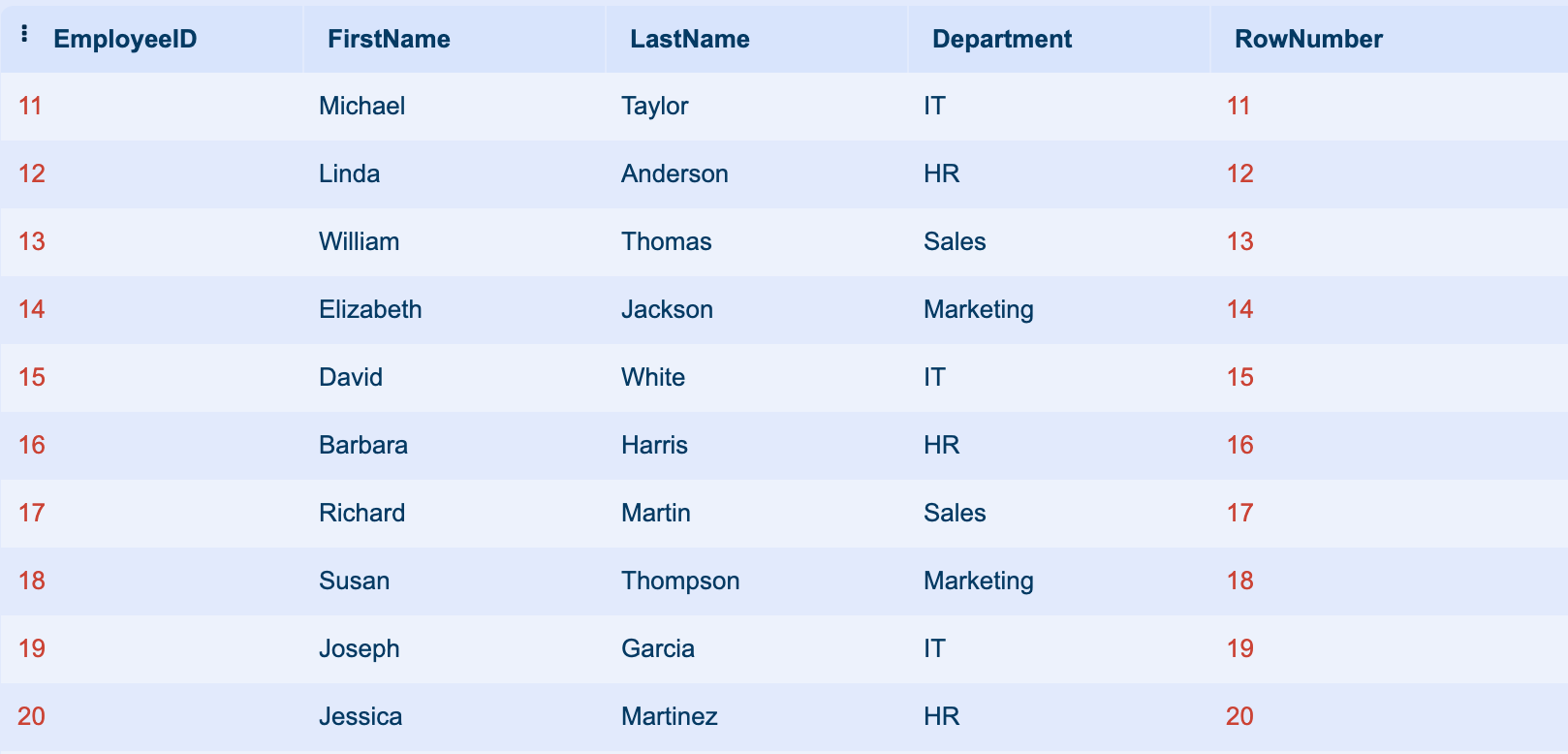
Using ROW_NUMBER() for pagination is a common approach. Let’s assume we have a table called Employees and we want to retrieve the second page of results, with each page containing 10 records:

This script first creates an Employees table and then inserts 20 records into it. The final query uses ROW_NUMBER() to implement pagination and fetches the second page of results, i.e., employees 11 to 20.
3. Ranking with ROW_NUMBER()
If you need to rank items within a specific category (like ranking salespeople by their sales), ROW_NUMBER() can be used to assign a separate rank number to each item based on some criteria.
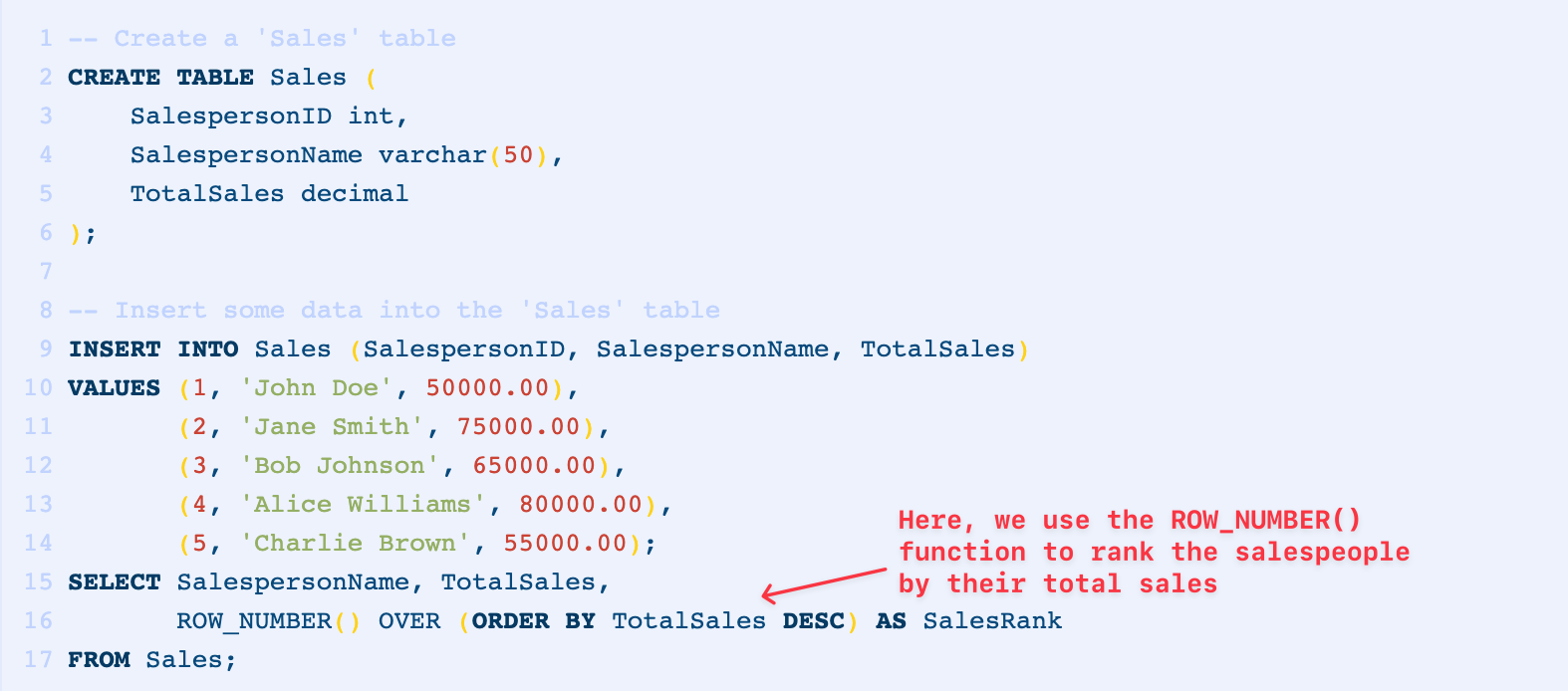
Here’s an example of using the ROW_NUMBER() function to rank salespeople by their sales in a hypothetical sales table.
First, let’s create and populate the following example of a sample ‘Sales’ table:
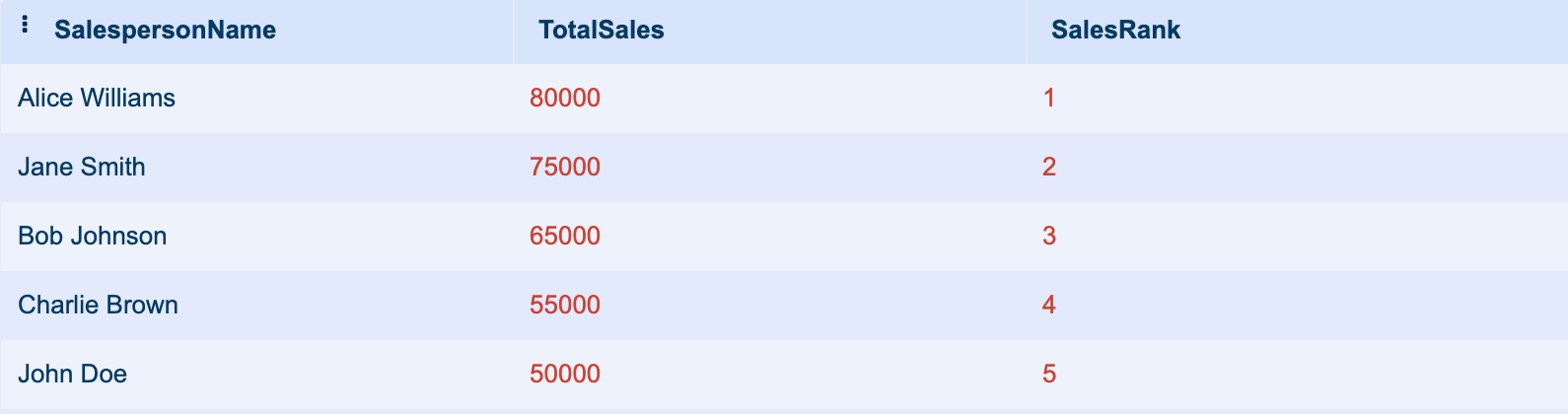
This query will return a list of salespeople, their total sales, and their rank based on total sales, with the salesperson with the highest sales ranked as 1.

4. Data Cleaning from a Sample Table
SQL’s ROW_NUMBER() function can be extremely useful for data cleaning, especially when dealing with duplicate records or when you want the process to return specific results.
Let’s consider a scenario where you have a table with some duplicate rows and you want to clean the data by removing these duplicates in transact SQL.
Firstly, consider this Customers table:
-- Create a 'Customers' table
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(50)
);
-- Insert some data into the 'Customers' table, including duplicates
INSERT INTO Customers (CustomerID, FirstName, LastName, Email)
VALUES (1, 'John', 'Doe', 'johndoe@example.com'),
(2, 'Jane', 'Smith', 'janesmith@example.com'),
(3, 'John', 'Doe', 'johndoe@example.com'),
(4, 'Alice', 'Williams', 'alicewilliams@example.com'),
(5, 'John', 'Doe', 'johndoe@example.com');In this table, the customer John Doe appears three times with the same email address. We want to keep only one record for each customer as they’re divided based on their email address.
We can use the ROW_NUMBER() function to assign a unique row number to each record for the same email address, and then delete all but one of these records.
Here’s how you can do it:
-- Create a CTE (Common Table Expression) that includes a 'RowNumber' column
WITH CTE AS (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY Email
ORDER BY CustomerID
) AS RowNumber
FROM Customers
)
-- Delete the duplicate rows
DELETE FROM CTE WHERE RowNumber > 1;In this case, the output will be a cleaned version of your Customers table with duplicate entries removed. After running the CREATE TEMPORARY TABLE and DELETE commands, the Customers table would look like this.
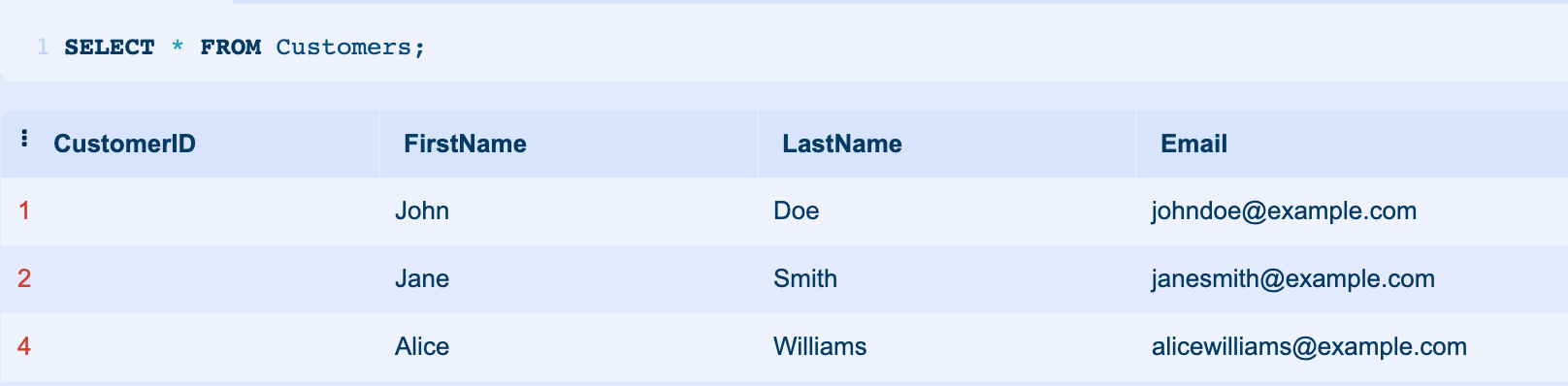
In the output above, to view the cleaned Customers table, you can use a SELECT statement after running the DELETE command:
SELECT * FROM Customers;This will display all the rows returned, which are in the Customers table, which should now be free of duplicates.
5. Finding Maximum/Minimum
When you want to find the maximum or minimum within each group (for instance, the most recent order for each customer), you can use ROW_NUMBER() along with PARTITION BY.
You may also use the SQL Limit clause in some cases to find the minimum and maximum with fewer rows returned.

This will return a query result set that includes a ‘SaleType’ column indicating whether each sale is the maximum or minimum for each salesperson.
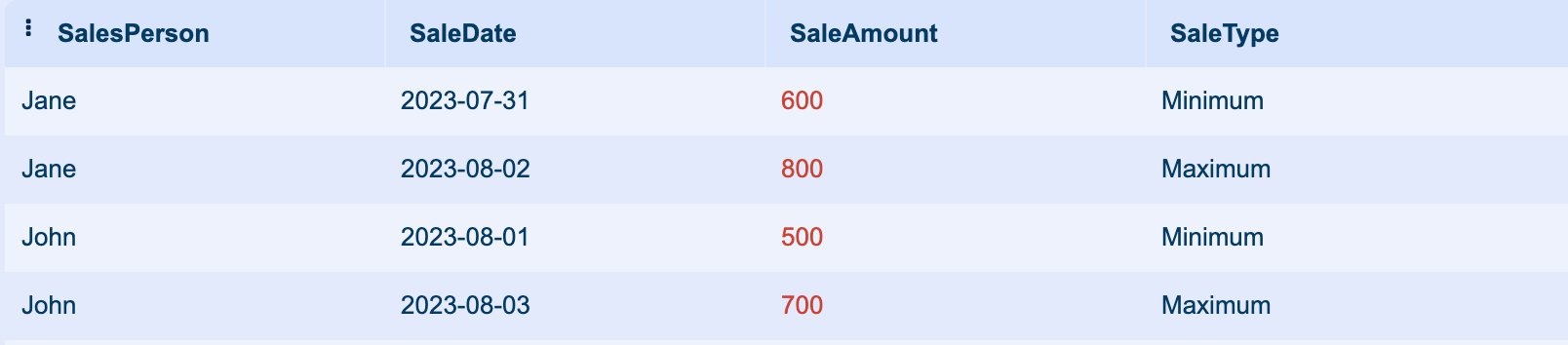
6. Reset Partition Example
We can use the ROW_NUMBER() function with the PARTITION BY clause to reset the row numbers in each partition.
This is useful when we want to apply row numbers separately within each group. For example, we can rank employees by their salary within each department like in the following query:
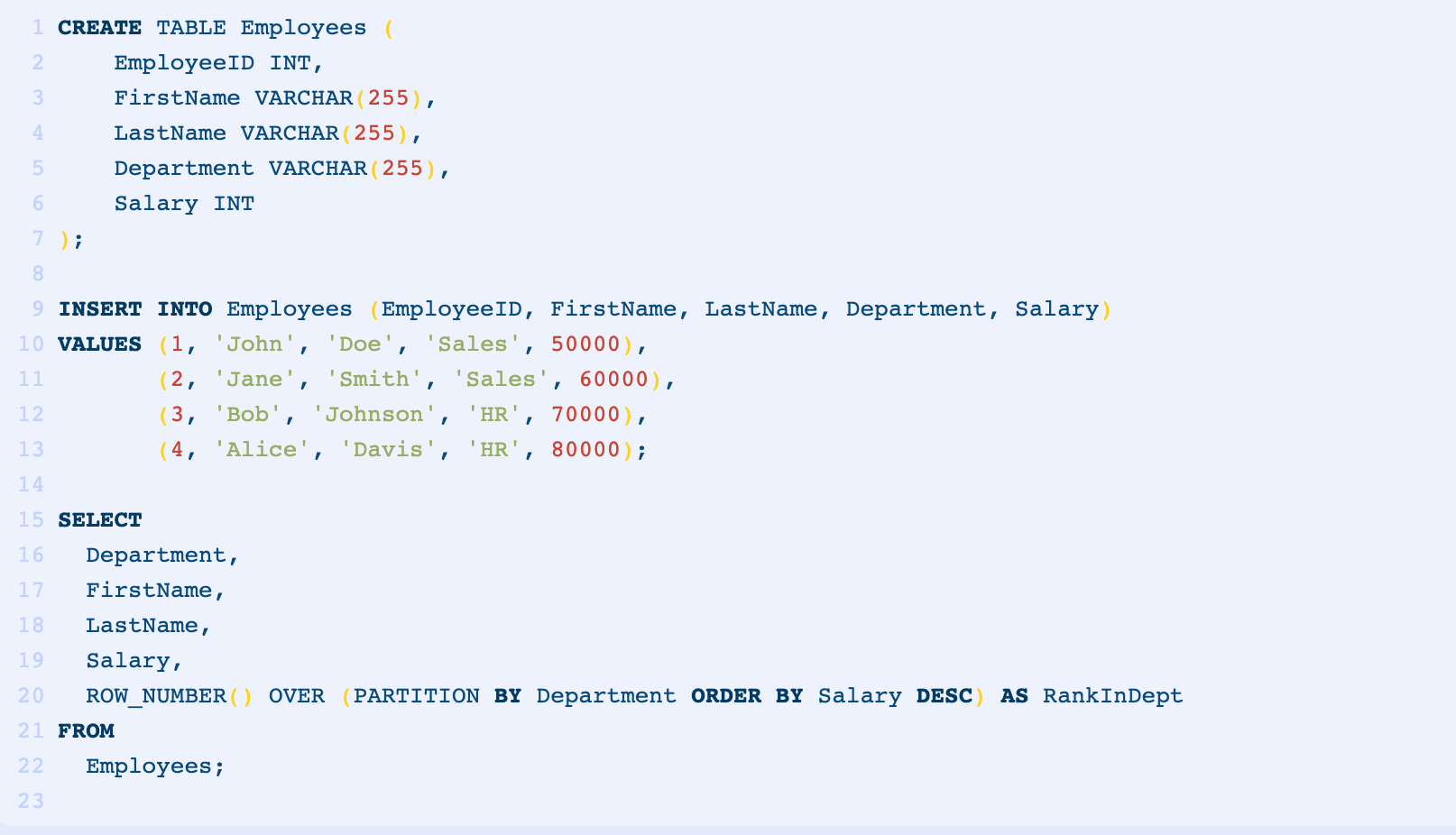
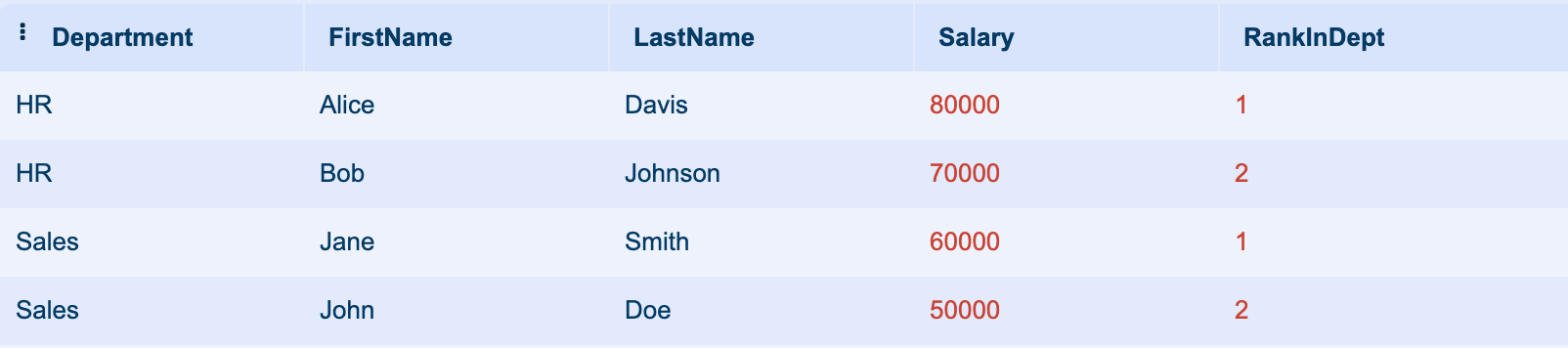
In this query, ROW_NUMBER() assigns a unique row number value specific to each department. The row numbers are reset for each department, providing a full ranking function of employees based on their salary within their respective departments.
If you want to order them by some other criteria or view them differently, you can use the SQL Pivot function.
Final Thoughts
The ROW_NUMBER() function in SQL is a remarkably powerful tool that can greatly enhance your data manipulation and analysis tasks.
It’s an excellent resource for assigning unique identifiers to each row in your result set, which can be invaluable when dealing with complex datasets.
The practical applications of the SQL ROW_NUMBER() function extend beyond merely assigning numbers to rows. It plays a crucial role in pagination, helping divide unwieldy datasets into smaller, more manageable chunks. It also helps you detect duplicate rows, thereby maintaining the integrity of your data.
There’s no doubt that you can do quite a lot with SQL when it comes to managing and processing data. The ROW_NUMBER() function is just one of many advanced functions that SQL offers, allowing for intricate data sorting and management.

If you’d like to use a similar or parallel function like the ROW_NUMBER() but in Power BI, check out the video below:
Frequently Asked Questions
What is ROW_NUMBER vs RANK vs DENSE_RANK?
- ROW_NUMBER() in SQL(and transact SQL) assigns a unique number to each row irrespective of duplicates.
- RANK() gives identical ranks to rows with identical values, skipping the next rank(s) for any duplicates.
- DENSE_RANK() also assigns identical ranks to duplicate values, but it doesn’t skip ranks – the next unique value will always be assigned the next immediate rank.
How do I select the nth row in SQL?
To select the nth row in SQL Server, you can use the ROW_NUMBER() function in combination with a subquery.
We can select the 5th row as shown in the following example:
SELECT * FROM
(
SELECT *, ROW_NUMBER() OVER (ORDER BY some_column) AS RowNumber
FROM your_table
) t
WHERE RowNumber = 5;In this query, replace some_column with the column by which you want to order the data, and your_table with the name of your table. The number 5 should be replaced with the number of the row you want to select.
Does SQL Row_number() function require a window to be ordered?
Yes, the ROW_NUMBER() function in SQL requires a window to be ordered. The OVER() clause, which defines the window, must contain an ORDER BY clause.
This is because ROW_NUMBER() assigns a unique row number to each row within the window, and it needs to know the order in which to assign these numbers.
Here’s a basic example:
SELECT ROW_NUMBER() OVER (ORDER BY some_column) AS RowNumber, other_columns
FROM your_table;In this query, some_column is the column by which the rows are ordered.


