
Have you ever played with a Rubik’s Cube? Picture SQL Pivot as the ultimate Rubik’s Cube for your data. It can flip, twist, and turn your data to offer a fresh perspective, just like the colorful squares on a Rubik’s Cube.
Intrigued? Well, as a developer or analyst who has to wrestle with loads of data, SQL Pivot could soon become your new best friend.
SQL Pivot is a relational operator that transforms data from row level to column level. The magic of SQL Pivot lies in its ability to rotate a table-valued expression, turning unique values from one specified column into multiple columns in the output and performing aggregations where they are required.

In this article, we’ll delve into the concept of SQL Pivot, a powerful technique used to transpose data from rows to columns. We’ll guide you through its fundamental principles, its practical applications, and how it can be used to enhance data readability and analysis.
Let’s dive in!
Understanding Pivot in SQL Server

SQL Pivot is a powerful tool used in SQL Server to rotate table-valued expressions and convert rows into columns and perform aggregations on specific columns.
The PIVOT relational operator turns the unique row values in one column into multiple pivot columns in the output. This operation is also known as a cross-tabulation.
Cross-tabulation is particularly useful when you want to transform your data from a normalized or “unpivoted” format to a pivoted one, which can often make it easier to understand and analyze.
It’s also useful when dealing with large datasets that require organizing and summarizing data to gain a more clear view and better understanding.

You can use SQL Pivot in SQL Server and Oracle, but PostgreSQL and MySQL may need you to use multiple operators in combination to achieve the same result.
In all of these database management systems (DBMS), the syntax is more or less similar, which is why we’ll focus more on the functionality side than syntax differentiation.
Syntax for the Pivot Operator
The PIVOT operator works by turning the unique values in one column into multiple columns in the output and performing the specified aggregation functions (like SUM, COUNT, AVG, etc.) on the remaining column values.
The basic syntax for using Pivot in SQL Server is as follows:
SELECT ...
FROM ...
PIVOT (aggregate_function(column_to_be_aggregated)
FOR column_to_be_pivoted
IN (list_of_values))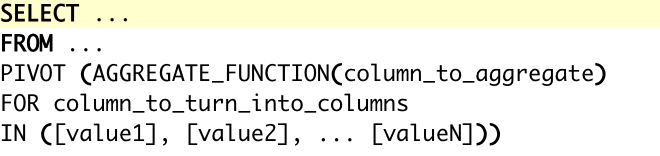
Please note that the entire PIVOT operation is enclosed within parentheses and forms part of the FROM clause of the query. The list of values provided in the IN clause should be exhaustive and static.
For example, consider the following example of a table Sales:

In the above example, the query will return a result set where each product has a separate row, and the sales for each year are shown in separate columns.
Let’s look at another example. Suppose we have a Scores table that stores the scores of students in different subjects:
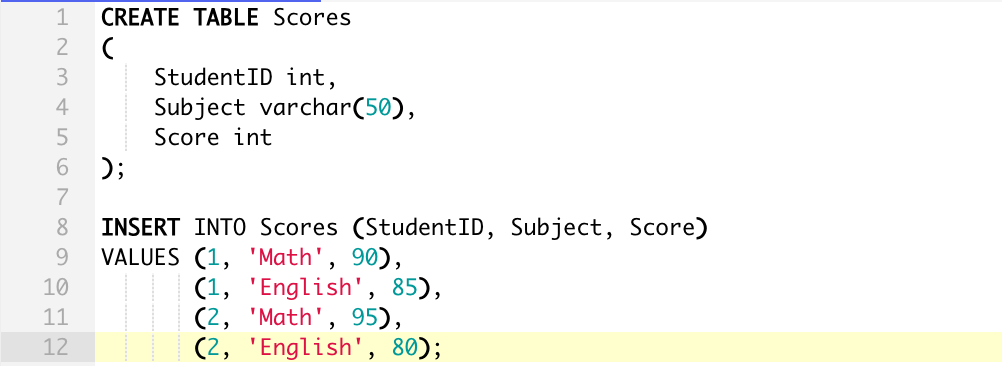
Here’s the SQL Server PIVOT query you would use:
SELECT StudentID, [Math], [English]
FROM
(
SELECT StudentID, Subject, Score
FROM Scores
) AS SourceTable
PIVOT
(
SUM(Score)
FOR Subject IN ([Math], [English])
) AS PivotTable;The output of the above query would be:

This SQL query will provide a summary of the scores each student has achieved in the subjects Math and English.
For each unique StudentID, it’ll create a row. In this row, there will be two columns for math and English. The values in these columns will be the total scores (summed up if there are multiple entries) the respective student achieved in these subjects.
Next, let’s go over the basics of pivot tables and common scenarios where they are used!
Pivot Tables: The Basics You Need to Master
In SQL Server, a pivot table is a feature or concept that allows you to change the data from being displayed in rows to columns.
A pivot table is essentially a piece of summarized information that is generated from a large underlying dataset. It’s generally used to report specific dimensions from the perspective of the data.

Some common scenarios where pivot tables are used include:
- Summarizing sales data by region, product, or customer
- Aggregating time-based data, such as monthly or yearly reports
- Comparing data across different categories (e.g., male vs. female, new vs. returning customers, etc.)
Creating a pivot table in SQL usually involves the following steps:
- Start by selecting a base dataset for pivoting.
- Define the columns that will be displayed in the output.
- Specify the column to be pivoted and the aggregation function to be applied.
Here’s an example of a SQL query that creates a pivot table:
SELECT EmployeeID, [2023-07-01], [2023-07-02]
FROM
(
SELECT EmployeeID, WorkDate, Hours
FROM EmployeeHours
) AS SourceTable
PIVOT
(
SUM(Hours)
FOR WorkDate IN ([2023-07-01], [2023-07-02])
) AS PivotTable;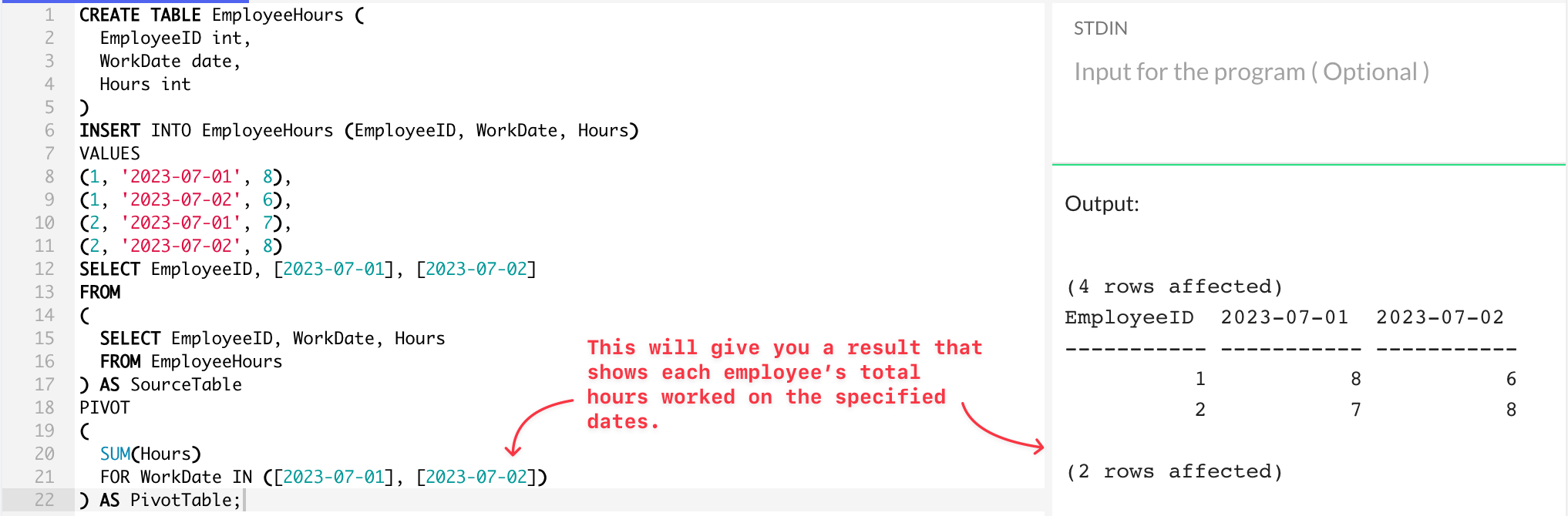
In the above example, the result shows each employee’s total hours worked on the specified dates in a pivot table.
Alright, now that we’ve covered the fundamentals, let’s go over how to prepare data for pivoting in the next section.
What is the UNPIVOT Operator?

The UNPIVOT operator in SQL Server is a powerful tool that essentially performs the opposite operation of the PIVOT operator.
In Microsoft SQL Server, the UNPIVOT operator performs the reverse operation of PIVOT. This helps in data analysis, especially when you need to convert columns into rows for easier interpretation and presentation.
While the PIVOT operator is used to transform row-wise data into column-wise data, the UNPIVOT operator takes column-based data and transforms it into row-based data in a new pivot table.
The syntax for UNPIVOT commands is as follows:
SELECT ... FROM ...
UNPIVOT
(
[new_column_name] FOR [existing_column_name] IN (column_list)
) AS UnpivotTable;You can also look at the above query like this:
SELECT <non-pivoted column>, [<list of pivoted columns>]
FROM (<SELECT query to produce the data>) AS <alias for the source query>
UNPIVOT (<column to be turned into multiple rows>
FOR [<column that will be converted>]
IN (<list of columns to unpivot>)
) AS <alias for the unpivot table>Keep in mind that while pivoting, the choice of the aggregate function depends on the nature of the data and the desired output.
For instance, if there is only a single value for each combination of row and column for the pivot, you can use SUM, MAX, or MIN as they return their input when given a single input.
When Do You Use UNPIVOT?
UNPIVOT is useful when you have a denormalized data structure that you need to normalize. For instance, if you have a table where some of the data is stored as column headers, you could use UNPIVOT to transform these columns into rows.
The UNPIVOT operator is most frequently used when there is a need to normalize the output of a query. This could be the case when the data is initially presented in a non-normalized or ‘wide’ format, with separate columns for related data points, and it would be more useful or efficient to organize these data points into rows under a single column.
For example, consider a table that records monthly sales figures with separate columns for each month. If you wanted to analyze the total sales figures across all months, it might be easier to do this if all the sales figures were listed in rows under a single ‘Sales’ column, rather than spread out across multiple ‘Month’ columns.
In this case, you could use the UNPIVOT operator to transform the data into this more analyzable format.
Here’s a scenario that shows two tables and code for it you can use to create a pivot table that showcases it by year from the sample table Sales:
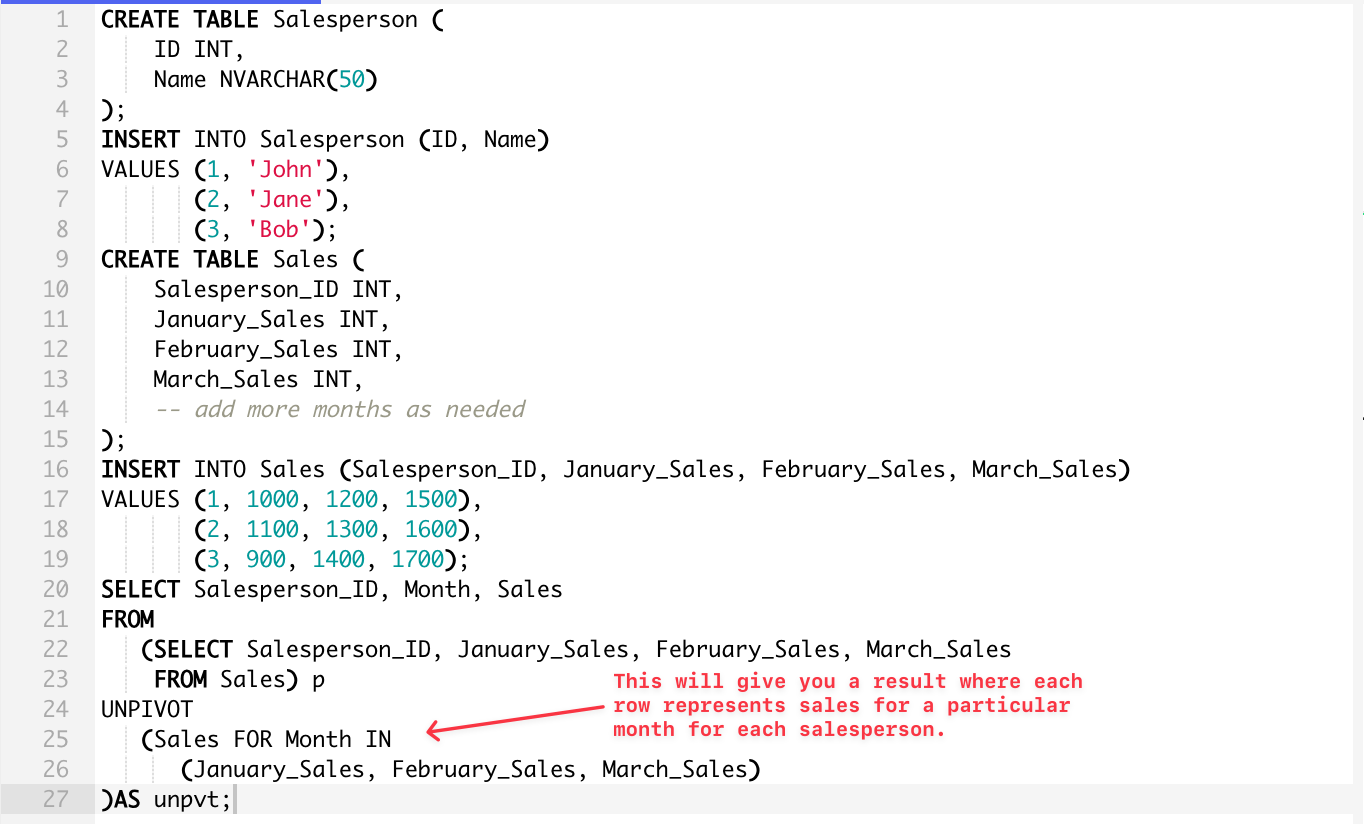
In the above example, the ‘Month’ column will hold the month name, and the ‘Sales’ column will hold the sales figure for that month.
Of course, you can also use ChatGPT to make sure you have your syntax and JOINs perfected with a command or prompt in AI.
In the next section, we’ll take a look at how you can use dynamic pivot tables to transform your data.

How to Use Dynamic Pivot Tables to Transform Data
In SQL Server, dynamic pivot tables and dynamic columns come in handy when you want to transform or rotate your data from a normalized dataset format into a more readable format, especially when the columns you want to create are not known beforehand.
A typical PIVOT operation in SQL Server requires you to explicitly list out the values that you want to turn into columns. However, when you have a large number of distinct values or when these values keep changing, manually updating the PIVOT query becomes impractical. This is where dynamic SQL comes in.
Dynamic SQL is a programming technique that allows you to construct SQL statements dynamically at runtime. It’s particularly useful when you need to create a SQL query based on variables that are unknown until runtime.
With dynamic SQL, you can construct a dynamic pivot query where the column names are determined at runtime. Here’s an example:
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
-- Get the list of unique values for the pivot column
SELECT @columns = COALESCE(@columns + ', ', '') + QUOTENAME(ColumnName)
FROM (SELECT DISTINCT ColumnName FROM YourTable) x;
-- Construct the dynamic pivot query
SET @sql = '
SELECT *
FROM YourTable
PIVOT (
SUM(ValueColumn)
FOR ColumnName IN (' + @columns + ')
) p';
-- Execute the dynamic pivot query
EXEC sp_executesql @sql;In this example, @columns is a variable that holds the dynamically constructed list of column names, and @sql is a variable that holds the final pivot query. The sp_executesql stored procedure is then used to execute this dynamic pivot query.
This will return a result set with a column for each unique year in the Sales table and a row for each product with the total sales amount for that product in each year.
Please note that this is a simplified example and actual usage would depend on your specific requirements and database schema. To illustrate what we mean, we’ll go over four examples of dynamic SQL in action.
1. Dynamic ORDER BY Clause
If you want to order your pivot data result set dynamically based on a column name that will be known only at runtime.
DECLARE @OrderByColumn NVARCHAR(128) = 'Year'; -- This can be any column of your table
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT * FROM Sales ORDER BY ' + QUOTENAME(@OrderByColumn);
EXEC sp_executesql @sql;Here’s how you would use it in an actual sample table in the SQL server database:

The output shows the data from the above pivot function organized by year:

2. Dynamic WHERE Clause
Similar to the dynamic ORDER BY clause, you may also need to build a WHERE clause dynamically.
DECLARE @FilterColumn NVARCHAR(128) = 'Year'; -- This can be any column of your table
DECLARE @FilterValue INT = 2021;
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT * FROM Sales WHERE ' + QUOTENAME(@FilterColumn) + ' = @FilterValue';
EXEC sp_executesql @sql, N'@FilterValue INT', @FilterValue;Here’s how you can use it in a sample table:

3. Dynamic JOIN Clause
In some cases, you may want to join tables dynamically. Here’s how you’d do it:
DECLARE @JoinTable NVARCHAR(128) = 'Product'; -- This can be any table in your database
DECLARE @JoinOnColumn NVARCHAR(128) = 'ProductID'; -- This can be any column of your table
DECLARE @sql NVARCHAR(MAX);
SET @sql = N'SELECT * FROM Sales JOIN ' + QUOTENAME(@JoinTable) +
' ON Sales.' + QUOTENAME(@JoinOnColumn) + ' = ' +
QUOTENAME(@JoinTable) + '.' + QUOTENAME(@JoinOnColumn);
EXEC sp_executesql @sql;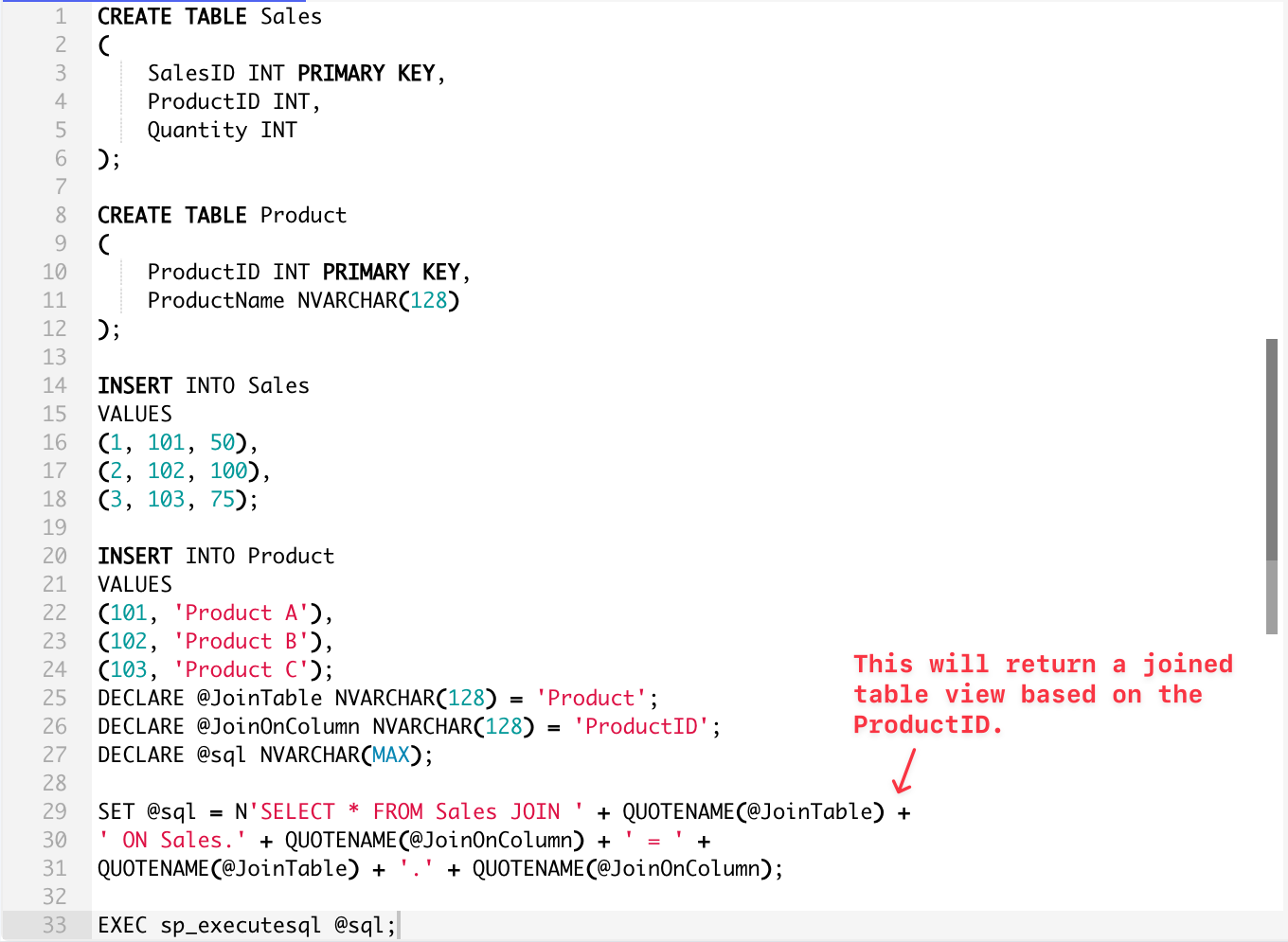
In the above example, the result will return a joined table view based on the ProductID.
4. Renaming Columns Dynamically
There might be scenarios where you want to rename columns dynamically based on certain conditions or values. In SQL Server, you can achieve this using a combination of string concatenation and system functions.
Here’s an example:
DECLARE @Year NVARCHAR(4);
SET @Year = CAST(YEAR(GETDATE()) AS NVARCHAR(4));
DECLARE @sql NVARCHAR(MAX);
SET @sql = 'ALTER TABLE Sales RENAME COLUMN Amount TO Amount_' + @Year;
EXEC sp_executesql @sql;Here’s a demonstration of how to use it on a sample table Sales:

Alright, we’ve covered a lot of ground so far. In the next section, we’ll go over some advanced techniques and tips using PIVOT.
Advanced Techniques and Tips Using SQL Pivot
Pivoting in SQL can become increasingly complex with advanced techniques, but mastering these concepts will enable you to create more sophisticated reports, manipulate data, and perform data transformations like dynamically converting rows to columns with ease.
1. CASE statement with aggregate functions: If your SQL version doesn’t support the PIVOT keyword or you need more flexibility, you can use a combination of CASE statement expressions and aggregate functions such as MIN, MAX, or AVG to achieve similar results.
This method will work across various SQL dialects and provide more control over data aggregation. You can check how to go about it in the following query:
SELECT
year,
SUM(CASE WHEN month = 1 THEN value END) AS Jan,
SUM(CASE WHEN month = 2 THEN value END) AS Feb,
-- ...
FROM sales
GROUP BY year2. Combining PIVOT with JOINs: Utilizing INNER JOIN in conjunction with PIVOT can help merge related datasets using common keys before or after the transformation, enhancing the final output and reducing the need for additional data manipulation.
3. Working with dates: Pivoting time-based data often requires some preprocessing. For example, extracting specific date parts (e.g., day, month, or year) from a DATE column can make the pivoting process smoother.
4. Consider using temp tables or views: To simplify complex PIVOT operations, consider breaking them down into smaller pieces using temporary tables or views, helping manage input data and intermediate results better.
5. Using VARCHAR and other data types in PIVOT: Remember that the aggregated value in the PIVOT clause must match the data type of the column identifier. If necessary, use explicit type conversions to ensure consistency and avoid runtime errors.
6. Handling NULL values: Pivoting data can lead to NULL values in your result set. You can use the ISNULL or COALESCE functions to replace NULLs with default or custom values for better data presentation.
7. Using cursors for data transformation: Although cursors have some performance drawbacks compared to set-based operations, in specific scenarios, using a cursor to execute data transformations row-by-row can offer greater control over the process.
Final Thoughts
The SQL PIVOT operator is a powerful tool that can significantly enhance the readability and analysis of your data. By transforming unique values from one column into multiple columns in the output and applying specified aggregation functions, it allows for a more organized presentation of data.
We’ve explored the fundamental principles of the SQL PIVOT operator and its practical applications and provided step-by-step instructions on how to use it.
Understanding and effectively using this operator can greatly improve your data management and analysis tasks, making it an essential skill for anyone working with SQL.
We hope that this information has provided you with a solid foundation and the confidence to apply these concepts in your own work!
If you’d like to learn more SQL fundamentals, check out our video below on how to use SQL in Power BI and DAX:
Frequently Asked Questions
What is the difference between pivot and unpivot in SQL?
Pivot: In SQL, the pivot operation converts row data into column data. It changes the data from a ‘long’ format to a ‘wide’ format.
Unpivot: The unpivot operation does the opposite, converting column data into row data. It changes the data from a ‘wide’ format to a ‘long’ format.
What are the two types of pivots?
- Static Pivot: In a static pivot, you need to define all the transformation column values upfront in your code. This means that if the data changes and includes new values, the code must be updated to accommodate these.
- Dynamic Pivot: A dynamic pivot allows for more flexibility. It automatically adapts to new transformation column values in the data. This is useful when you don’t know all the possible values of a column upfront, or if they can change over time.
Which SQL supports pivot?
- SQL Server: The PIVOT operator has been available since version 2005.
- Oracle Database: PIVOT and UNPIVOT operations have been supported since version 11g.
- Snowflake: This system also supports the PIVOT operator, including built-in aggregate functions like AVG, COUNT, MAX, MIN, and SUM.
Are pivot tables databases?
No, pivot tables are not databases. They are a data summarization tool used in spreadsheet programs like Microsoft Excel and Google Sheets.
Pivot tables take simple column-wise data as input, and allow the user to manipulate and analyze the data dynamically in a variety of ways, such as sorting, averaging, summing, or other aggregate functions.


