
In this post, we are going to look at how to load sample data sets in Python. This may not seem like the most glamorous topic, but it’s actually quite important. Ideally, you will have some datasets in Python that you can practice on when you’re learning new concepts. You can watch the full video of this tutorial at the bottom of this blog.
If you’re going to share your code, document what you’ve done, or need help, it’s really a good idea to use a generally available dataset to build something what’s called a minimally reproducible example.

You’re going to have a pre-bundled code or script that somebody else on the internet can run and help you with it. If you do not produce these minimally reproducible examples, you get flamed on places like Stack Overflow, which can be a bit of a shock if you’re not familiar with it.

Let’s look at a few ways to build these minimally reproducible examples and get the datasets. There are a few packages that you can use to load in a premade dataset into Python and share that code around.
We’ll look at three packages that are the most common ones. Let’s fire up a blank Jupyter notebook and get started.
Load Datasets In Python From Sklearn
The first one we’ll look at is called Sklearn. If you’re using Anaconda, you will not need to download this. If you’d like more help with Python, Enterprise DNA does have a Python for Power BI users course that you can sign up.
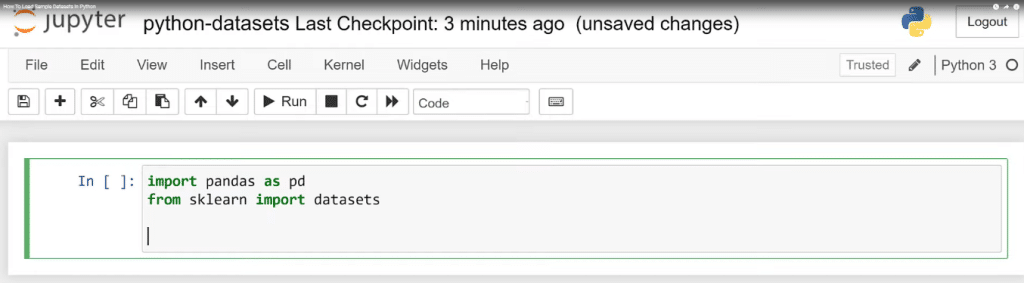
I’m going assume that you already know about things like packages, and go from there. We’re going to bring in pandas and Sklearn, specifically the dataset submodule.
We are going to bring a few of these data sets. Scikit-learn – a machine learning data library – calls them toy data sets. We’re going to load Boston, which is a housing prices dataset. When we bring this in, we need to have it as a data frame.

We need to actually specify that the data and columns are coming from the Scikit-learn dataset, and separate the feature variables and the target variables.
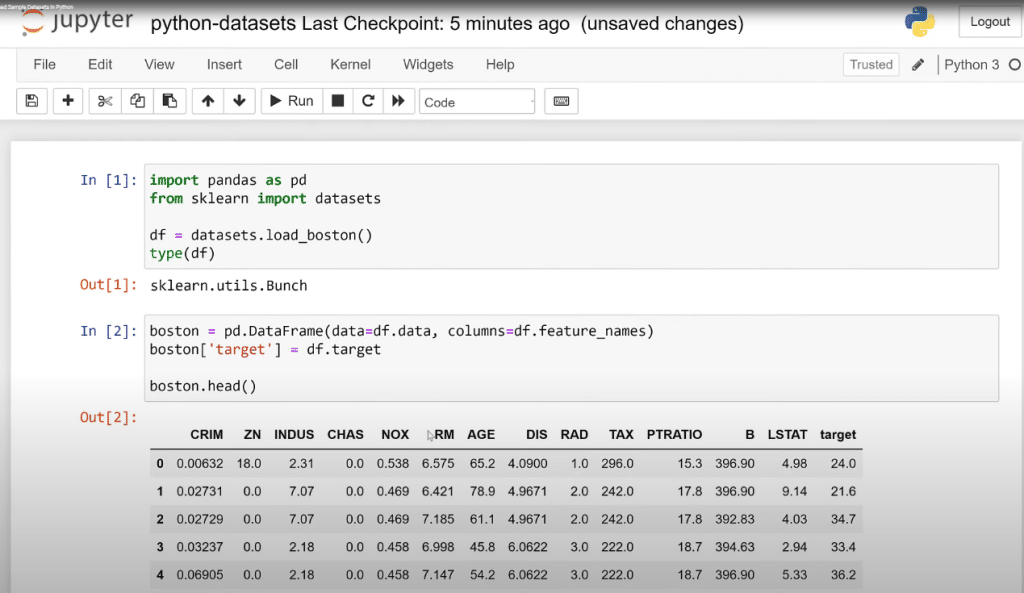
We’ll get this in as a data frame so we can operate and do different things with it. Panda is such a great package to know as a Power BI user.
Load Datasets In Python From Vega Datasets
Another option we can learn is the Vega datasets package. This one is not available on Anaconda but we can install it through PIP. This is what we’ll be typing on the command line to install the Vega datasets, and to install or import the local data module.
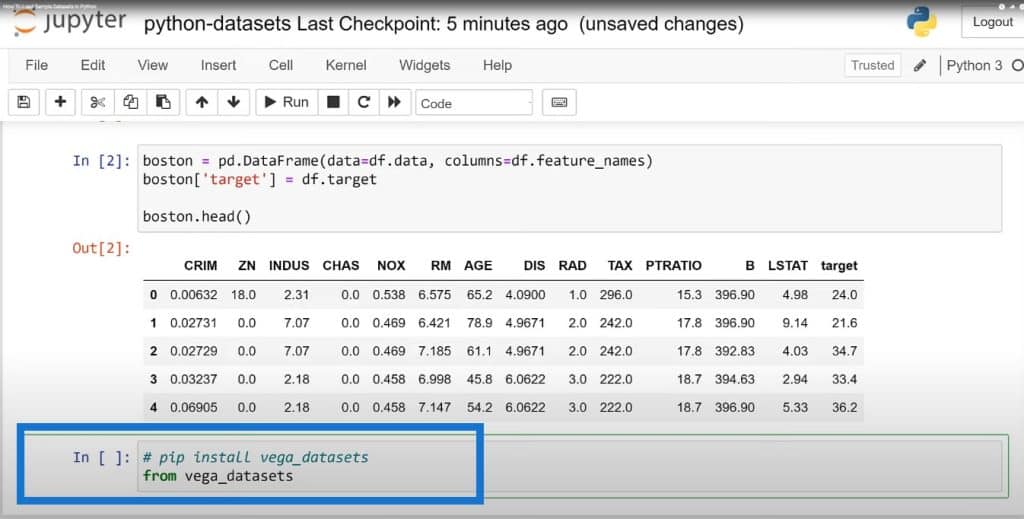
Some of these you can actually get, but you will need a web connection. We’ll bring in the ones that are installed locally by importing local data and running it.
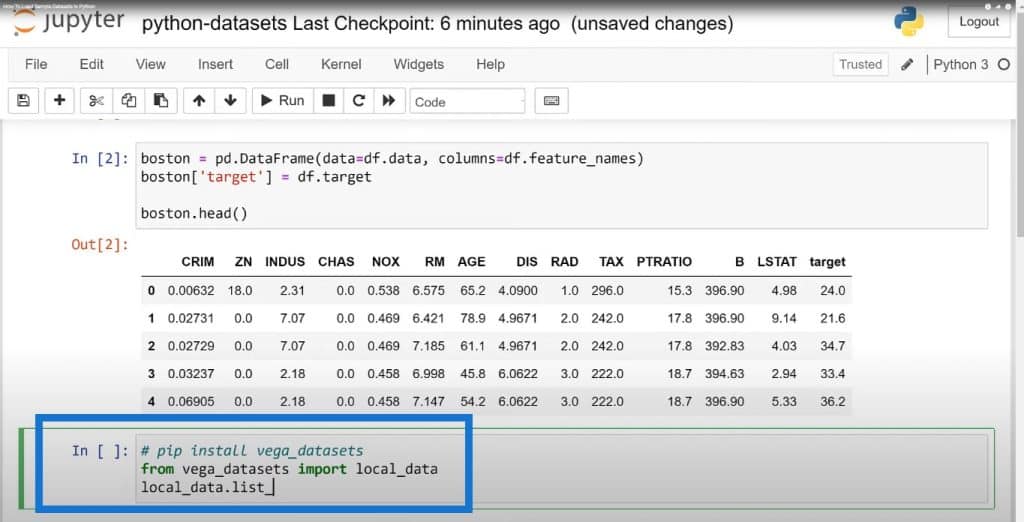
As you can see, there are quite a few datasets. Some of these are time series, while some of these have categorical or continuous variables. Let’s choose the cars dataset in a data frame so we can run the head method on it.
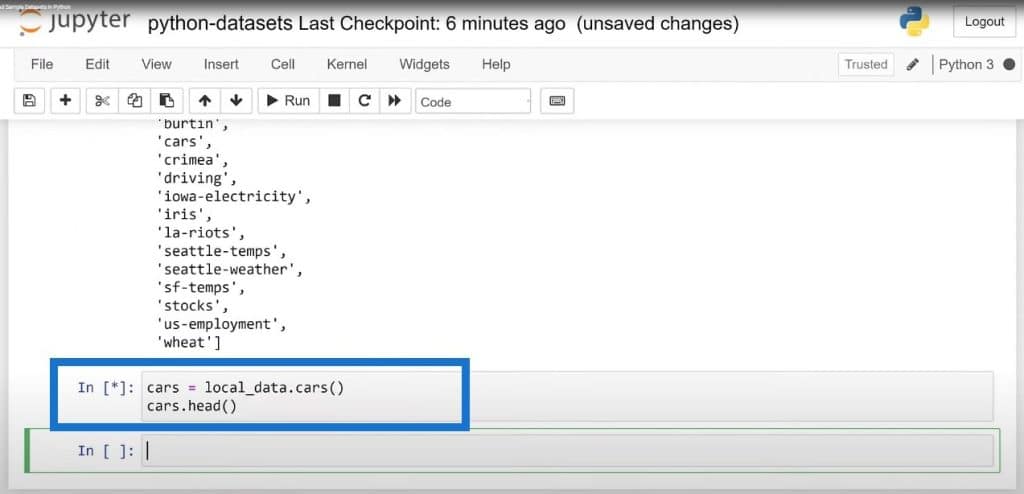
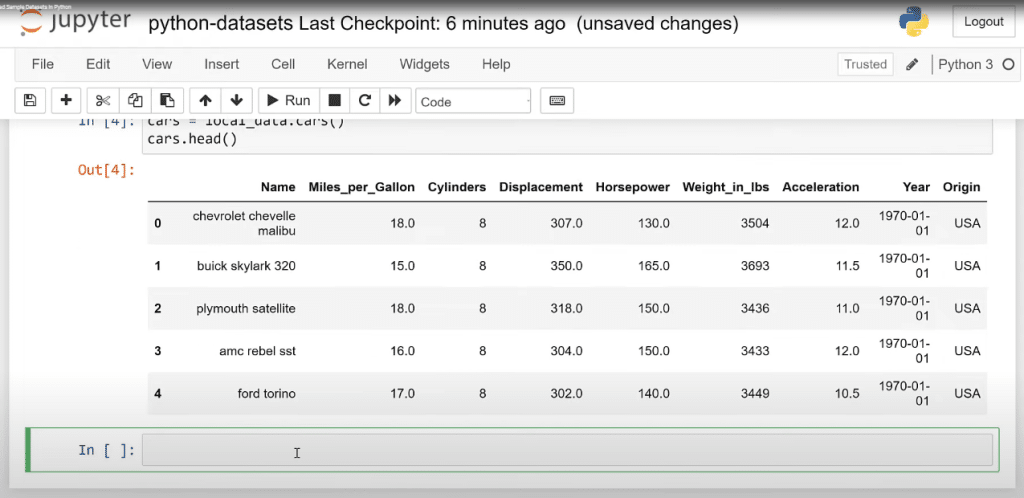
Now, we have another sample dataset that we can use and share.
Load Datasets In Python From Seaborn
Seaborn is another package that is available in the Anaconda distribution. By default, Seaborn is best known for data visualization, but it also has some great sample datasets that you can use. This is what we’ll type to get datasets.
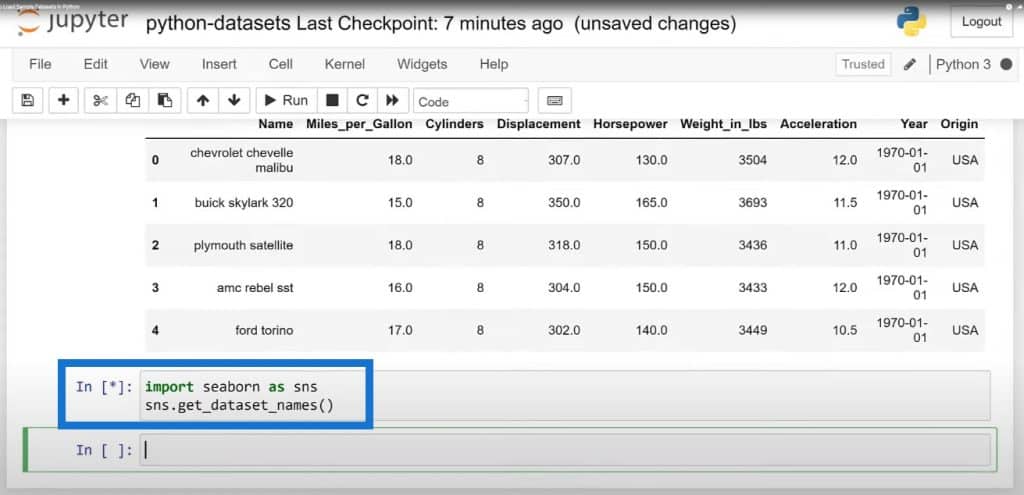
As you can see, there are quite a few datasets here. We’ll go ahead and use the penguins data set and get the first few rows again.
The result is another dataset for us to practice on.
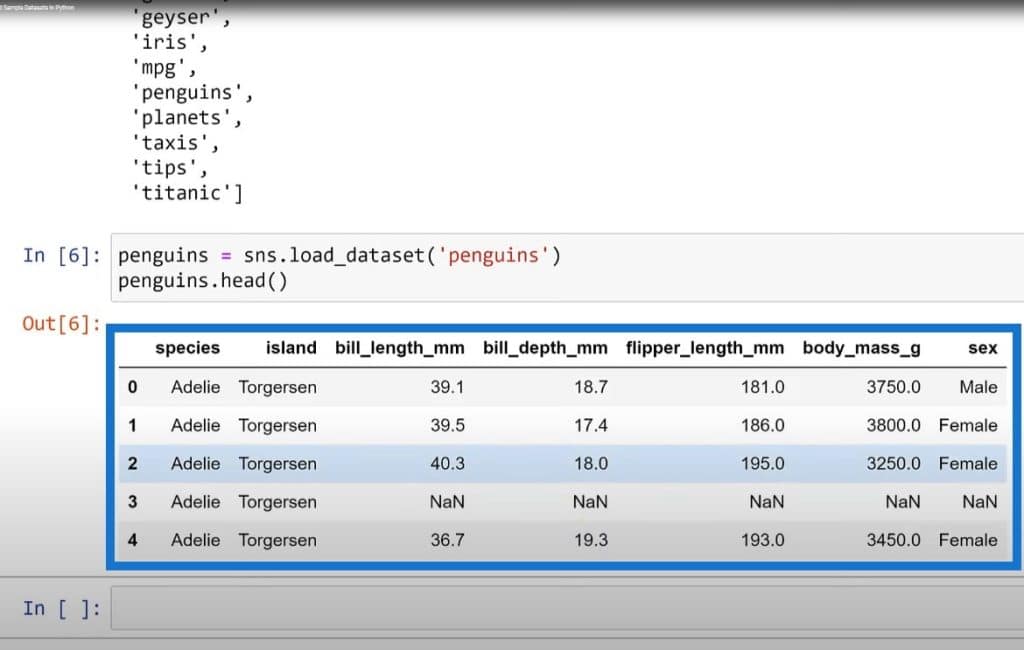
The idea here is not just to have the datasets to practice on. If we’re seeing some missing values, having trouble dropping datasets, wanting to fill in the categorical variable or showing an example to other people without giving some sensitive data, you can just use one of these publicly accessible datasets that are really, really easy for people to use and share. That’s the idea of a minimally reproducible example.
***** Related Links *****
Power BI With Python Scripting To Create Date Tables
Python In Power BI: How To Install And Set Up
Python I for Power BI Users – New Course in the Enterprise DNA Education Platform
Conclusion
To recap, there are three places to look for sample datasets. Scikit-learn is a machine learning package. It’s a little harder to convert, but if you are doing things related to machine learning, this is the place to go. Vega datasets also has quite a good number of data sets specially if you use the method to get datasets from the web but it’s relatively harder to load so you just have to use PIP versus having it pre-installed with Anaconda. Seaborn is the sweet spot because it loads the data frame and it has a lot of versatility when it comes to using sample data sets and reproducible examples.
Stack Overflow also has a tutorial on how to write a good minimally reproducible example or MRE, so check that out if you’re looking to post something online.

Knowing where to get good datasets and sharing a good MRE is a really important skill to have as an analyst.
If you enjoyed the content covered in this particular tutorial, please subscribe to the Enterprise DNA TV channel. We have a huge amount of content coming out all the time from myself and a range of content creators – all dedicated to improving the way that you use Power BI and the Power Platform.
George


