
SQL, or Structured Query Language, is an essential tool for managing and manipulating data within relational databases.
One common challenge database users face is working with duplicate values within tables. To address this issue, SQL provides a powerful keyword called DISTINCT, which allows users to filter out duplicate records and display only unique values in their query results.
The DISTINCT keyword is used within the SELECT statement to eliminate duplicate rows in the result set, ensuring that each value is displayed only once, regardless of how many times it might appear in the table. This feature is particularly useful when working with large datasets where identifying unique values can be time-consuming and cumbersome.

Furthermore, by using DISTINCT in a query, database users can quickly and efficiently obtain the desired results without having to deal with unnecessary duplicates.

In this guide, we will provide an overview of how to use DISTINCT in SQL queries, including SELECT DISTINCT examples. You will learn the syntax for applying DISTINCT on single and multiple columns, how it differs from the ALL keyword, and how to combine DISTINCT with other SQL clauses like WHERE, ORDER BY, and GROUP BY.
By the end, you will have a solid understanding of this simple but powerful tool for managing duplicate data. So let’s get started.
Understanding SQL DISTINCT
The DISTINCT clause is used in SQL SELECT statements to return only the unique values from a specified column or set of columns in a table. It is used to eliminate duplicate rows and display a unique list of values.
1. Basic SELECT DISTINCT Syntax
The basic syntax for using SELECT DISTINCT is as follows:
SELECT DISTINCT column_name
FROM table_name;For example, consider the table invoices from the Chinook sample database:

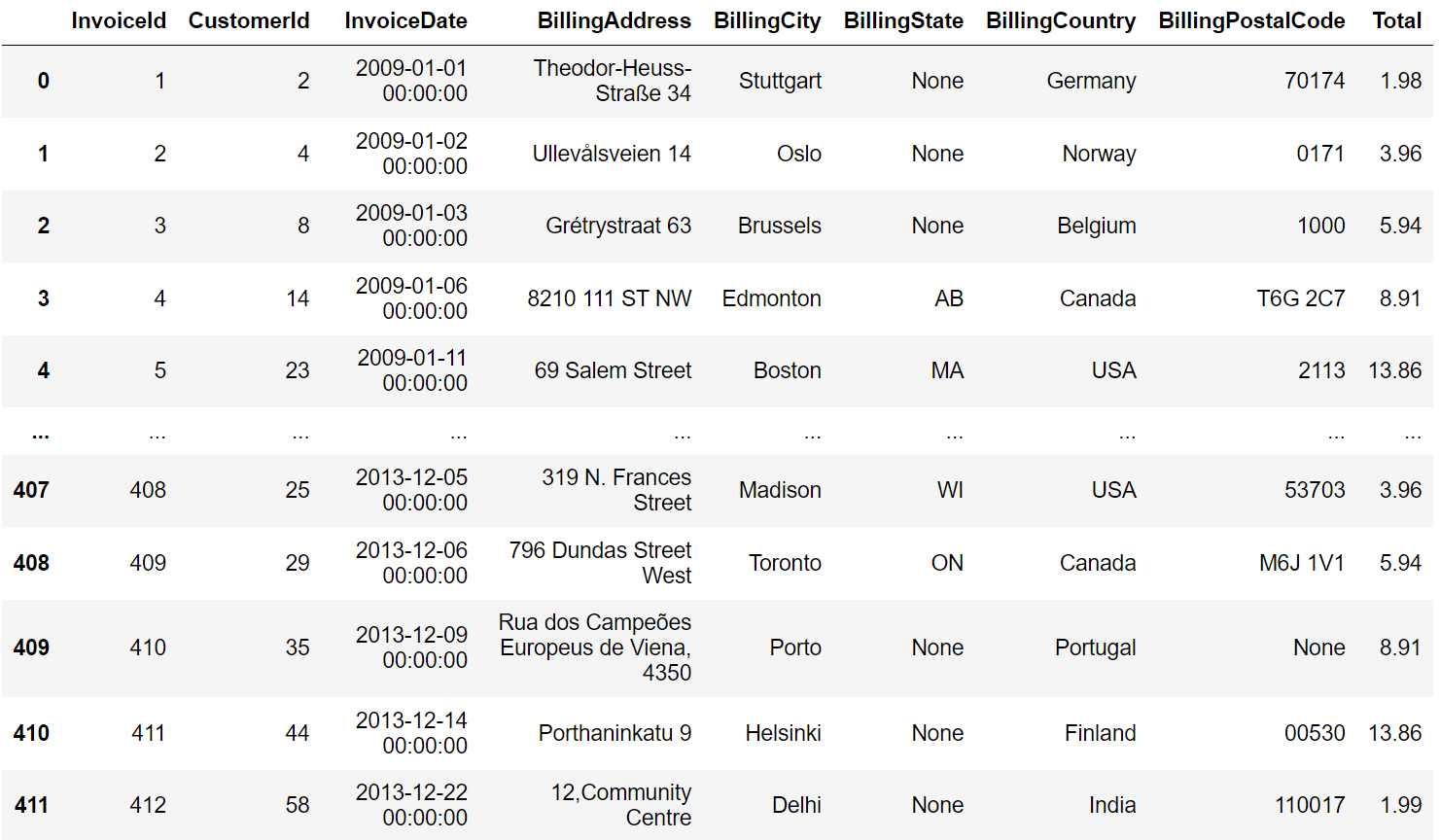
To retrieve unique customerIDs from the table, you can use the following SQL query:
SELECT DISTINCT customer_id
FROM invoices;2. DISTINCT vs ALL
The DISTINCT keyword contrasts with the ALL keyword. By default, a SELECT query returns all rows, including duplicates. When you use the DISTINCT keyword, the query filters the result set to display only unique values, removing any duplicates.
On the other hand, the ALL keyword, when used explicitly, allows the inclusion of duplicate records in the result set.
Let’s see an example of using SELECT DISTINCT using the DISTINCT table in the HR Data sample database. The table has a record of 39 employees.
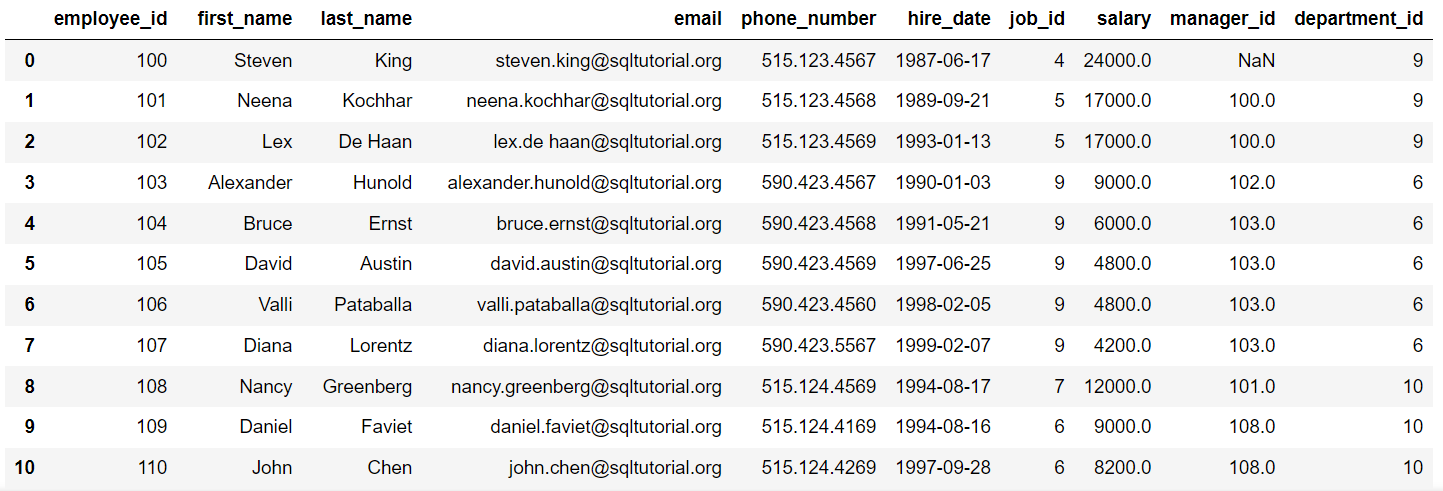
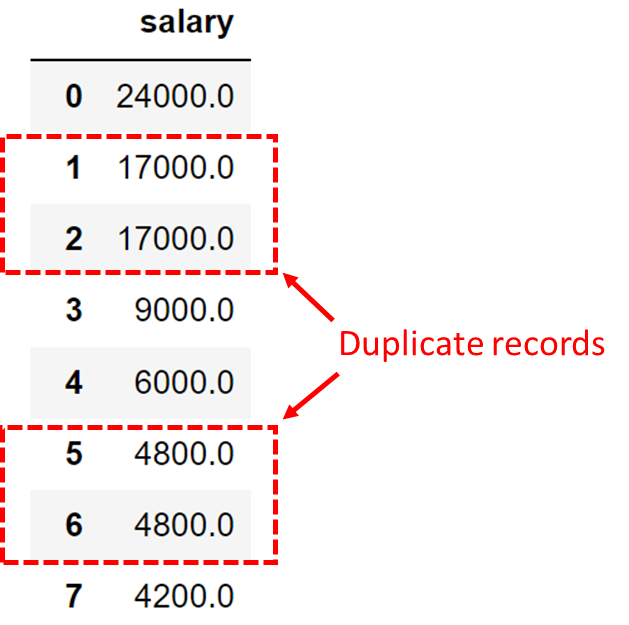
If we want to find out the unique salaries of the employees, here’s how it can be done using SELECT DISTINCT:
SELECT DISTINCT salary FROM employeesThis query retrieves all unique salary values from the employees table with a total of 32 results after excluding the duplicate salary records.
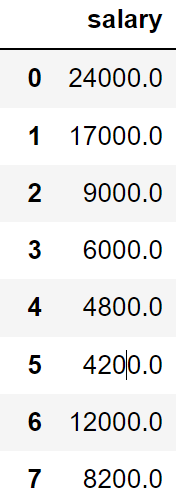
When using the ALL keyword, instead of DISTINCT:
SELECT ALL salary FROM employeesThis query retrieves all 39 salary values from the employees table, including duplicate records.
3. Using DISTINCT with Multiple Columns
When using the SQL SELECT DISTINCT statement, you are essentially telling the database to return only unique values in the specified columns. The database engine compares each row in the result set, and if it finds a row that matches another row in all specified columns, it discards the duplicate row.
When you want to retrieve unique combinations of values from multiple columns, simply list the columns after the DISTINCT keyword, separated by commas:
SELECT DISTINCT column1, column2, ...
FROM table_name;For example, when you run the following SQL statement for the employees table:
SELECT DISTINCT First_Name, Last_Name, department_id FROM employeesThe result set would include all 39 rows because each row is distinct when comparing all the specified columns.
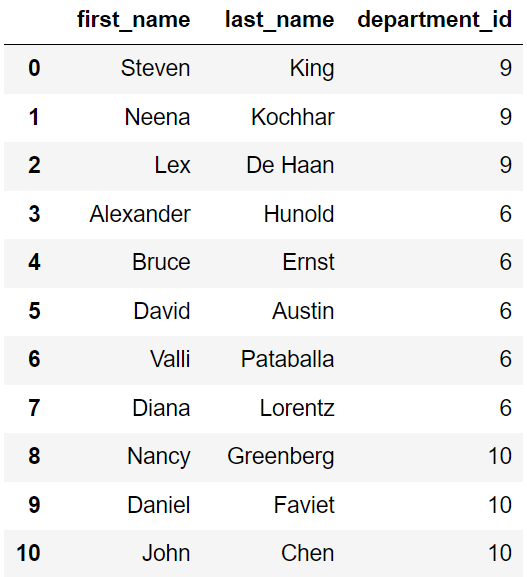
However, when running a similar query for a particular column:
SELECT DISTINCT department_id FROM employeesThe result set would include only 11 rows since there are only 11 unique entries in the department_id column.
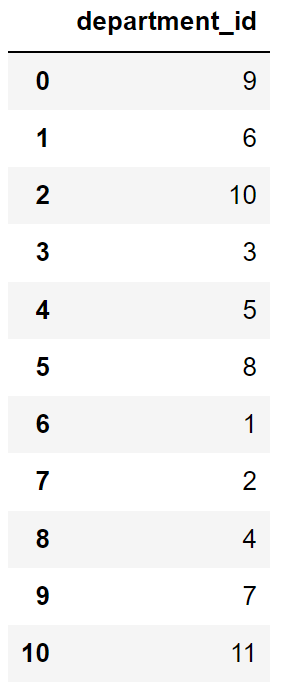
4. Using DISTINCT with Expressions
You can also use the DISTINCT keyword with expressions or calculations involving one or more columns. In this case, the expression is placed after the DISTINCT keyword:

SELECT DISTINCT expression
FROM table_name;For example, let’s assume that a products table contains columns for price and quantity.
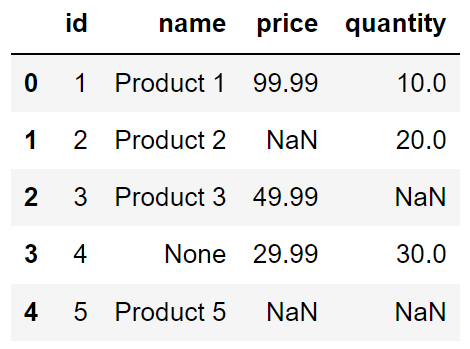
If you want to retrieve distinct total amounts based on the expression price * quantity. You can use the following SELECT query:
SELECT DISTINCT quantity * price as total_amount
FROM products;In this query, the expression quantity * price calculates the total amount for each order, and the DISTINCT keyword ensures that only unique total amounts are retrieved.
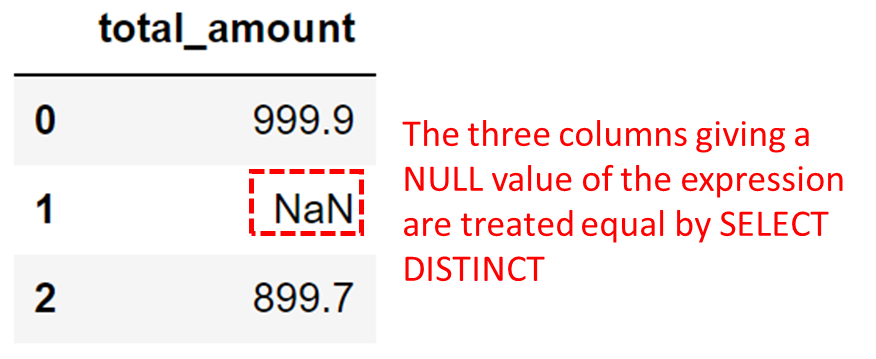
SQL DISTINCT Uses in Queries
In this section, we will explore the use cases and examples of SQL DISTINCT.
Specifically, we will discuss the following:
- Selecting Distinct Values
- Removing Duplicate Rows
- Counting Distinct Values
1. How to Select Distinct Values Using SQL DISTINCT
The SQL DISTINCT keyword is useful when you want to eliminate duplicate values and list only the different ones.
The syntax for selecting unique values is as follows:
SELECT DISTINCT column1, column2, ...
FROM table_name;For example, you can select unique values from the salary column in an employees table like this:
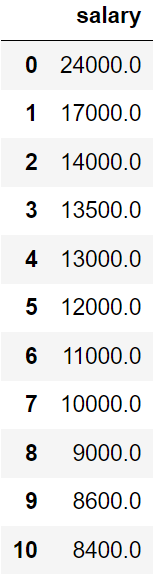
SELECT DISTINCT salary
FROM employees
ORDER BY salary DESC;This will return 32 unique or distinct values in the column salary, arranged in descending order:
2. How to Remove Duplicate Rows Using SQL DISTINCT
When using SQL databases, it is common to encounter duplicate rows in the result set. The SELECT DISTINCT clause can help filter out these duplicates and return a clean set of unique rows. This applies to both single and multiple-column selections.
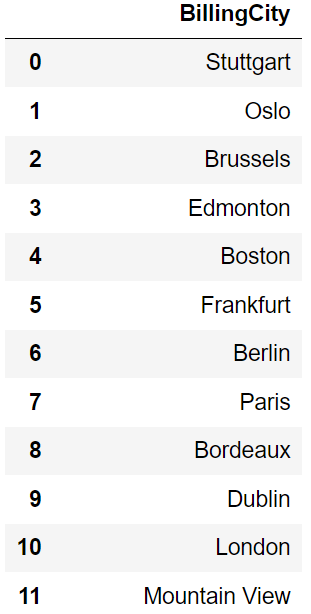
For instance, suppose you want to view the list of cities where you receive orders from. You can write the query as follows:
SELECT DISTINCT BillingCity
FROM invoices;This query returns 52 unique rows containing the cities from where orders were received.
3. How to Count Distinct Values Using SQL DISTINCT
You can also use the DISTINCT keyword within aggregate functions, such as COUNT(), to count the number of unique values present in a column.
The syntax for this operation is:
SELECT COUNT(DISTINCT column) AS AggregateName
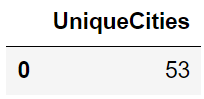
FROM table_name;If you want to count the number of distinct cities in the invoices table, you can use the following query:
SELECT COUNT( DISTINCT BillingCity) as UniqueCities
FROM invoices;This query will return the count of unique cities:
Combining SQL DISTINCT with Other Clauses
In this section, we will explore how to combine the SQL DISTINCT clause with various other clauses.
We will go over the following:
- DISTINCT with WHERE
- DISTINCT with ORDER BY
- DISTINCT with GROUP BY
- DISTINCT with JOIN
1. How to Combine SQL DISTINCT With WHERE
The DISTINCT clause can be combined with the WHERE clause to filter and show only unique values based on specific conditions. This is useful when you want to return a list of unique values that meet certain criteria.
For example, let’s see how you can get the list of unique order totals for a particular city from the invoices table:

SELECT DISTINCT Total
FROM invoices
WHERE BillingCity = 'Berlin';In this example, the query returns unique values from Total where the value in BillingCity is equal to ‘Berlin’.

2. How to Combine SQL DISTINCT With ORDER BY
When you want to order the unique results from a query, you can use DISTINCT with the ORDER BY clause. This combination ensures the distinct results are displayed in the desired sorting order.
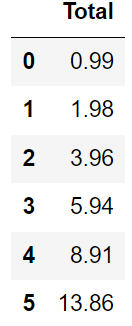
Let’s extend the example above in which we find out the list of unique order totals coming from Berlin:
SELECT DISTINCT Total
FROM invoices
WHERE BillingCity = 'Berlin'
ORDER BY Total ASC;In this example, the query fetches unique values from Totals and orders them in ascending order.
3. How to Combine SQL DISTINCT With GROUP BY
The DISTINCT clause is often used with the GROUP BY clause to return unique values or unique combinations of multiple columns while applying aggregate functions. However, when using the GROUP BY clause, the DISTINCT keyword can be omitted because it is already implied.
Here’s an example:
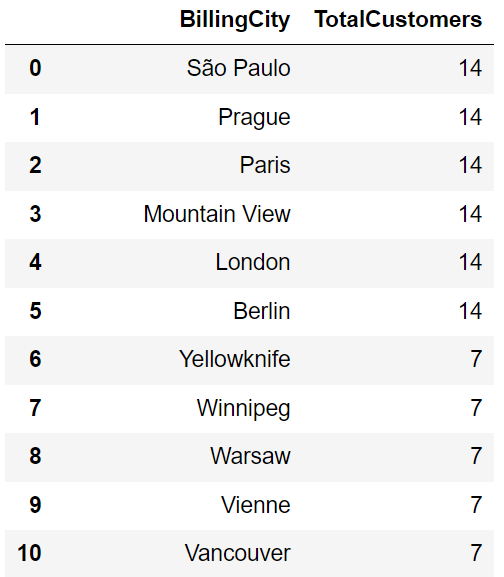
SELECT BillingCity, COUNT(CustomerId) AS TotalCustomers
FROM invoices
GROUP BY BillingCity
ORDER BY TotalCustomers DESC;In this example, the query groups the data in invoices table by BillingCity and counts the occurrences of unique values in CustomerID for each group. The output is a list of distinct BillingCity values and their corresponding counts in CustomerID.
4. How to Combine SQL DISTINCT with JOIN
You can combine DISTINCT with JOINs to retrieve unique values from multiple tables that meet specific joining conditions. This is helpful when you want to avoid duplicate values from the joined tables.
Here’s an example:
SELECT DISTINCT t1.column1, t2.column2
FROM table1 t1
JOIN table2 t2 ON t1.column3 = t2.column3;Let’s break this down:

In this example, the query fetches unique values from column1 of table1 and column2 of table2 where the joining condition column3 matches.
How to Handle NULL Values in SQL DISTINCT
In this section, we will explore how to handle NULL values in SQL DISTINCT. We will go through a 2 step process of understanding NULL values and then handling them.
1. Distinct and Null Values in the Result Set
When using the DISTINCT keyword in SQL, it’s important to understand how it handles NULL values. The purpose of DISTINCT is to eliminate duplicate records in a result set and only return unique values.
However, when it comes to NULL values, DISTINCT does not eliminate them but rather treats them as unique values.
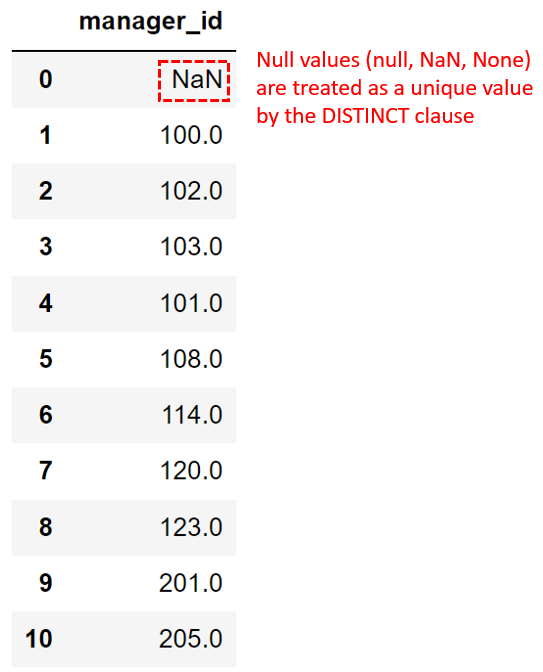
For example, consider the following example using the table employees:
SELECT DISTINCT manager_id
FROM employees;The result set would include the null value (NaN):
2. Filtering Null Values
To exclude NULL values from the result set when using DISTINCT, you can use the WHERE clause with the NOT NULL operator.
Let’s consider the same example as above, and run the following query to filter out NULL values:
SELECT DISTINCT manager_id
FROM employees
WHERE manager_id IS NOT NULL;As a result, the NULL values will not appear in the result set:

Final Thoughts
The DISTINCT keyword is an indispensable tool for efficient data retrieval and analysis.
As we have seen in this guide, its simple addition to SQL queries can vastly simplify working with duplicate information in large databases.
By, using DISTINCT, you can cut through redundant data and focus on the unique values relevant to your analysis.
Also, by combining it thoughtfully with filtering, sorting, and grouping clauses, you can fine-tune your results to contain precisely the distinct information you need.
And, by carefully incorporating the SELECT DISTINCT statement into properly constructed queries, you can streamline your database management within your organization.
Remember, better queries also make data analysis work better, not just in SQL databases, but in tools like PowerBI too.
Frequently Asked Questions
In this section, you’ll find some frequently asked questions that you may have when working with SQL Distinct.

What is the difference between DISTINCT and UNIQUE in SQL?
In SQL, the DISTINCT keyword is used in the SELECT statement to eliminate duplicate rows from the result set, allowing only unique values to be displayed. The UNIQUE keyword is a constraint applied to a table column that ensures that all values in that column are unique across all rows in the table.
How do I combine DISTINCT and IN operators in SQL?
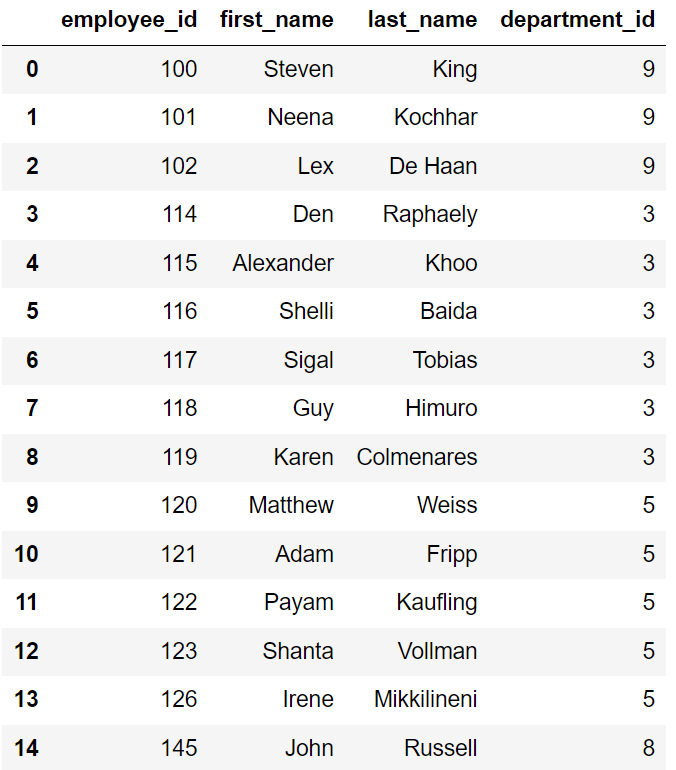
To combine DISTINCT and IN operators in an SQL query, you can use a subquery to select distinct values and then use the IN operator to filter results in the main query. For example:
SELECT employee_id,first_name,last_name, department_id
FROM Employees
WHERE department_id IN (
SELECT DISTINCT department_id
FROM employees
WHERE manager_id = 100
);This query will return all employees that work in the departments where any employee has a manager_Id of 100. This would be useful if, for example, you were interested in looking at departments managed by a specific manager.
Here is the output:
How does DISTINCT work with NULL values in SQL?
When using the DISTINCT keyword, NULL values are considered to be distinct from all other values, and from each other. Therefore, if there are multiple NULL values in the column being selected, DISTINCT will return only one NULL.


