
Text manipulation is an important skill in Python programming because it helps you work with, understand, and change text data easily. One useful built-in tool Python has is the .split() method or string split method, which lets users break up string data types by using special characters called delimiters.
The string split method in Python is a string method for splitting a string into a list of substrings based on a specified delimiter. This method lets you extract specific pieces of information and perform further analysis or processing.
In this guide, we will explore the .split() method in detail, providing you with clear examples of its usage and showcasing its versatility in various scenarios. We will also discuss some common use cases and potential pitfalls you might encounter while using this method.

So, whether you’re a seasoned Python programmer or a beginner looking to expand your knowledge, let’s dive into the world of text manipulation using the .split() method in Python.
Let’s go!
What are the Basics of the .split() Method?

The .split() method is a built-in Python function that divides a given string into smaller parts called substrings. This method is useful when you need to separate words or values in a text string based on certain characters, known as delimiters.
The basic syntax is:
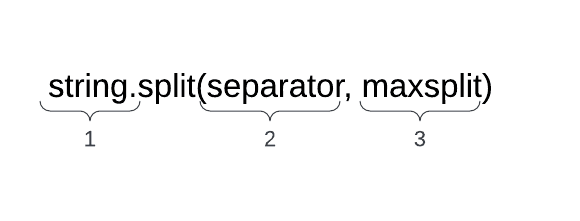
- string: The iterable object you want to split.
- separator: The separator parameter is the delimiter the method will use to split the string. You can choose a custom delimiter (comma, period, or any other character) by adding it as an argument inside the parentheses of the .split() method. If there is no specified separator, it will automatically use a space character as the default delimiter, meaning the method will split the string wherever it finds space.
- maxsplit: The maxsplit parameter is an integer value that specifies the maximum number of times the string should be split. The default value is -1, which means there is no limit on the number of splits.
After splitting the string, the .split() method returns a list of substrings. Each item in the list is a separate part of the original string that was divided based on the delimiter. You can then use this list for further processing or analysis in your code.
The .split() method is widely used in data science in the domain of processing texts in tables. In the next section, we’ll take a look at some examples of the .split() method.

How Do You Use the .split() Method?

To help you better understand the .split() method and its practical applications, we will now provide several examples demonstrating different ways to use this function on Python strings.
By exploring these examples, you will gain insight into how the .split() method works with different delimiters, multiple delimiters, and limiting the number of splits, allowing you to effectively manipulate text data in various situations.
1. Splitting a String Using the Default Delimiter
The .split() method uses a space character as the default delimiter, so the method will split the string anywhere there is a space.
text = "Welcome to the world of Python"
words = text.split()
print(words)The output will be:
['Welcome', 'to', 'the', 'world', 'of', 'Python']In this example, the .split() method separated the string into a list of words using the space character as the default separator. The Python print function outputs a list containing each of the words as substrings.
2. Splitting a String Using a Custom Delimiter
Now, let’s split a string using a custom delimiter, such as a comma.
data = "apple,banana,orange,grape"
fruits = data.split(',')
print(fruits)The output will be:
['apple', 'banana', 'orange', 'grape']Here, the .split() method split the string into a list of fruit names using the comma as the delimiter.
3. Splitting a String with Multiple Delimiters
In some cases, you may need to split a string that has multiple delimiters. In the following example, the string has both commas and semicolons:
mixed_data = "apple,banana;orange,grape;pear"
items = mixed_data.replace(';', ',').split(',')
print(items)The above code snippet output will be:
['apple', 'banana', 'orange', 'grape', 'pear']In this example, we first replaced the semicolon with a comma using the .replace() method and then used .split() with the comma delimiter to split the string into a list of items
4. Limiting the Number of Splits
Sometimes, you may want to specify the maximum number of splits made by the .split() method. You can do that by providing a second argument to the method.
sentence = "This is an example of limiting the number of splits."
limited_words = sentence.split(' ', 3)
print(limited_words)The return value will be:
['This', 'is', 'an', 'example of limiting the number of splits.']In this example, we limited the .split() method to only perform 3 splits, resulting in a list with 4 items.
Through these examples, we hope you’ve gained a clearer understanding of how the .split() method can be used to manipulate text in Python.

By applying the .split() method in various scenarios, such as using default or custom delimiters, handling multiple delimiters, and limiting the number of splits, you can effectively handle a wide range of text-related tasks.
Remember to experiment and practice using the .split() method to improve your skills in text manipulation and tackle complex problems with ease. In the next section, we’ll take a look at some common use cases for the .split() method.
4 Common Use Cases for the .split() Method

Now that we have a good understanding of how the .split() method works in Python, let’s explore some common real-world scenarios where this method can be especially useful.
By examining these use cases, you’ll see how the .split() method can be applied to various tasks, such as parsing files, extracting data from logs, and preparing text data for machine learning and natural language processing.
1. Parsing CSV and TSV Files
One common use case for the .split() method is parsing CSV (Comma Separated Values) or TSV (Tab Separated Values) files. These files contain data in a tabular format, where each line represents a row and values are separated by a specific delimiter.
csv_data = "Name,Age,Location\nAlice,30,New York\nBob,25,Los Angeles"
rows = csv_data.split('\n')
for row in rows:
values = row.split(',')
print(values)The output for the above code will be:
['Name', 'Age', 'Location']
['Alice', '30', 'New York']
['Bob', '25', 'Los Angeles']In this example, we first split the text data into rows using the newline delimiter (‘\n’), and then split each row into individual values using the comma delimiter.
2. Extracting Data from Log Files
Log files often contain valuable information for debugging and analyzing the performance of an application. The .split() method can be used to extract specific pieces of information from log entries.
log_entry = "2023-04-22 12:34:56,INFO,User login successful,user123"
fields = log_entry.split(',')
timestamp, log_level, message, username = fields
print(f"Timestamp: {timestamp}\nLog Level: {log_level}\nMessage: {message}\nUsername: {username}")The output will be:
Timestamp: 2023-04-22 12:34:56
Log Level: INFO
Message: User login successful
Username: user123In this example, we used the .split() method to extract the timestamp, log level, message, and username from a log entry by splitting the string with a comma delimiter.
3. Analyzing and Preprocessing Text Data for Machine Learning
When working with machine learning, preprocessing and cleaning text data is often necessary. The .split() method can be used to tokenize text, which means breaking it into individual words or tokens.
text = "Natural language processing is a subfield of artificial intelligence."
tokens = text.lower().split()
print(tokens)The output will be:
['natural', 'language', 'processing', 'is', 'a', 'subfield', 'of', 'artificial', 'intelligence.']In this example, we first converted the text to lowercase using the .lower() method and then used the .split() method to tokenize the text into words.
4. Tokenizing Text for Natural Language Processing
Natural Language Processing (NLP) tasks, such as sentiment analysis or text classification, often require text tokenization. The .split() method can be used to quickly tokenize text into words or phrases.
sentence = "Chatbots are becoming increasingly popular for customer support."
words = sentence.split()
print(words)The output will be:
['Chatbots', 'are', 'becoming', 'increasingly', 'popular', 'for', 'customer', 'support.']In this example, we used the .split() method to tokenize the sentence into words. This can be the first step in preparing text data for various NLP tasks.
As demonstrated by these common use cases, the .split() method is an invaluable tool for handling a wide range of text manipulation tasks in Python. By effectively applying the .split() method, you can streamline your workflow and improve your ability to work with text data.
As you continue to explore Python and its text manipulation capabilities, you’ll likely find even more ways to utilize the .split() method in your projects.
3 Potential Pitfalls of the .split() Method and Their Solutions

While the .split() method is a powerful tool for text manipulation, it’s important to be aware of some potential pitfalls and challenges that you might encounter when using it.
In this section, we will discuss a few common issues and provide solutions to help you avoid these pitfalls, ensuring that you can use the .split() method effectively in your projects.

1. Handling Empty Strings and Missing Values
When using the .split() method, you may encounter situations where the resulting list contains empty strings or missing values. This can happen when there are consecutive delimiters or delimiters at the beginning or end of the string.
data = ",apple,banana,,orange,"
fruits = data.split(',')
print(fruits)The output will be:
['', 'apple', 'banana', '', 'orange', '']The output is not ideal because of the empty strings. To remove those empty strings from the list, you can use list comprehension:
fruits = [fruit for fruit in fruits if fruit != '']
print(fruits)The output will be:
['apple', 'banana', 'orange']2. Dealing with Consecutive Delimiters
In some cases, you may have a string with consecutive delimiters, and you want to treat them as a single delimiter. To achieve this, you can use the .split() method along with the ‘re’ (regex or regular expressions) module.
import re
text = "This is an example with multiple spaces."
words = re.split(r'\s+', text)
print(words)The output will be:
['This', 'is', 'an', 'example', 'with', 'multiple', 'spaces.']In this example, we used the re.split() function with the regular expression \s+, which matches one or more whitespace characters. This allows consecutive spaces to be treated as a single delimiter.
3. Performance considerations when working with large data sets
When using the .split() method with very large data sets, performance can become a concern. To optimize performance, consider using more efficient data structures, such as generators, or processing the data in smaller chunks.
def read_large_file(file_path, delimiter):
with open(file_path, 'r') as file:
for line in file:
yield line.strip().split(delimiter)
file_path = "large_data.csv"
delimiter = ","
for row in read_large_file(file_path, delimiter):
print(row)In this example, we used a generator function called read_large_file() to read and process a large CSV file line by line, reducing memory usage and improving performance.
By being aware of these potential pitfalls and understanding how to address them, you can ensure that your use of the .split() method is both effective and efficient and enhance the versatility and reliability of the .split() method in your Python projects.
Always be prepared to adjust your approach based on the specific requirements of your task and the nature of the text data you are working with. In the next section, we’ll take a look at some advanced techniques and alternatives.
What Are Advanced Techniques and Alternatives of the .split() Method?

There may be times when you need more advanced techniques with the .split() method or even alternatives to address specific challenges or requirements, especially when handling complex algorithms.
In this section, we will explore some advanced techniques and alternative approaches that can enhance your text manipulation capabilities.
1. Using Regular Expressions for More Complex Text Manipulation
In some cases, you might need more sophisticated pattern matching and text manipulation than the .split() method can provide. The 're' module in Python offers powerful functions for working with complex patterns in text data.
import re
text = "This is a #hashtag and another #example of #tags in a sentence."
hashtags = re.findall(r'#\w+', text)
print(hashtags)The output will be:
['#hashtag', '#example', '#tags']In this example, we used the re.findall() function with a regular expression pattern #\w+, which matches hashtags in the text. The pattern consists of the # symbol followed by one or more word characters (\w+).
2. Using the .join() Method for String Concatenation
Sometimes using other Python string methods may be a better alternative. For instance, when you need to combine a list of strings into a single string, the .join() method can be a useful alternative to using the split method in reverse.
words = ["Hello", "world!"]
sentence = " ".join(words)
print(sentence)The output will be:
"Hello world!"In this example, we used the .join() method to concatenate a list of words into a single string, with a space character as the delimiter.
3. Third-party Libraries for Advanced Text Manipulation
There are several third-party libraries available for Python that can provide additional text manipulation functionality. Some popular libraries include:
- NLTK (Natural Language Toolkit): NLTK is a comprehensive library for natural language processing, offering a wide range of tools for text analysis, including tokenization, stemming, and text classification.
- spaCy: A high-performance library for advanced natural language processing, focusing on speed and efficiency. spaCy supports multiple languages and a variety of NLP tasks.
- TextBlob: TextBlob is a simple library for common natural language processing tasks, including part-of-speech tagging, noun phrase extraction, sentiment analysis, and translation.
- NumPy: Another popular third-party library is NumPy. It is primarily designed for numerical computing and working with arrays in Python. While it is not specifically designed for text manipulation, NumPy does offer some limited functionality for working with text data.
- Pandas: Lastly, Pandas is a third-party library in Python designed for data manipulation and analysis. It provides two main data structures: DataFrame and Series, which are used for handling and manipulating structured data, such as tables and time series. It also offers some functionality for working with text data, particularly when it comes to cleaning, transforming, and analyzing data within DataFrames or Series.
By exploring advanced techniques and alternative approaches, such as using regular expressions, the .join() method, and third-party libraries, you can further enhance your text manipulation capabilities in Python.
These additional tools and techniques can help you tackle more complex text-related challenges and provide more flexibility in your text manipulation tasks.
As you continue to work with text data in Python, consider experimenting with these advanced techniques and alternatives to find the best solutions for your specific needs.
Final Thoughts on the Python String split() Method
We’ve covered a wide range of topics to help you effectively use the .split() method in your projects, from understanding the basics of how the method works to examining practical examples, common use cases, potential pitfalls, and advanced techniques.
As you continue to work with text data in Python, remember that the .split() method is just one of many available tools for text manipulation. You can combine it with other built-in methods, regular expressions, and third-party libraries to develop robust solutions for handling even the most complex text-related challenges.
Keep experimenting and exploring the many text manipulation techniques that Python has to offer. You’ll notice they share similarities with other object-oriented programming languages like Java and JavaScript.
With practice and a solid understanding of the available tools, you’ll be well-equipped to tackle any text manipulation task that comes your way!
If you’d like to learn more, check out the Python tutorial playlist below:


