
In this tutorial, you’ll learn about the Power Query Language Flow and some of its best practices. You’ll also learn how to transform your data easily to get the best possible results. Data transformations will optimize your report and make it look compelling.
Set Data Types With No Power Query Language Flow
The bare minimum transformations you should always perform are renaming and setting data types for your columns.

Data types are used to classify values in M. An icon beside the column name shows the assigned data type for a field. In this sample table, you can see an ABC123 icon beside the column names. That icon represents the Any data type which indicates that a data type hasn’t been assigned to that column.
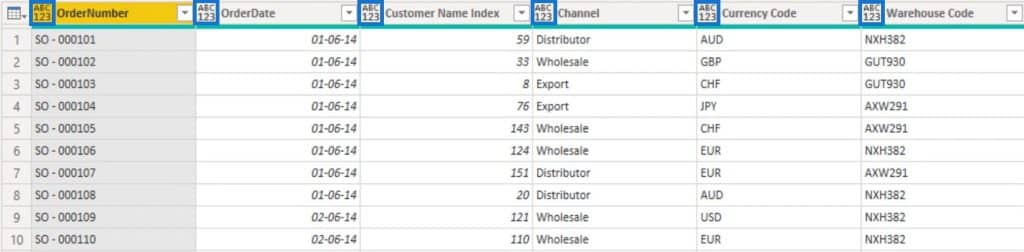
Out of the books, automatic type detection is enabled. This generates Changed Type steps automatically in your queries. Even if that is enabled, always make sure that Power Query guesses the data types correctly for each of the columns across all of your tables.

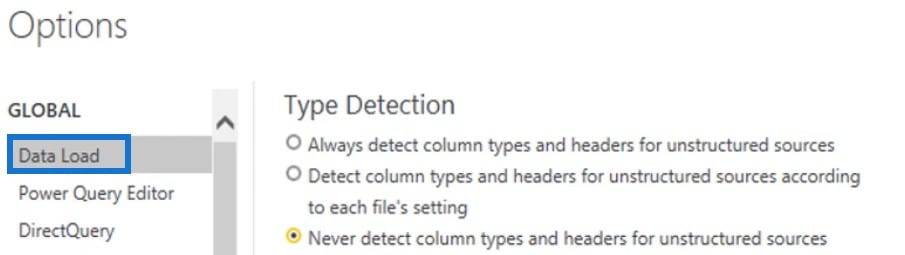
To enable or disable that setting, follow these steps.

Under the Global option, you can select one of the three Type Detection options available to you.
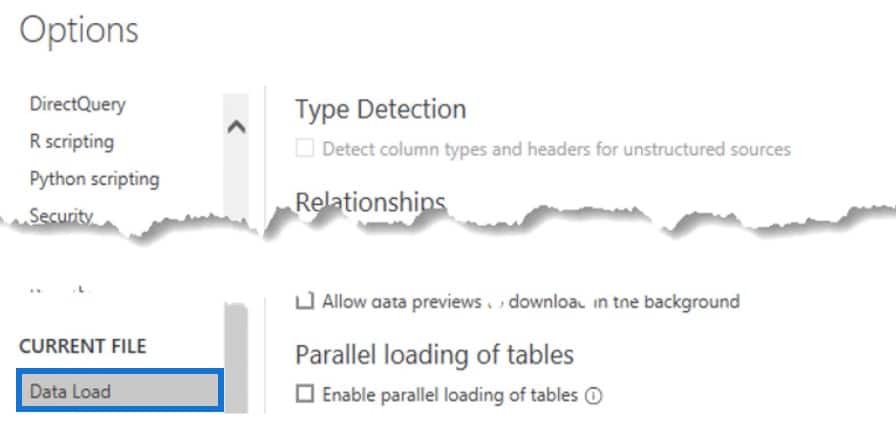
Under the Current File option, you can toggle the options for Type Detection depending on your Global setting.
Set Data Types Using Transform Tab
The user interface offers multiple ways to set data types for your columns. In the Transform tab’s Any Column section, you’ll find the Detect Data Type button.
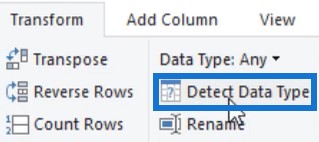
If you select all columns and click that button, it will automatically set the data types of all columns. However, since it only scans the top 200 rows, you still need to validate if Power Query has the correct data type.

If you select a column from your table, you can see its data type in the Any Column section.
If you click the drop-down button and select Text, the icon on the selected column will change from ABC123 to just ABC.
You will then see a Changed Type step in the Applied Steps pane.
In the Home tab, you’ll also find the option to set the data type.
Set Data Types Using Column Header
Another way is to right-click a header and select Change Type. From there, you can choose the appropriate data type for your columns.
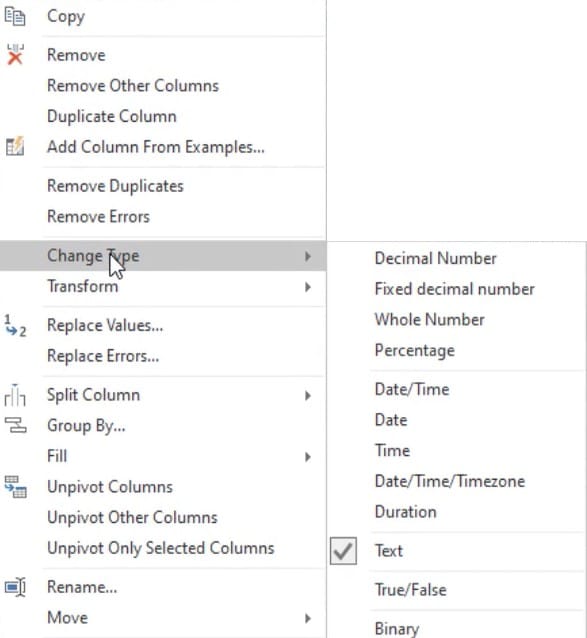
Set Data Types Using Column Icons
The most common way to set data types is to click the icon beside the column name. It will show you all the data types available.
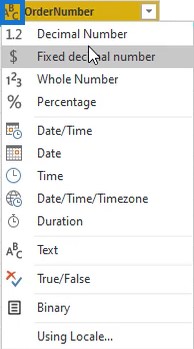
In the sample table, set the data type of the OrderDate column to Date.
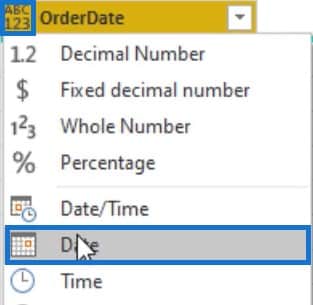
Depending on the data type of the column you select, Power Query provides a set of transformations and options that apply to that specific data type in the Transform tab, Add Column tab, and the Smart Filter section.
So if you select a date column and go to the Transform tab, you’ll see options under the Date button.
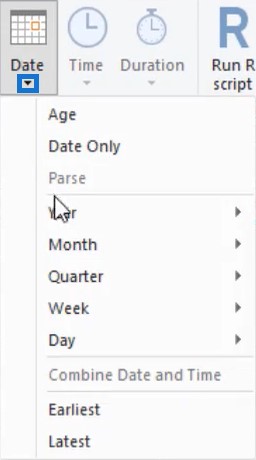
However, if you select a text column, the options under the Date button will no longer be available.
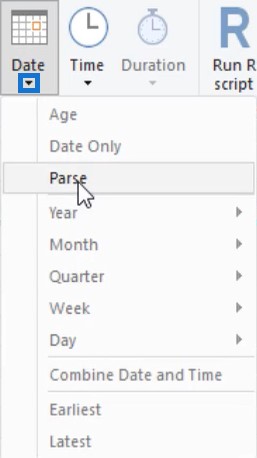
For smart filtering, text columns have text filters and date columns have date filters.
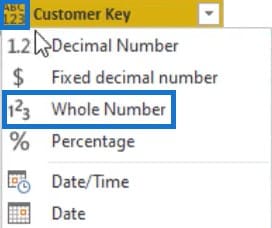
For the next column, change the column name to Customer Key and data type to Whole Number.
Next, change the data type of the Channel, Currency Code, and Warehouse Code columns to Text.
Following that, change the name of the Delivery Region Index to Delivery Region Key and its data type to Whole Number. Then, do the same for the Product Description Index and Order Quantity columns.
Lastly, for the Unit Price, Line Total, and Unit Cost columns, set the data type to Fixed Decimal Number.

Set Data Types With Power Query Language Flow
Because of the changes in the columns, a lot of steps have been created in the Applied Steps pane. The problem is that because of performing the same type of transformations multiple times, the sample table query becomes inefficient. This is something that you should avoid.
To make your query efficient, try to create a single step by applying that specific transformation to all your columns before creating another step.
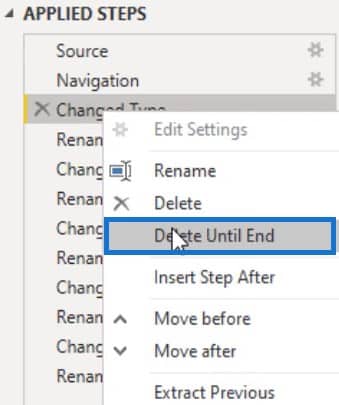
Duplicate the sample table query and rename it Best Practice. In the Applied Steps pane, right-click the first transformation performed in the previous query and select Delete Until End. Then, confirm the deletion of the step in the Delete Step dialogue box.
In addition, here are some best practices. The first thing is to create parameters to contain the data source location. This makes it easier to fix issues when a file name has been changed.
To create parameters, click Manage Parameters in the Home tab and select New Parameter.
Another way is to right-click on the Query pane and select New Parameter.
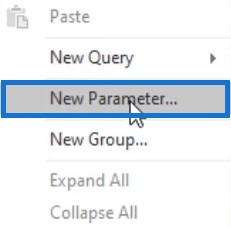
After that, a Manage Parameters dialogue box will appear. Name the parameter FileLocation and set the Type to Text. For the Suggested Values, set it to List of values so you can paste your string and change or add multiple locations that you can switch in between.
Next, go to your File Explorer and select your file. Copy the path and paste in the parameters. Once done, press OK.
Go back to the Best Practice query and click the Source step in the Applied Steps pane. Then, change the hard-coded file path in the formula bar with FileLocation.

Remove Unnecessary Columns
Remove all unnecessary columns to save space and improve performance. Bring only the data that you need because adding tables and columns are much easier than removing them.
The easiest way to do that is through the Choose Columns step in the Home tab. If you click that button, a dialogue box will appear that lets you choose columns to keep. You should design and shape your tables with a specific purpose to best suit the analysis that you’re going to perform.
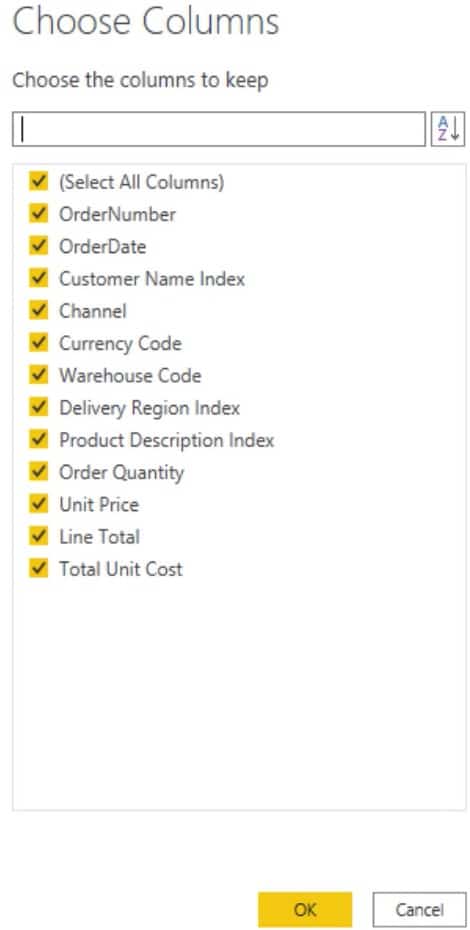
From there, de-select the columns that you don’t need in your table. For this sample table, the cardinality of the OrderNumber column is high. It’s best to de-select that column because it impacts the file size and overall performance.
If you don’t need location data for the analysis of the sample query, it’s also best to de-select the Delivery Region Index. Lastly, since the table already has a unit price and quantity, the Line Total column is not needed.
After de-selecting columns, press OK. If you want to alter the column selection, just clear the gear icon beside the step name in the Applied Steps pane.
Assign Appropriate Data Types To Columns And Limit Rows
Next, assign data types for all columns. Select all columns and click Detect Data Type in the Transform tab.
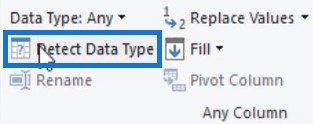
Detect Data Type automatically detects the data types of columns based on the scan of the top 200 rows. So, check and make sure Power Query sets the correct data types.
It’s best practice to limit the number of rows. If your financial year starts on July 1, you can omit the data from June or set up a parameter.
However, there’s a catch if you want to be able to change a parameter value in the Power BI service. After you publish your report, your parameter values need to be either a Text type or a Decimal type.
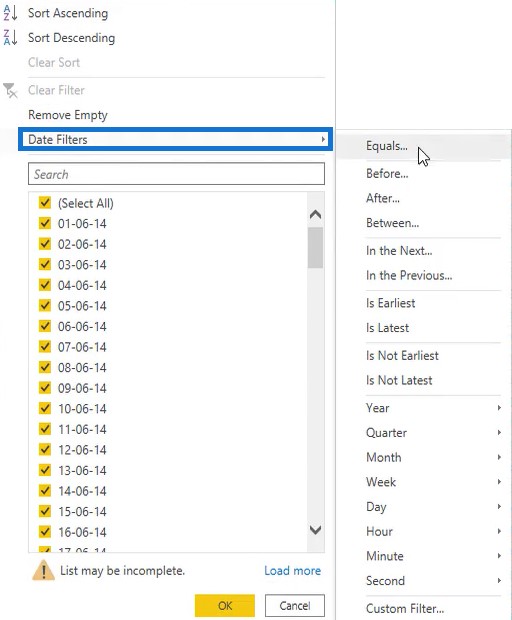
To deal with that, create a filter on the data by clicking the drop-down button in the OrderDate column. Next, click Date Filters and select After.
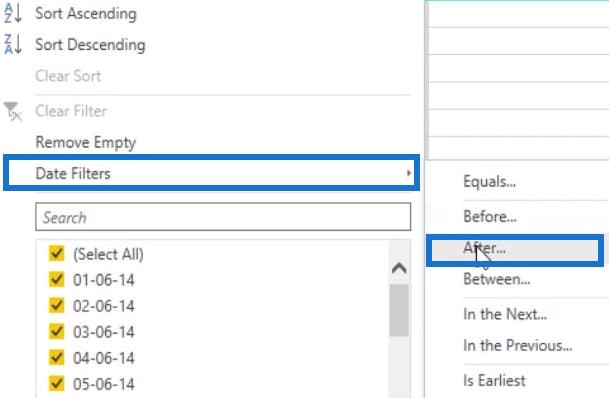
In the dialogue box, change the first parameter to is after or equal to and then input the date. In this example, the date entered was July 1, 2014.

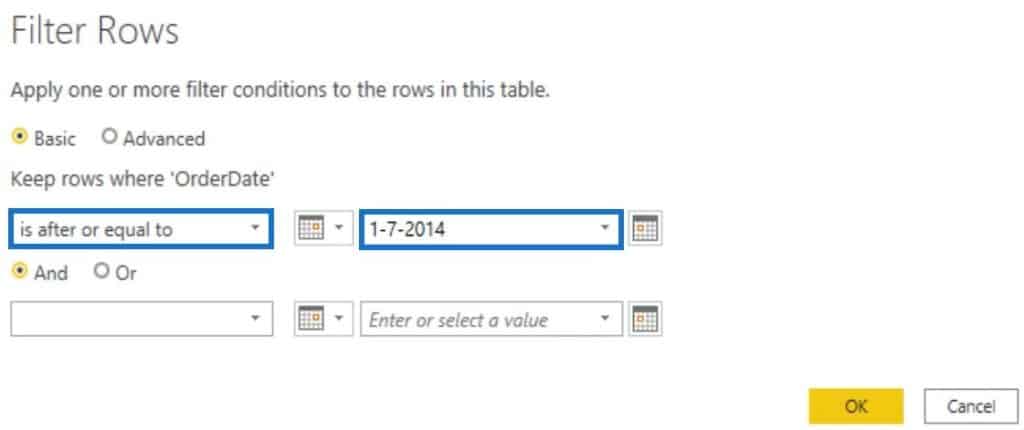
After you press OK, the filter will then be applied in your table. Next, create a parameter and name it DatesFrom. Set the Type to Text and input the date in the Current Value parameter.
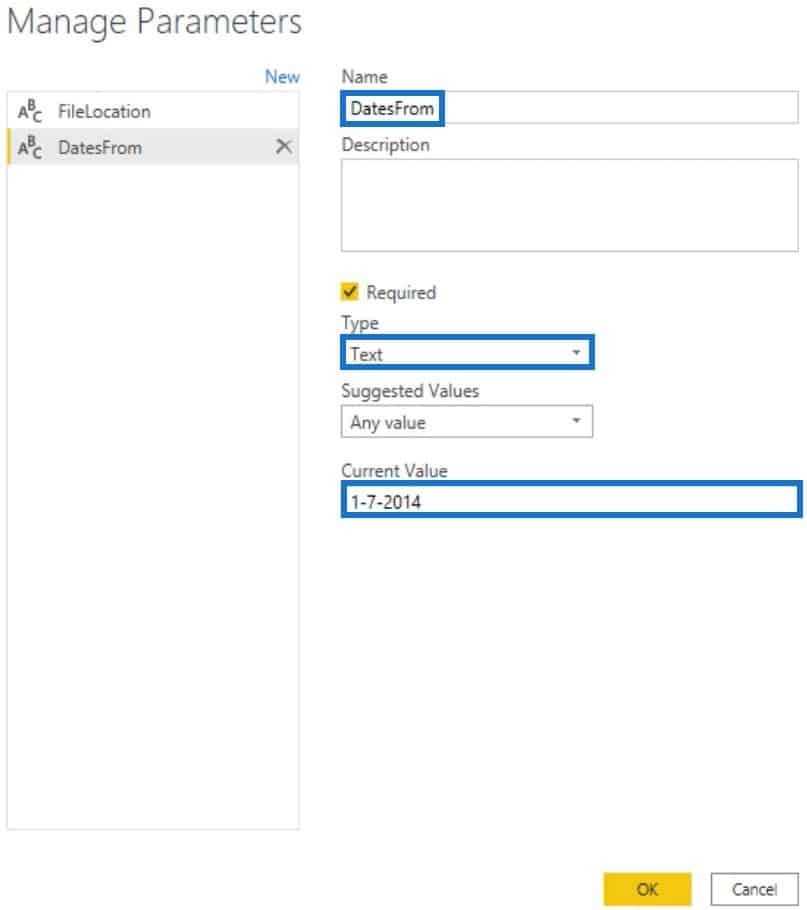
Now, go back to the Best Practice query and replace the intrinsic #date with Date.From(DatesFrom).

Clicking the check sign without the Date.From function will return an error. That is because DatesFrom is a Text type while the field has a Date type. The Date.From function converts Text to Date.
Rename all the columns that won’t be hidden in the data model. The name needs to be concise, self-describing, and user-friendly. Keep in mind that you’re designing a data model for people who are going to use your report.

Consolidate Redundant Steps In The Power Query Language Flow
The next thing to do is to consolidate redundant steps (such as, rename, remove, and change column data types). Moreover, steps like reordering columns are things that you should pay attention to when looking for redundancies.
The tables that you load to the data model are never displayed in your report. That makes the column order irrelevant.
Another best practice is to rename your steps in the Applied Steps pane. The names of the steps are self-describing and are used as variables in the M code.
Names that contain spaces or special characters are written using the quoted notation. It means that the names are enclosed in a set of double quotes and they have the hash or pound sign in front of them, which makes the M code hard to read. You can omit the spaces or place an underscore between them.
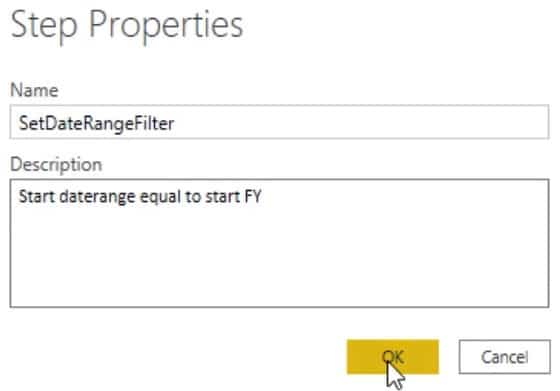
Adding additional documentation details by putting comments in the Advanced Editor window is also a best practice in Power Query. You can also do it in the Step Property Description. They are shown as tooltip annotations when you hover over a step with an exclamation mark in the Applied Steps pane.
Knowing why you made a certain choice in the initial development is extremely helpful when you have to revisit a file after some time. To add documentation details, right-click a step in the Applied Steps pane and select Properties.
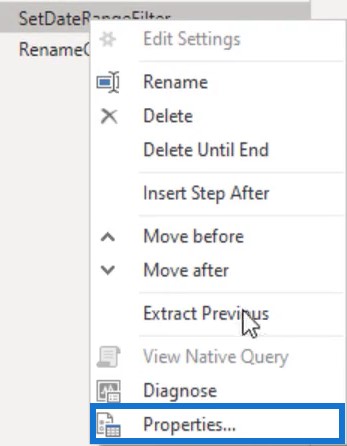
A Step Properties dialogue box will appear where you can write the reason for filtering or transforming.
Organize Queries For A Better Power Query Language Flow
One of the most common best practices in Power Query is organizing your queries. Create folders for parameters, functions, staging queries, and queries that will be loaded to the data model. In this example, select the FileLocation and DatesFrom queries and right-click on them. Then, select Move To Group and click New Group.
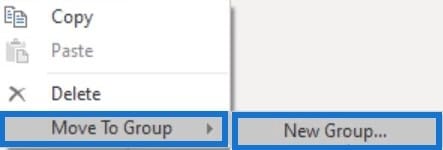
Next, add a name for the selected queries and press OK.
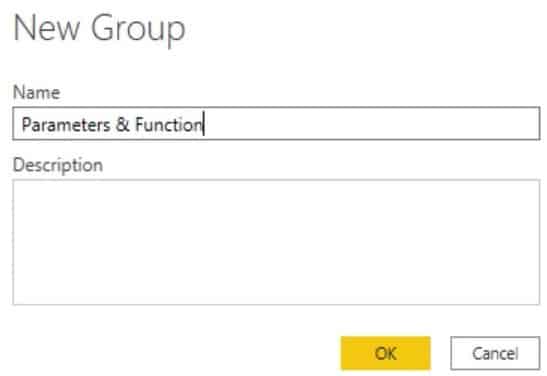
After grouping your queries, your Query pane will look like this.
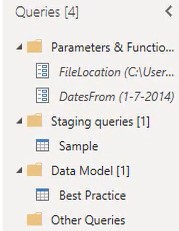
For all your staging queries, make sure to disable the load by unchecking the Enable Load.
Another thing to discuss in this tutorial is the language flow. Each of the steps in the Applied Steps pane transforms a value which you can see when you click them.
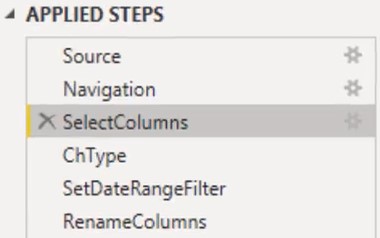
The initial data came and started in the Navigation step, and columns were selected. Next, data types were changed and a date range was set. Columns were also renamed.
All of the steps return a table type value. If you open the Advanced Editor window, you’ll see a let expression and an in clause. In between them, there’s a list of steps or variable names with expressions assigned to them.
The query returns whatever follows the in clause which refers to the final step in your variable list. The M engine will then follow the dependency chain back from the in clause to eliminate anything that’s unnecessary and to push transformations back to the source if possible.
Summary Of The Power Query Language Flow
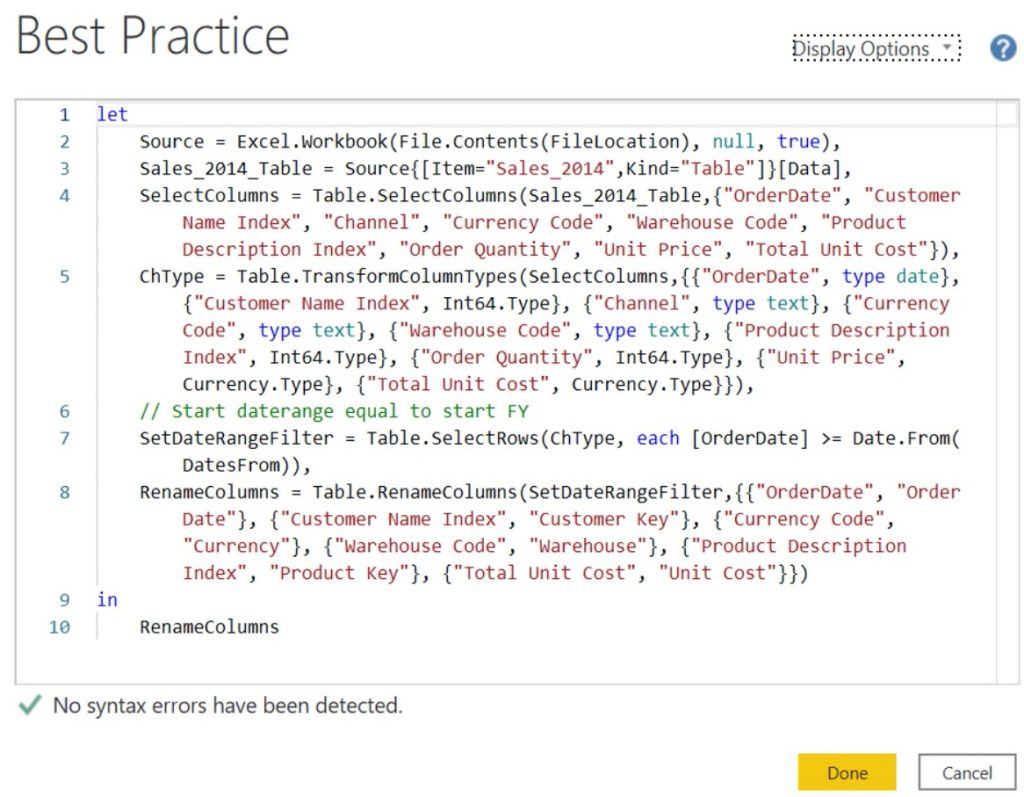
If you look at the formula, you can see the flow of the steps done in the query. You’ll also see the functions used by the user interface in each step.
The first step that was made in the query was the column selection. When the step was performed using the user interface, the Table.SelectColumns function was called. As its first parameter, it took a table which referenced the variable name of the previous step. Then, it listed all the selected column names.
The second step transformed the column types by calling the Table.TransformColumnTypes function. Its first parameter called the output of the previous step. It then listed a set of transformation lists.
The third step set a date range filter using the Table.SelectRows function. It took a table type query as its first argument. In this example, it referenced the output of the Change Type step.
The last step renamed the columns using the Table.RenameColumns function. The output of the previous step was used as its first argument. Then, it listed a set of renaming lists.
All the functions applied through the user interface start with the word Table. They all took a table value as first parameter and then transformed that value.
Although the code looks sequential because each step refers the previous step, the sequence isn’t required. If you move a step around, the query will still run because the M engine always follows the dependency chain.
Having the user interface is convenient but it will always assume that you want to transform the results of the previous transformation. In most cases, that will probably be true and in the off chance that it isn’t, you’ll have to manually update that referenced value in the code.
***** Related Links *****
Power Query Data Types And Connectors
Power BI Datasets: Types And Naming Conventions
Data Loading And Transformation Best Practices
Conclusion
Data transformation is necessary to keep your data grouped and organized. It makes data development faster because you can easily trace problems in the Power Query language flow and modify changes in your report.
Melissa


