
I’d like to continue exploring the dynamic uses of the DAX function COLUMNSTATISTICS() – a new, almost entirely undocumented DAX function added to Power BI in August 2021 that has some very unique aspects that I think will be very interesting to get familiar with. You can watch the full video of this tutorial at the bottom of this blog.
I’ve done a lot of experimentation and learned some really interesting new things about how this function works and what you can do with it. In my first blog about this function, I talked about some static uses. Today, I’m going to talk about some really pretty amazing dynamic uses of the function in ways that even IntelliSense is not yet up to date on.

How The DAX Function COLUMNSTATISTICS Works
For every table and field in your data model, COLUMNSTATISTICS produces a table of six additional fields that has a table name, column name, min and max values for the column, cardinality, and a max length. That doesn’t seem like a lot of data, but there’s a lot you can do with that.
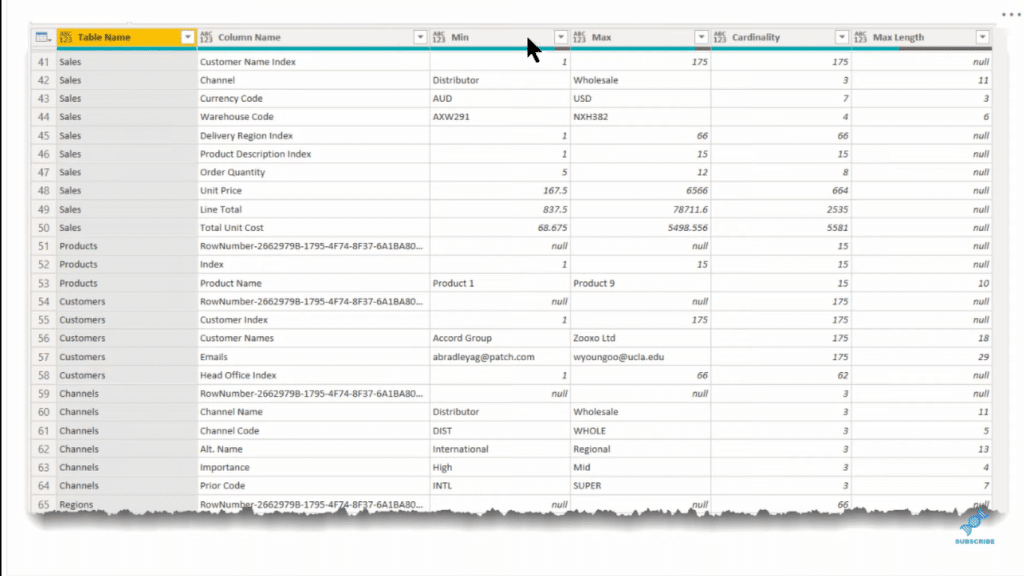
The data that I’m currently using is just the practice data set for the Enterprise DNA External Tools. It’s a relatively simple data model with five dimension tables, a fact table, and a measure table. A model like this is not that hard to keep track of, but a complex model needs a much more complex dataset monitoring.
The metadata for a complex dataset becomes a lot more important in terms of looking at cardinality, which is the number of unique values within a field. It has a big influence on the size of your model as well as potentially the speed of processing.
In addition, as you’re building a model, it helps to know not just the number of tables, but the date range of those tables. As you build out your Dates table, you’re making sure to cover the full range of data in your fact table.
And so, for this example, let’s try to add a table to this data model that I’m working on. In the Power Query, we’ll go New Source, then Blank Query. And then, we’ll go into the Advanced Editor and I’m just going to paste in a function that is called List.Dates. We’re going to use that to create a table of the cardinality of 10,000, so that’s 10,000 unique dates.
It’s going to return a 10,000-item list and we can just convert that to a table, and then rename that table.
We can change the field up here to date. And if we click on Close and Apply, we’re going to see that our smart narrative is going to update dynamically, without having to refresh the entire model (like we do in the past).

The reason why this is fully dynamic is that we’re doing it all with measures. The interesting thing is that it shows a lot of errors, and the function is so new that IntelliSense is not picking it up properly, but it actually does work.
Let’s go into Tabular Editor 3, which I think is the best way to figure out what the complex DAX measures are actually doing.
Remember that the DAX query returns tables rather than scalers. So, if we take this measure and copy this over into a DAX query, it shows an error because the Result here is still a scaler. We can use the debugging approach of replacing that RETURN Result with individual components of the measure.
In this case, we’ll replace it with ColStats, which what we’ve done at the top is just put that COLUMNSTATISTICS DAX function into a variable. With that, we get exactly what we expect, which is the standard column statistics table.
And now, we want to just look at the Table Name column, and we want to take the distinct values out of that and count those. That’s going to be the number of tables in our data model.
First, we’ll select columns on our ColStats table, and just return that table name field. Typically, in a DAX measure or a DAX query, you want to return a field name with the table name in front of it. But in this case, we don’t know what the appropriate table name references because it only exists virtually. It doesn’t seem to accept the variable name as the table name.
So in this case, we’ve got to stay with what looks like a measure, but it’s actually a column reference without the table reference in front of it. And that still works even though it’s confusing in the nomenclature. Now, if we replaced this RETURN statement with our TabCol, we get exactly what we expect, which is that model tables field.
And then for the Result, we’re just doing a count of the distinct table columns. So, if we replace this with DISTINCT(TabsCol), we get our seven tables.
Now let’s take a look at the highest cardinality in the highest cardinality table and see how we got those. This is actually an important pattern that you can use for a lot of different things where you’re looking for, not just the max number, but the max attribute associated with that number.
So let’s take a look at the MaxCardinality. Even though this is a scaler, we can turn it into a one-cell table by just putting brackets around it. And if we hit five, we’ll see that’s the cardinality value of 10,000.
So now the question is, how do we take this and return the table associated with that cardinality.
To do that, we use this very common pattern using TOPN. We then copy it over to our RETURN statement and it will give us the row we were expecting to get, which is the 10,000 Dates column. Instead of getting one row (because it’s TOPN), we get two because there’s a tie.
What ColStats also does is it creates, for every table, an index in a hidden index row called RowNumber with that being a unique identifier for each row of the table. So that MaxCardinality is always going to be mirrored by the RowNumber if that is a unique identifier.
And so, it doesn’t really matter that we’ve got two rows because what we’re looking at is the Max of Table Name. And that max is there just to return some value that otherwise this would just be a naked column. But we need to put some aggregation around that, and in this case, we use MAX.
Then, if we place MaxCardinality in our RETURN statement, and put it in brackets to return a table rather than a scaler, it returns the value of Test.

This TOPN DAX pattern is a really good pattern to remember when you want to basically figure out a max or a min value, and then return an attribute associated with that min or max.
***** Related Links *****
Optimize Power BI Formulas Using Advanced DAX
DAX Measure Analysis: Breaking Down Long DAX Measures
DAX Measures In Power BI Using Measure Branching
Conclusion
I’ve given you the general approach and context that we can use in terms of you making the best use of the DAX function COLUMNSTATISTICS in a dynamic way. Being able to track this dynamically in terms of a complex model, I think there’s tremendous value in this function.
The more we experiment with COLUMNSTATISTICS function, and with its ability to dynamically handle metadata within DAX, I think the more interesting uses we’re going to find. So if you’ve already found some interesting uses for this DAX function, please let me know in the comments below.
All the best!
Brian
[youtube https://www.youtube.com/watch?v=8JtPYkRyaDM&w=784&h=441]


