
In this blog, we’re going to discuss text analysis in Python for creating constructed data from text content. This will help you in analyzing large amounts of data and consume less time in working on certain tasks. You’ll also acquire knowledge about textblob which deal with natural language processing tasks.
Text analysis is the process of analyzing texts by using codes for automated processes of producing and grouping text data.
Before we proceed, you may have to install the library that we’ll be using in this tutorial.

Implementing Text Analysis In Python
Let’s begin by importing textblob. Remember to document what you’re doing with the use of comments.
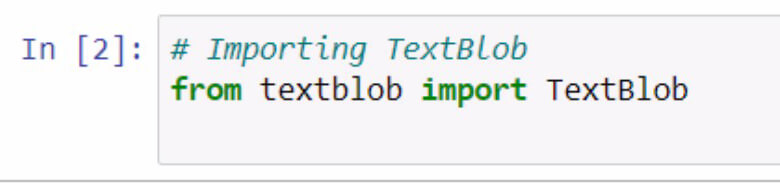
By running the code above, we now have access to the textblob library. The next step we’re going to do is to create a sentence that we’re going to use for our examples. We’re going to do this by storing a sentence in a variable named sentence.
Remember to enclose the sentence that you want to add with double-quotation marks.

The textblob is a great library where we can create a blob and use some of its functions for our text analysis in Python.

In creating the blob, we start by creating a variable and naming it blob. In this variable, we need to add TextBlob which is the library that we’re using.
Inside the parentheses, we’ll utilize the sentence variable which holds the sentence that we created earlier. Take note that you can opt to manually type the sentence itself inside the parentheses for this part.
To check what this blob variable does, you can simply initialize it by typing the variable name and pressing the Shift + Enter keys. The output should be similar to the example below.


As you can see from the result, the sentence that we stored in the sentence variable is now contained by TextBlob.
Tokenizing Text Data In Python
If you want to remove some words in a sentence, we can separate each of these words into individual parts in a list. With this given sentence, what we’re going to do is tokenize them or separate each word and put it in a list.
To do this, we’re going to utilize the blob variable and use the tokenize function. Then we’ll store it in a variable named words.

Let’s initialize the words variable the same way that we did in initializing the blob variable to see what is in the tokenized list.

As you can see, each of the words, and even the punctuation marks are now separated in a list. This is how the tokenize function works.
Now that we have a list of words, we can then perform another function from it. Let’s create another list of words that we don’t want to be included in our list like punctuations and articles. To perform this step, refer to the screenshot below.

In creating the list of stop words, we used brackets to enclose the list of stop words. Then each of the stop words is enclosed with single quotes and each is separated by a comma. We stored the list in the stop_words variable.
From here, we’re going to perform a list comprehension to remove words that are necessary for conducting text analysis in Python. This includes cleaning sentences, tokenizing, and comparing different lists. We’re now going to compare these two lists and create a new list of clean_tokens.

In the code presented above, we utilized a placeholder which is w to represent an element. What we’re trying to do in this part is to get the element in the words variable if the element is not existing in the stop_words variable. If we’re going to initialize clean_tokens, this will be the result.

In this process, we’re able to clean our tokens by putting in a process of removing unnecessary tokens such as punctuations and articles. Because of that, we only have the essence words left on our list.
Joining Tokens To Form A Sentence In Python
Now that we have separated the clean tokens, let’s try putting them altogether in one sentence. To do that, we have to utilize the .join function. Check the example below for reference.

In the example above, we created a variable named clean_sentence to hold our clean tokens that will be combined into a sentence. You can also notice that we added a space enclosed by double-quotations and the .join function. Inside the parameters, we included the clean_tokens variable.
This will be the output if we initialize the clean_sentence variable.
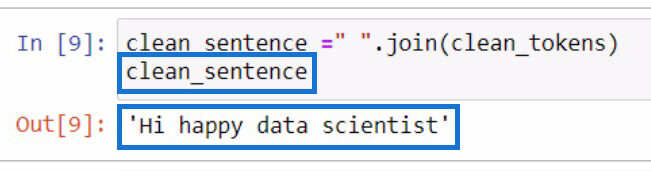
Noticeably, the sentence doesn’t look right because we removed the articles and punctuations earlier.
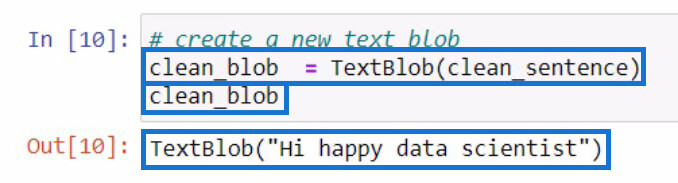
After creating the clean_sentence, let’s try creating a new textblob containing the clean_sentence that we just created. Then we’ll store it in a new variable clean_blob.

Dissecting A Textblob For Parts Of Speech Using .tags Function
From this analysis blob, we can use the pieces of this blob to check for parts of speech or make even more changes. Let’s try checking the parts of speech of each word in our new textblob.
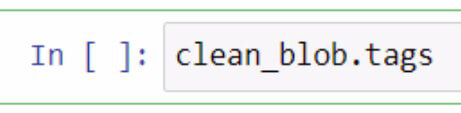
In order to check the parts of speech in a textblob, you should use the .tags function. I did this by utilizing our clean_blob variable then I added the .tags function right after.
If ever you receive an error message upon initializing the .tags function, just read and follow the steps in order to fix the error. In this case, this is how it looks.
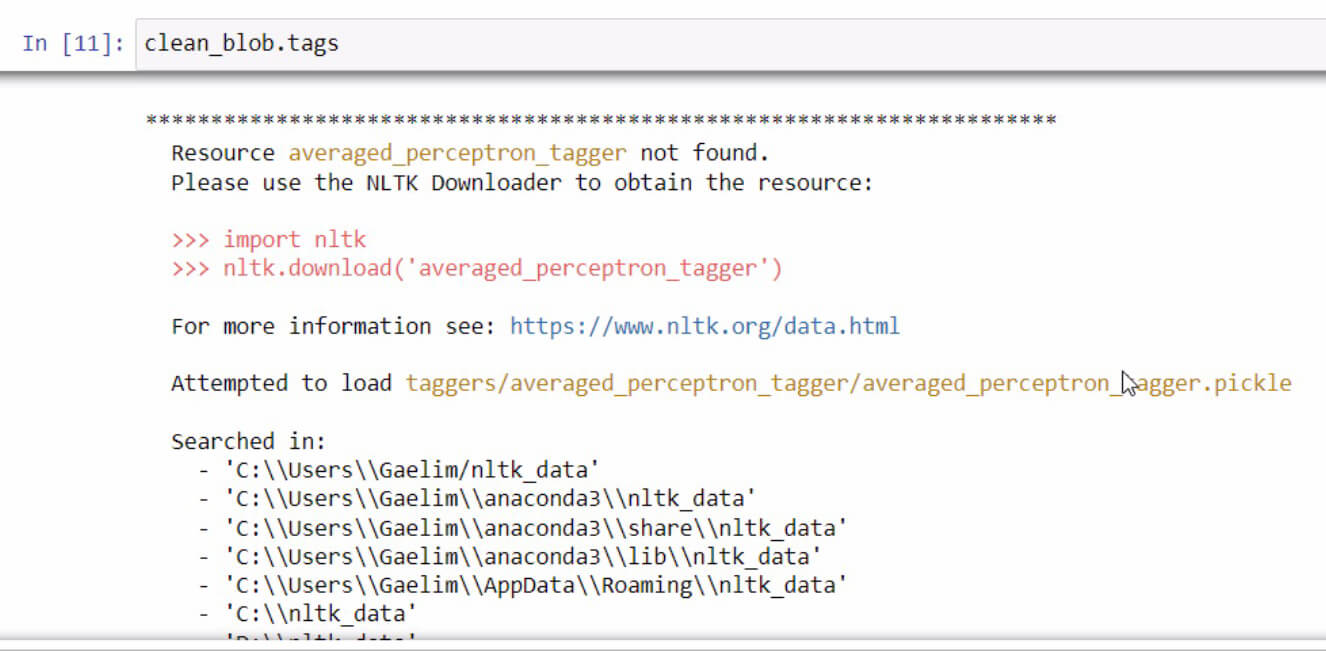
If you scroll down at the end of this error message, you’ll see the required data that you need for the feature that you’re trying to use.
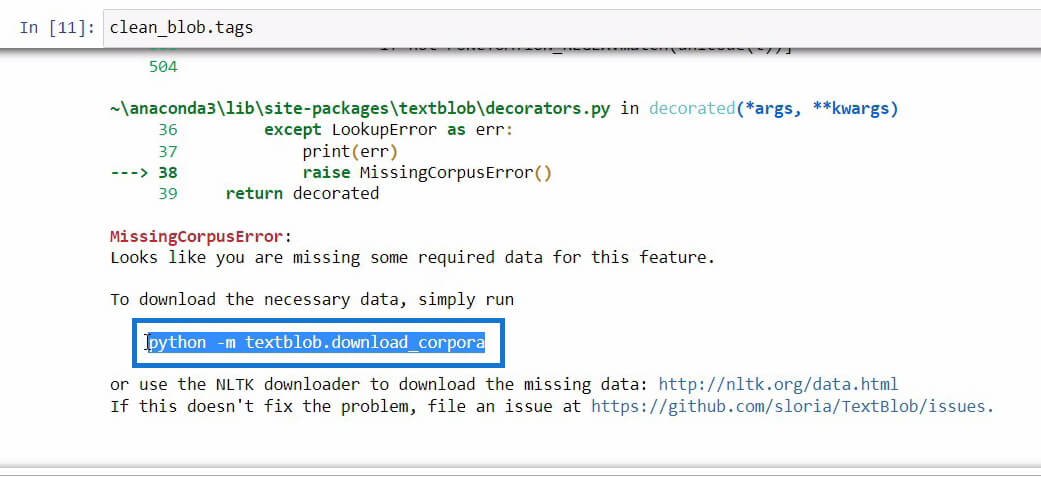
Once we find the code that we need to initialize in order to download the necessary data, just copy the code and then open Anaconda Prompt using Windows Search.
Using Anaconda Prompt, we’ll try to fix the error that we received in initializing the .tags function. We’ll now paste the code that we copied from the error message earlier and run it by pressing Enter.
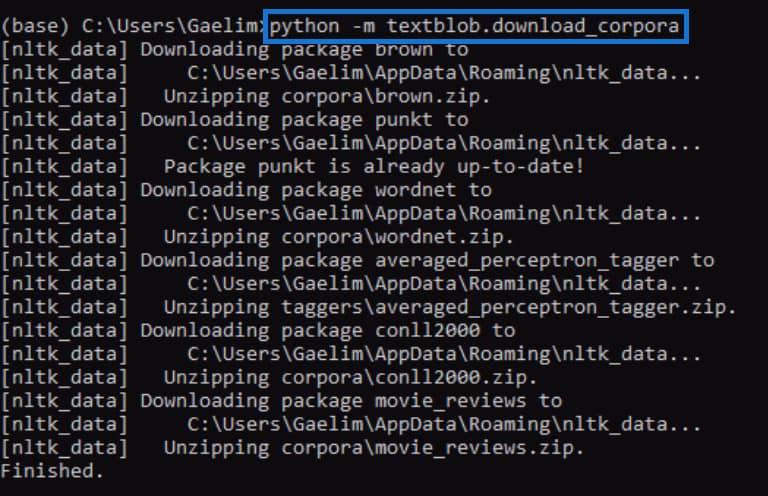
Once it’s finished, try running the .tags function again and see if it works.

Upon running the code again, we can see that the error is fixed and we received a result that contains each word from the new textblob along with the tags or parts of speech.
If you have no idea what these tags mean, you can simply go to the textblob website to check what these tags represent.
Utilizing The ngrams Function For Text Analysis In Python
Let’s move to another example, which is about getting the ngrams. The ngrams function is used to look for words that are frequently seen together in a sentence or document. As an example, let’s start by creating a new textblob and store it in the blob3 variable.

After that, let’s utilize ngrams function in the blob3 variable to check some combinations of words.
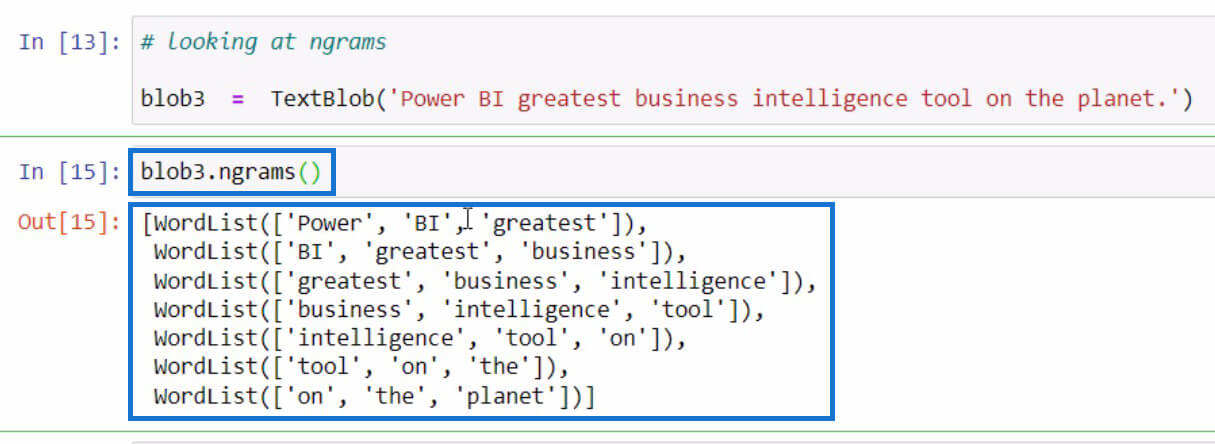
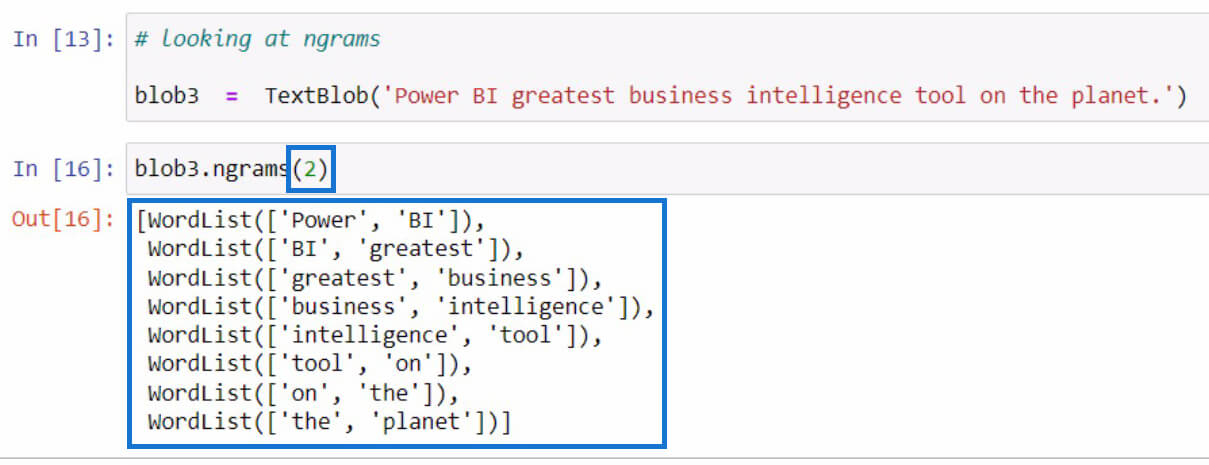
By default, if you didn’t specify a value in the parameters, it’s going to display trigrams or 3-word combinations. But if we want to see 2-word combinations from the sentence, we can set 2 in the parameters like in the example below.
Let’s try it with a longer sentence this time. In this example, I just copied a longer text from a movie review. You can use any sentence that you want for this part.
As a final example, let’s try using ngrams one more time with a more informative sentence.
With all these examples, we can perform more text analysis in Python based on the results that we are getting with the ngrams function.
***** Related Links *****
Python II For Power BI Users – New Course In The On-Demand Platform
How To Load Sample Datasets In Python
Using Python In Power BI | Dataset And String Function
Conclusion
To sum up, you’ve learned about the different functions that you can utilize for performing text analysis in Python.
These are the .tokenize function for separating words in a sentence, .join function for combining tokenized words, .tags function for checking the parts of speech of words, and ngrams function for viewing the combination of words.
Additionally, you’ve learned how to fix errors like what we did in the .tags function using Anaconda Prompt. You’ve also learned how to import, create a textblob and utilize this library for performing text analysis in Python.

All the best,
Gaellim


