
There are a variety of Power Automate string functions of string functions that we can use in our MS flows. In this tutorial, we’ll find out the usage and importance of another complicated string function – the Power Automate split function.
The split function simply returns an array of items based on the provided string and a delimiter.

How The Power Automate Split Function Works
We need to define its parameters (text and delimiter) for this function to properly work.

To explain it further, let’s say our text is “the apple falls far from the tree”. Then the delimiter is just a simple space.

By using the split function, we’ll have an array that contains all the words within the text/string that we specified. An array is a collection of items.

Using The Power Automate Split Function
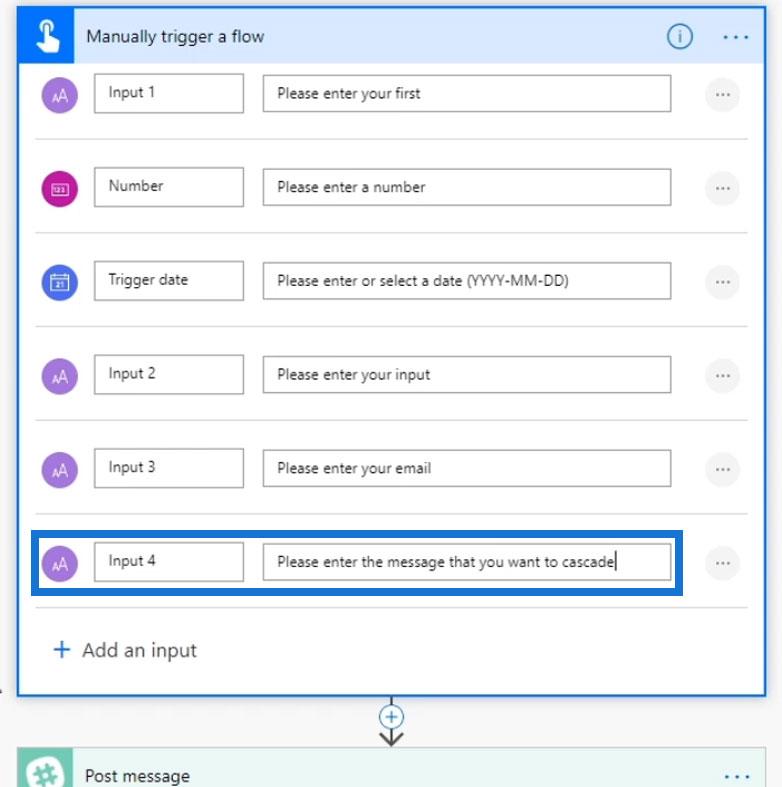
Let’s now have a sample use case to understand why we would want to do this. We’ll add another input in this sample flow that I previously created. Let’s set that as Input 4 then type in “Please enter the message that you want to cascade”.
Then, let’s use the split function on our Message text. Under the Expressions tab, choose the split function.
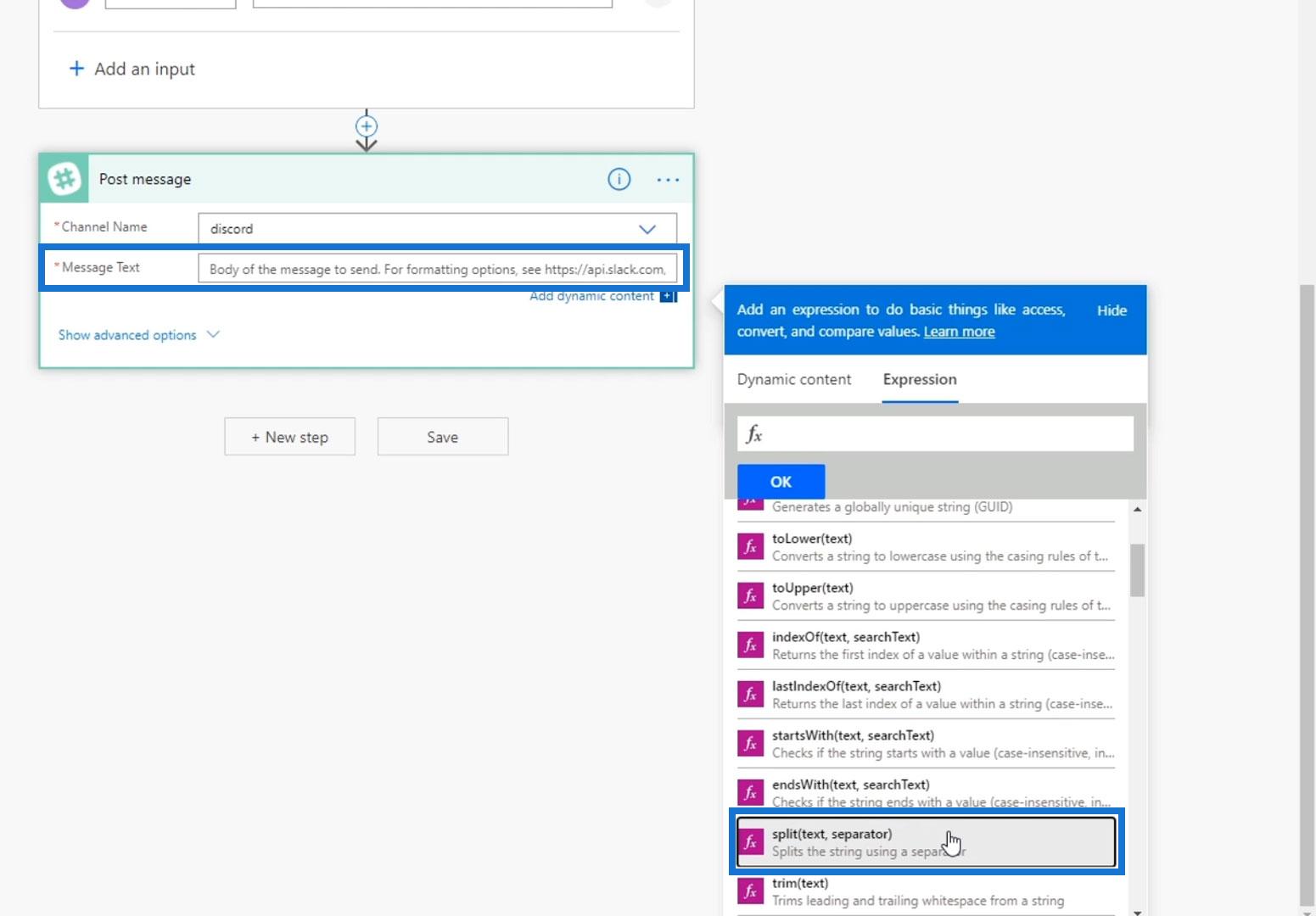
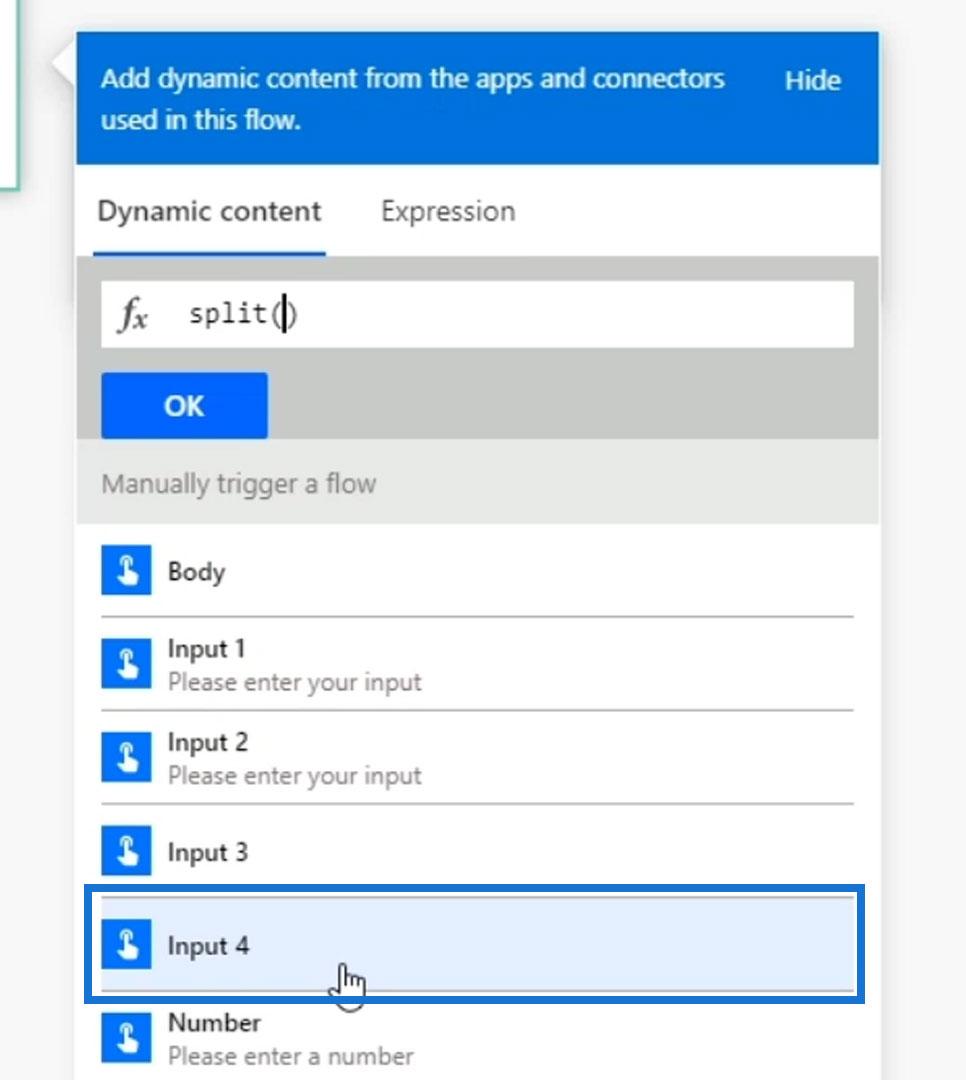
For the text parameter, choose the Input 4 variable.
For the separator, we’re going to use a space. Then click the OK button.


Lastly, click Save.

Testing The Flow
Let’s now see what happens. Click Test.

Choose the I’ll perform the trigger action option. Then click Test.

Enter any data for the other inputs. As for Input 4, just type “the apple falls far from the tree”. Then click Run flow.

Click Done.
Upon checking Slack, the returned output is exactly what we thought it would be.
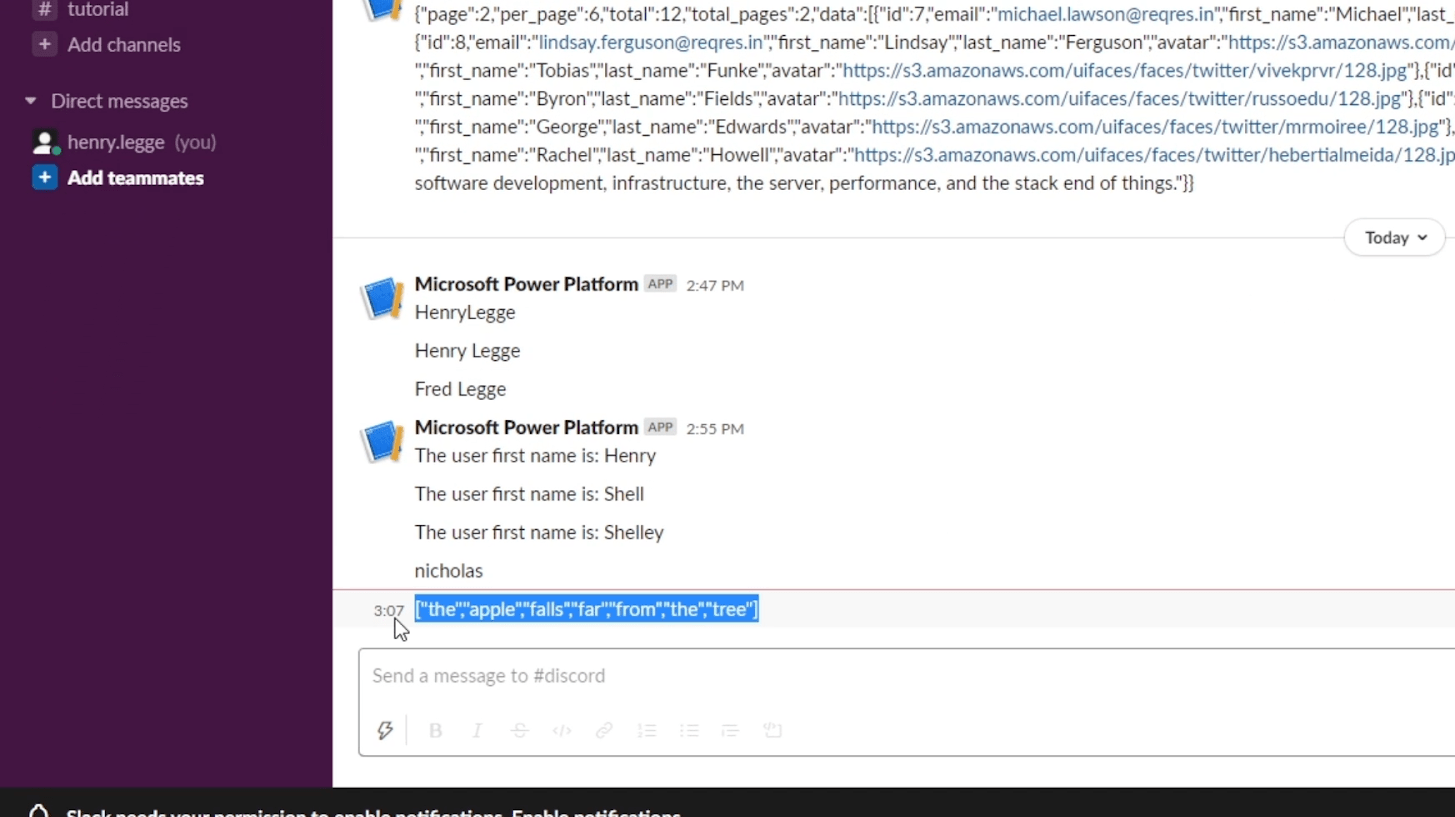
This is now sending us an array and not the actual string.
Usage Of Arrays
Let’s now discuss some things that you can do with an array. First, let’s add a new step.
Then click Control.
After that, choose the Apply to each control.
Under the Expressions tab, choose the split function.

Then select the text itself, which is the Input 4 variable.
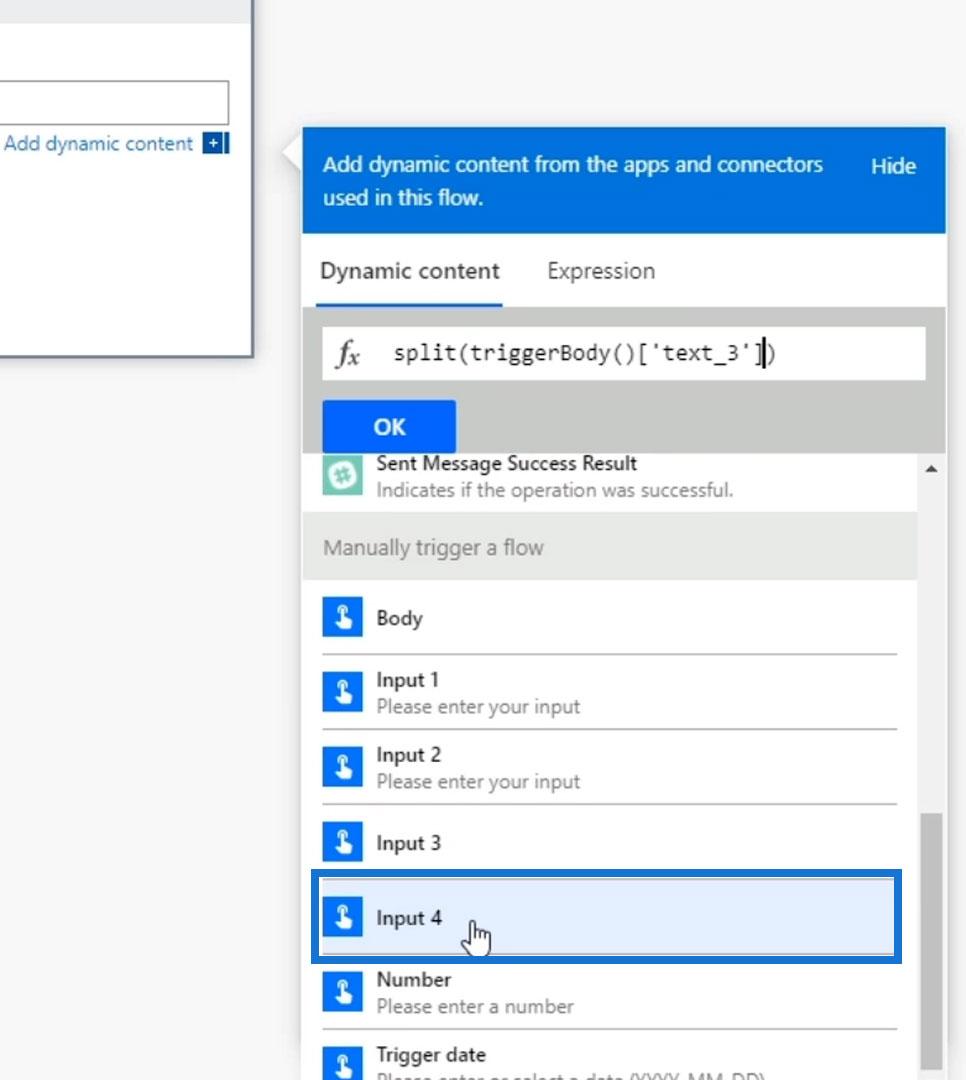
Make sure to type the separator which is a space. Then click OK.

After that, let’s add another action.
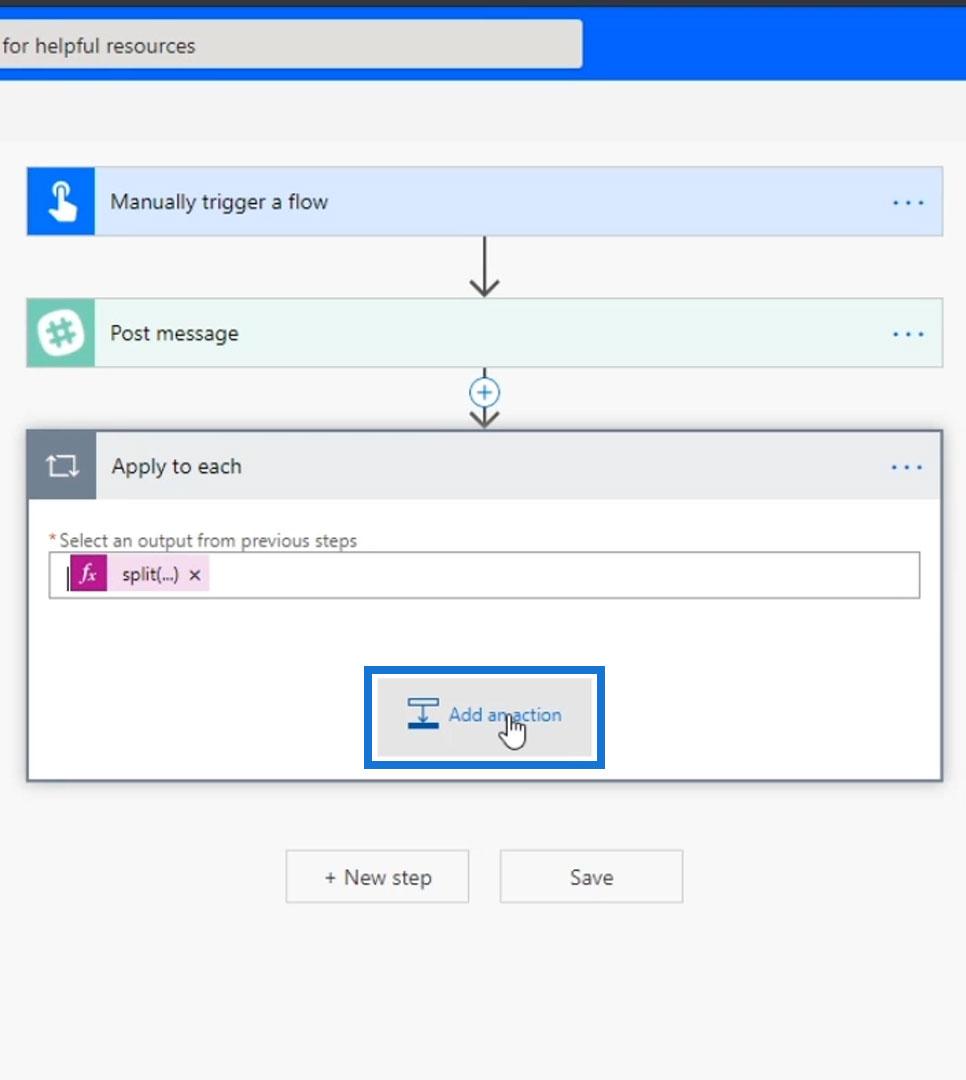
Search and select the Slack connector.

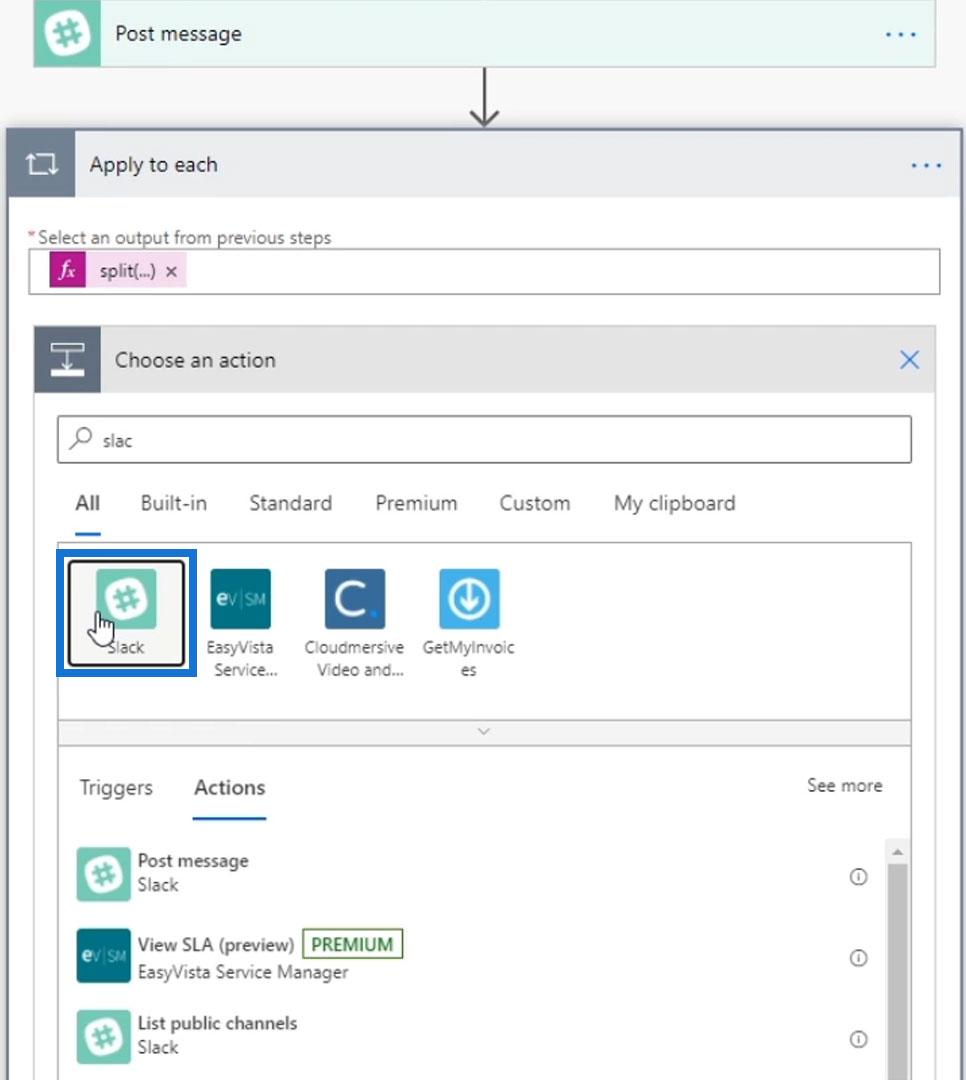
Then choose the Post message action.

Let’s post a message to the same Slack channel (discord).
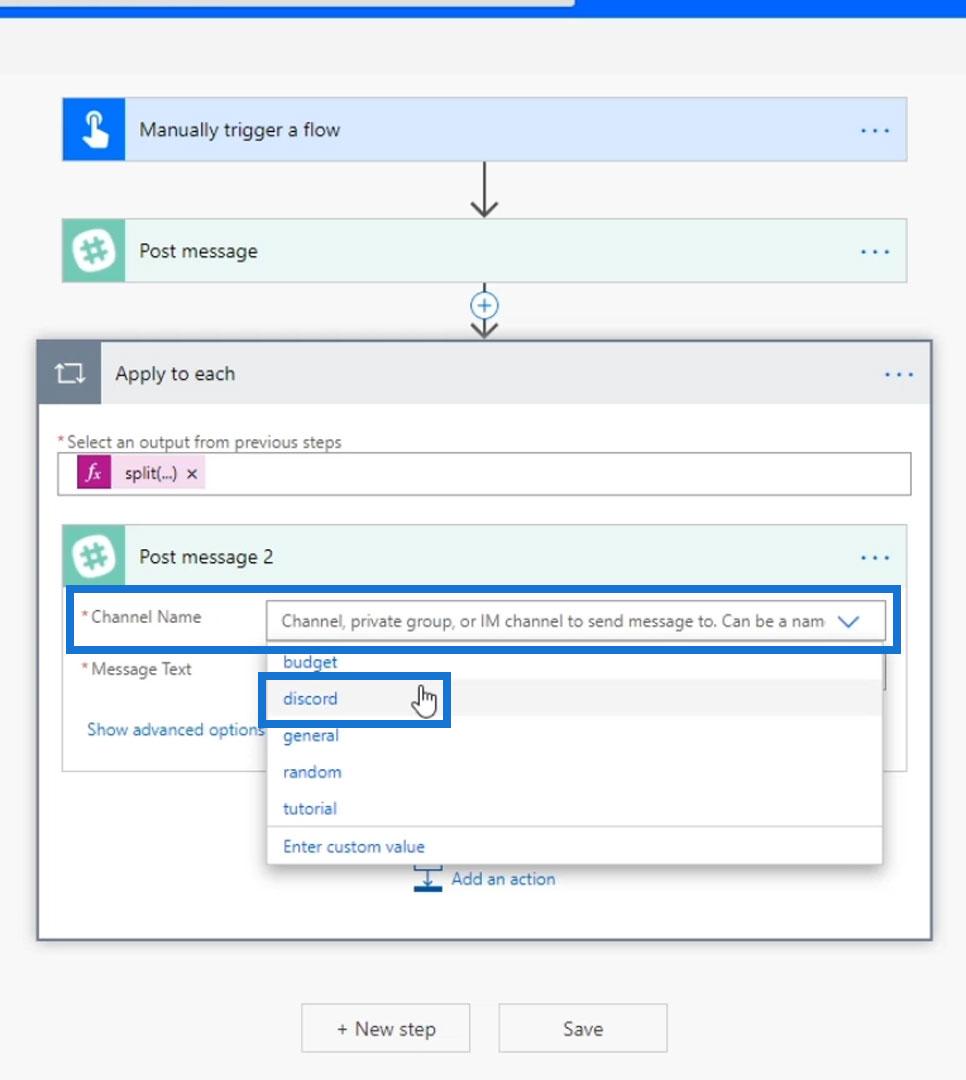
For the Message text, instead of posting Input 4 or the array, we’re going to post the Current item.

By using the Apply to each control, it’s first getting the array of strings via the split function. Then, for each item in the array, it’s posting that current item. So let’s see what that looks like. Click Save.
Click Test.
We’ll just use the previous run since no inputs have changed. Then click Test.
Upon checking our Slack, we’ll see that it successfully displayed each of the items from the array.

By doing this, we can perform actions on the array items separately.
***** Related Links *****
Power Automate String Functions: Substring And IndexOf
Triggers In Power Automate Flows
Power Automate Expressions – An Introduction
Conclusion
To sum up, we’re able to discuss the usage of the Power Automate split function in our flows. It breaks down strings into an array of strings using the defined delimiter. The delimiter serves as the separator. In our example, we used space. People usually use commas, but you can certainly have different delimiters for each purpose.
We can also iterate through the array of items and then perform certain actions on each of them. We usually do that by using the Apply to each control. This technique is definitely useful when working on a collection of data.
All the best,
Henry


