
This tutorial is a continuation on the discussion about the dplyr package. You’ll learn how to arrange, filter, and group rows in R.
The previous lesson was on column operations. This time, the focus will be on row operations in dplyr.
We’ll be covering the basics which includes sorting and filtering a dataset and aggregating and summarizing records. To give you an overview on what to expect for this lesson, think of a pivot table in MS Excel.

Getting Started
Open a new R script in RStudio.
Similar to the column operations lesson, this demonstration will use the Lahman dataset package. Download it by doing a quick google search.
To bring the Lahman package into R, run library (Lahman). To enable the dplyr package, run library (tidyverse). Also, remember that a best practice for naming conventions in R is using lowercase letters so assign Teams into teams.
Basic Functions For Row Operations
1. Arrange Rows In R
The first row operation in dpylr is arrange ( ). This function allows you to reorder rows. It works by first arranging the data frame df and then the given fields.

For example, let’s sort by teamID. Run arrange (teams, teamID).
If you want them to be arranged in descending order, you need to use the desc ( ) function.

As an example, if you want to sort by year in descending order, run arrange (teams, desc(yearID)).
When you do this, you’re not assigning the output back to teams. You’re just seeing the result in the Console.
It’s also possible to sort by multiple criteria. For example, if you want to sort by teamID and then yearID in descending order, you only need to run this code:
When you’re sorting rows, you’re not changing the data. The data is just being moved around. Nothing is being added or removed.
2. Filter Rows In R
The filter ( ) function adds or removes data depending on the criteria selected. Its basic code is:

As an example, let’s get all the data where the yearID is greater than or equal to 2000. Follow the filter function’s format and input the needed information. Then, run it. Don’t forget to assign this to a new object. In this case, it was assigned to modern.
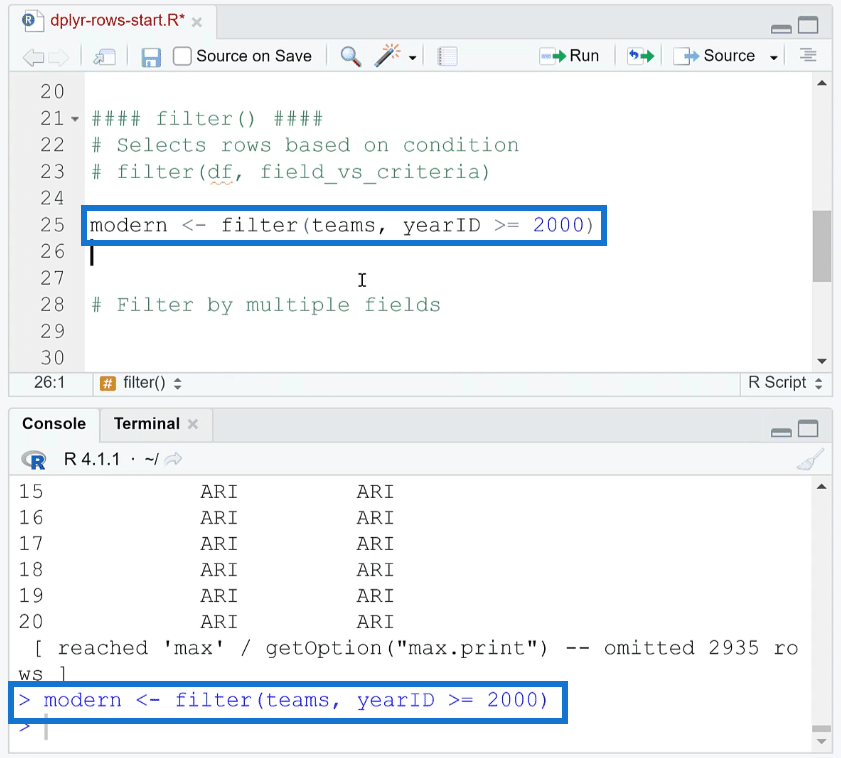
To check if the rows were indeed filtered, you can use the dim ( ) function. It gives the number of rows and columns in the data frame.
If you run dim (teams), you’ll see that the data frame has 2,955 rows and 48 columns.
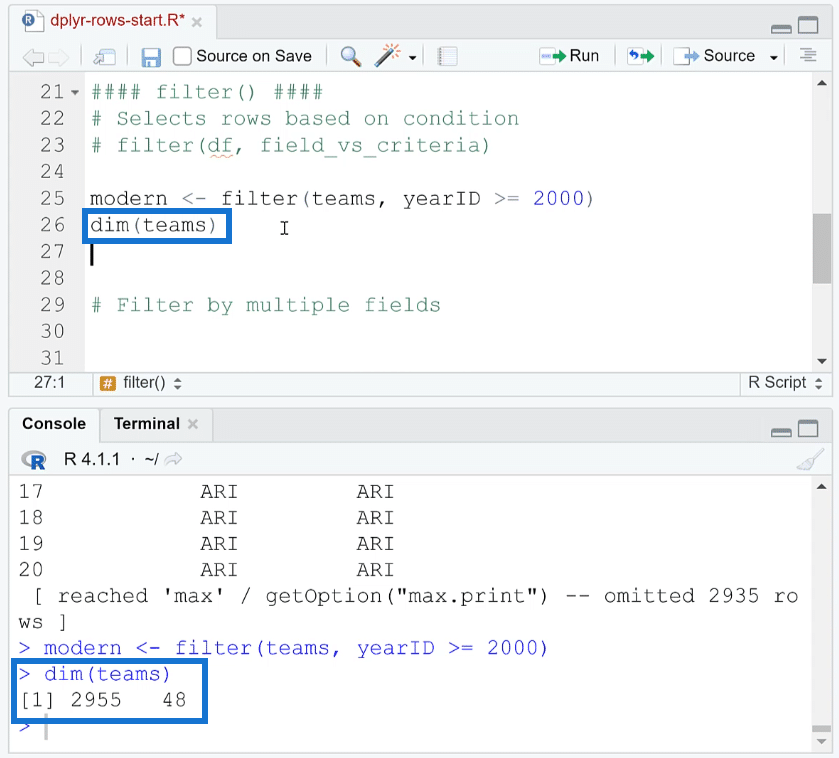
If you run the dim function on modern, you’ll see that the number of rows has been reduced to 630 while the number of columns remains the same.
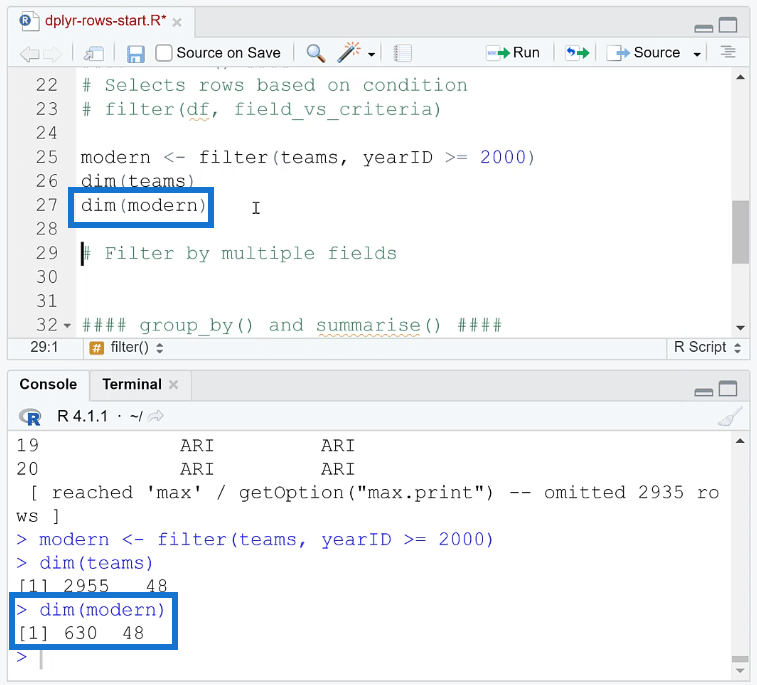
The rows have been truncated because some of the records go beyond the year 2000.
Filter Rows By Multiple Fields
It’s also possible to filter rows by multiple fields in R. You’ll need to use the AND and OR statements.
For example, let’s filter teams by area. In this case, a new object ohio is created. The filter criteria are that teamID should only include Cleveland AND Cincinnati.
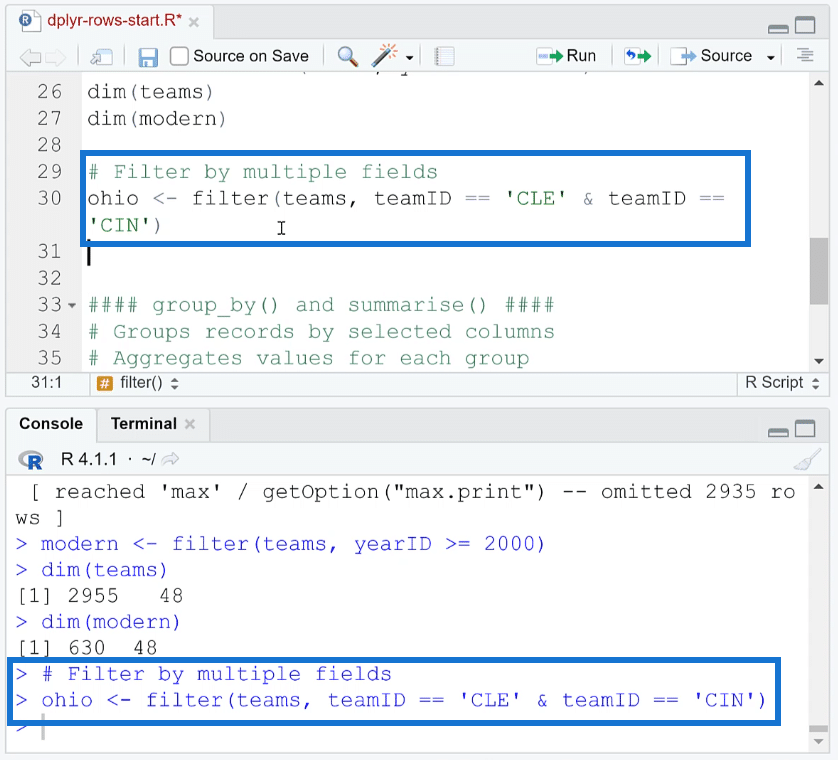
You need to use the double equal sign (==) to check equality. If you only use one equal sign, R will consider it as an assignment operator. Use the ampersand (&) to represent AND.
To check, use the dim function. You’ll see that the number of rows is 0.
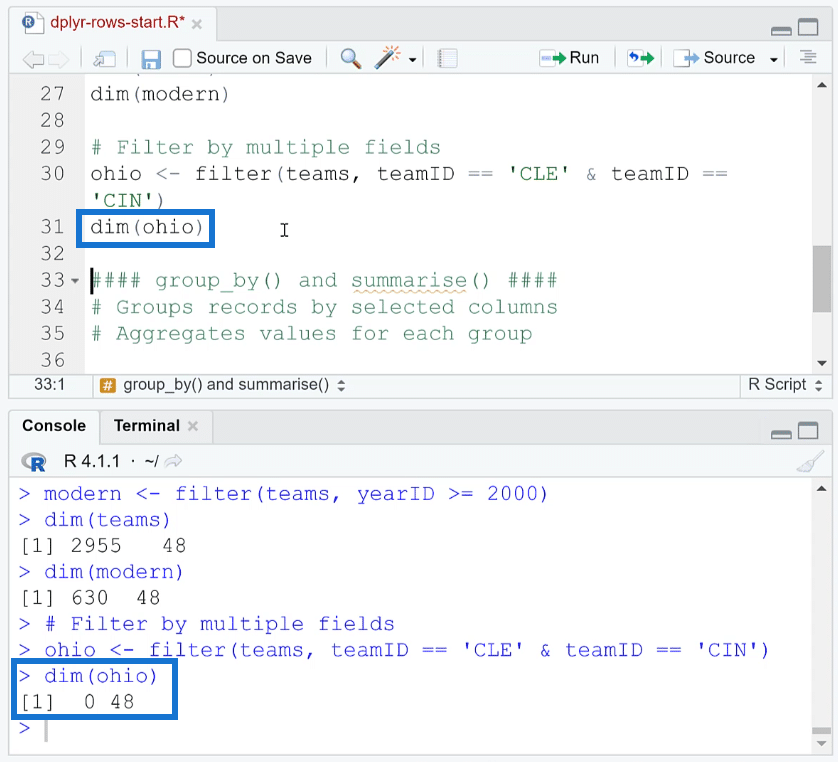
This means that there aren’t any teams where they’re both based in Cleveland and Cincinnati.

Next, let’s try the Cleveland OR Cincinnati. The OR operator is represented by the pipe operator ( | ). So, all you need to do is replace the ampersand with the pipe operator and then run it. Afterwards, run the dim function again.
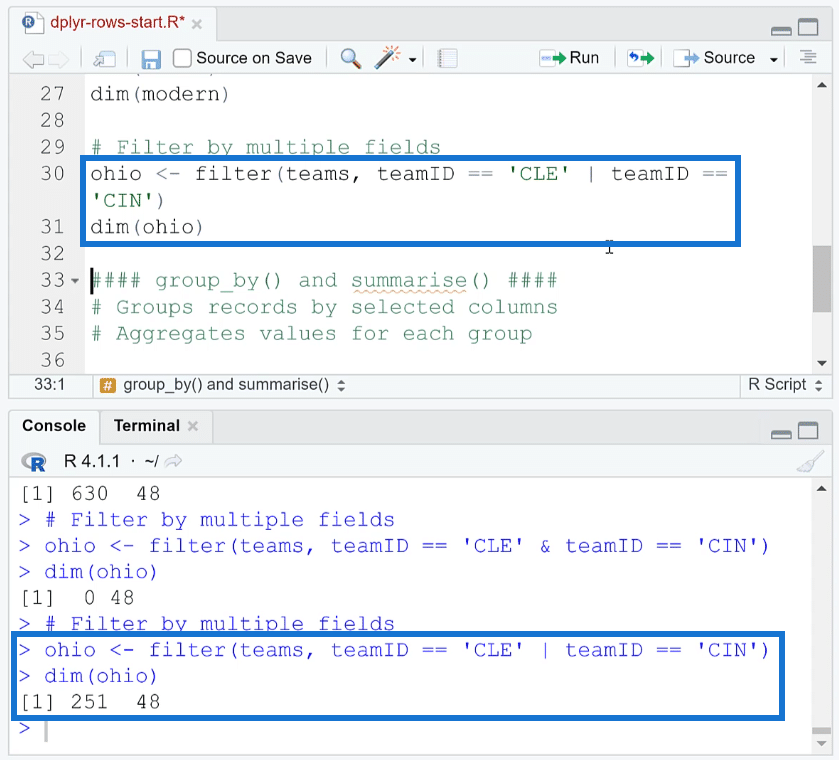
You’ll see that there are 251 rows rather than zero.
Now what if you forget to use a double equal sign and instead use just one? Here’s what happens:
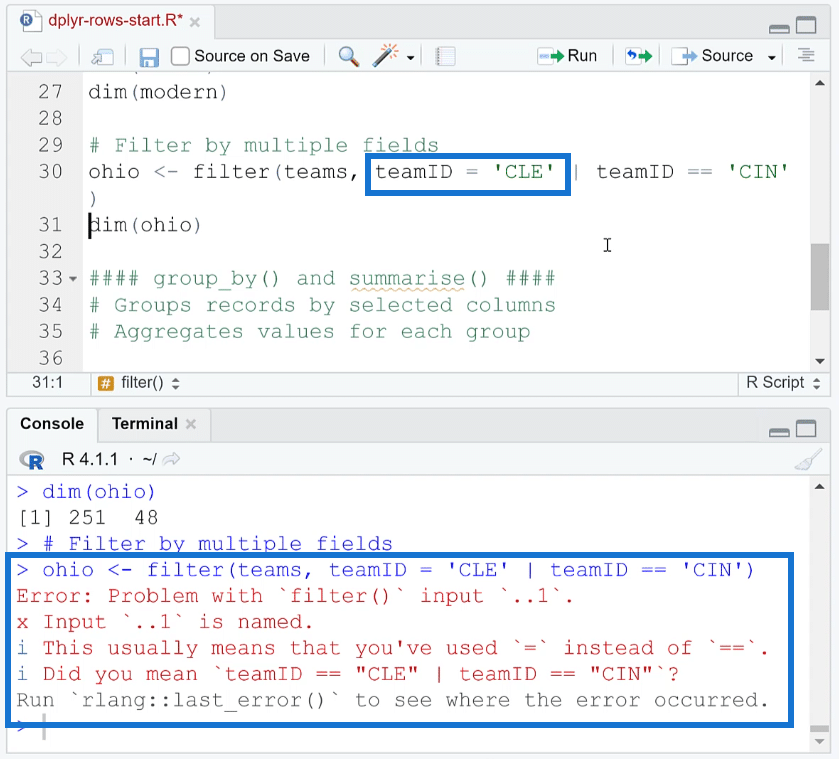
RStudio will show a very helpful error message in the Console reminding you to use the double equal sign.
3. Group By And Summarise Rows In R
The group by ( ) function allows you to aggregate records by selected columns and then based on that aggregation, summarise another column.
The group by ( ) function follows this algorithm:
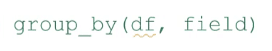
As an example, let’s group by teamID and assign it to a new object. In this case, the new object is called teams_ID. Then, print it.
In the Console, you’ll notice that the first line say it’s a tibble.
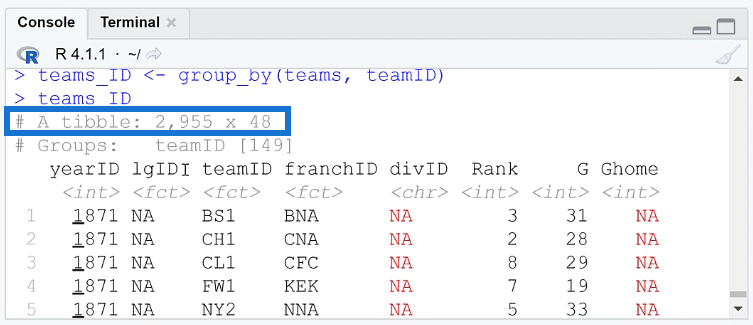
A tibble is a tidyverse improvement over the basic data frame. It’s a feature in the package that augments and improves what’s available out of the box.
The second line is Groups. So, the data is now grouped by the teamID column.
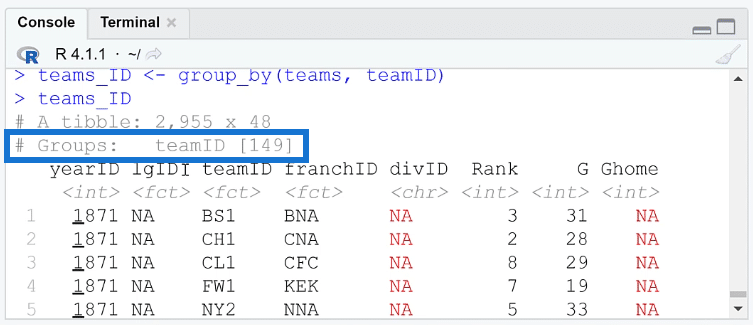
And with that, you can now use the summarise ( ) function on those groups.

Note: the summarise function can either be with an s or z, and will depend on the use of British or American English.
For example, let’s summarise teams_ID and get some basic summary statistics. Let’s look for the mean, minimum, and maximum of the Wins for each team. Remember to highlight the entire code before choosing to Run.
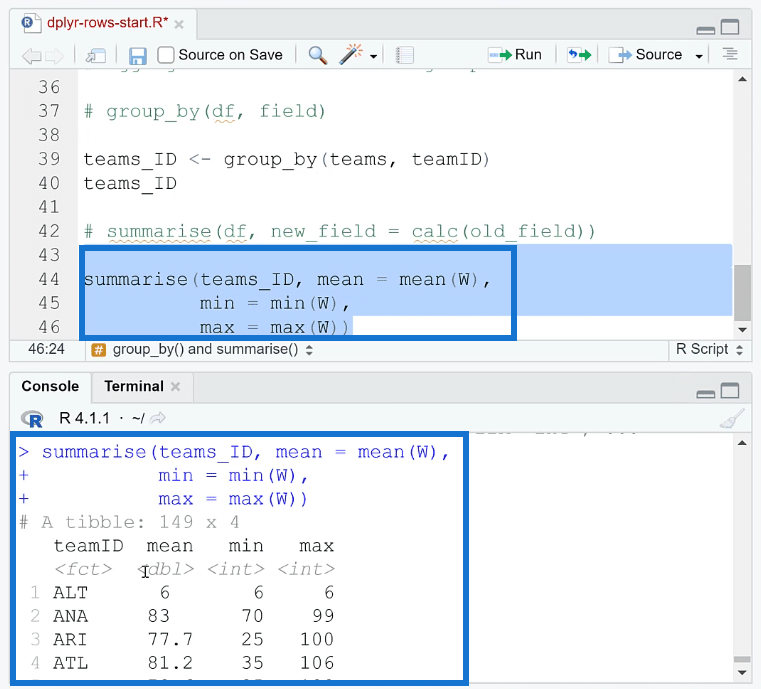
You can then see in the Console that a summary of each team’s statistics is displayed. This is very similar to a pivot table where you’re aggregating and summarizing data.
***** Related Links *****
Data Frames In R: Learning The Basics
Factor Levels In R: Using Categorical & Ordinal Variables
Add, Remove, & Rename Columns In R Using dplyr
Conclusion
To recap, two operations in dplyr have been discussed. A previous tutorial focused on column operations. Meanwhile, this current lesson showed you how to perform row operations using the dplyr package in RStudio. Specifically, you learned how to arrange, filter, and group rows in R.
The next thing to learn is how to combine these two operations. Using all the functions you’ve learned so far will greatly assist you in creating codes in R. However, a more helpful technique would be a pipeline. This will help everything flow together. So, make sure to review the next tutorials as well.
George



