
In this tutorial, we’re going to take a look at the second engine inside analysis services — the storage engine.
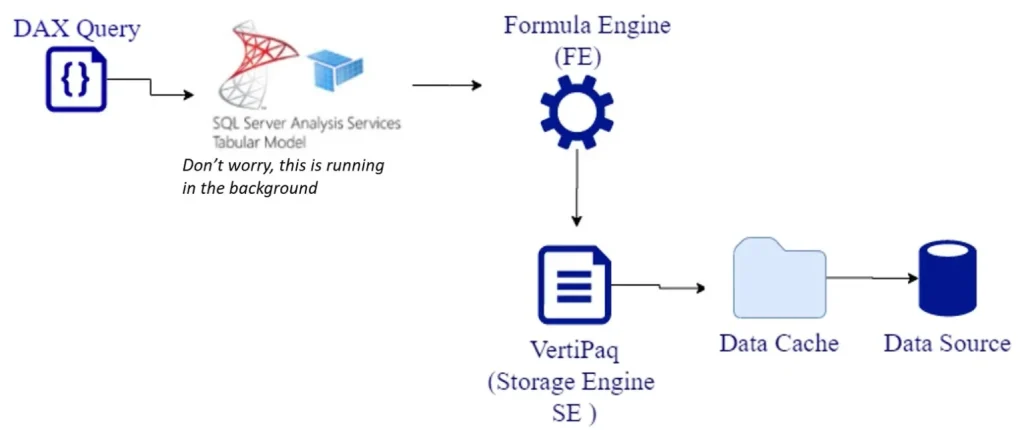
We discussed the top-level engine, the formula engine, in a past tutorial. When users understand how both these engines work, it’s easier to optimize and improve the performance of your DAX queries.

The storage engine’s main purpose is to work directly with the database.
The formula engine doesn’t have direct access to the database, so it normally goes through the storage engine for this purpose.
The storage engine comes in two types — import mode and DirectQuery. You can mix and match both types in the same data model to create a composite model.
Working With Import Mode In The Storage Engine
First, let’s talk about the import mode. This is also more commonly known as Vertipaq, but it’s also called xVelocity or In Memory Columnar Database.
There are four critical things to understand about how the import mode works.
First, Vertipaq creates a copy of the data straight from the data source and stores it in the RAM in compressed format.
Second, the data processed in the import mode is based on the last refresh operation. This means that if you last refreshed your data last week, then the data you’re dealing with is still the same data from last week. This is especially important if you’re using a composite setup where one table is in the import mode and the other table is in the DirectQuery mode.

Let’s say you have the Products table, which was refreshed last week, in the import mode. As for the Sales table, you decided to course it through DirectQuery because of its size. Let’s also assume that you’re creating your report based on both tables where you’re bringing in the Brand column and creating a Total Sales measure over the same Sales table. You also want to visualize the Sales amount based on the Brand.
You’d have to refresh the data coming from import mode first because you might end up with fresh and updated data from DirectQuery, and outdated data from Vertipaq. This will leave a few blank rows on your matrix and your visualization.
The next thing you need to know about Vertipaq is that only basic operations like MIN, MAX, SUM, COUNT or GROUPBY are natively available. This means that if there are other more complicated operations included in the query plan, the storage engine would have to call the formula engine to resolve this part of the code.
Finally, the storage engine is a highly-optimized database because of Vertipaq’s columnar structure. This means that all the data are stores column by column and not row by row. Because of this structure, Vertipaq will always be faster than a DirectQuery connection even if you create indexes in your relational data model.
Working With DirectQuery In The Storage Engine
The next option that we have inside the Power BI analysis services is DirectQuery. If you use the DirectQuery connection, the analysis services only acts as a pass through for the queries that are sent by the formula engine.
So let’s say you write a query. The formula engine will generate a query plan. It will then forward the query to the storage engine, already translated into the native language of the database. Most of the time, these queries come in SQL.
If the query uses DirectQuery, expect it to be up-to-date all the time. There’s no need to worry about when you last refreshed the data.
The process of optimizing the DAX code and the data model will also depend on how the relational database was created. If you have indexes in your columns, then your queries will always be optimized. But if your database is not optimized in terms of creating reports using analysis services or Power BI, then you could face a few performance challenges. So be intentional in making your databases built for report development.
Working With Composite Models
The third option is to create a composite model so that you can have one table in import mode and another table in DirectQuery.
When you use two tables from different sources, the formula engine will send one request to Vertipaq and another request to the DirectQuery data source. In both cases, analysis services will also retrieve the data cache from both Vertipaq and DirectQuery. The formula engine will then use JOIN, GROUPBY, or any iteration on both data caches before providing the results to the end user.
So let’s say you’re trying to visualize the sales amount by the product’s brand in your report. The formula engine will send a request to Vertipaq, where it will retrieve the product, brand and product key. Then, from DirectQuery, it will try to retrieve the sales, net price, sales quantity, and sales product key.
Once it has the two data caches based on the product key, it will join the two data caches and compute the total sales amount. It will then present the results to the end user.
Other Critical Points About The Storage Engine
Now that we’ve covered its different types, there are a few other critical factors that you need to know about the storage engine to help you optimize your DAX queries.
As I’ve mentioned earlier, the storage engine provides the data cache back to the formula engine in the form of an uncompressed data cache. When you’re on import mode, the request that is sent back to Vertipaq in the process is executed in an xmSQL language.
The xmSQL language is somewhat similar to SQL but is not completely the same. We’re going to talk about xmSWL in detail when we talk about query plans in a different tutorial.

It’s also important to remember that the storage engine uses all the cores available in your CPU. The ability to use multiple cores is beneficial in case you have multiple segments within your data model.
Let’s say you have a table in Power BI with 12 million rows. This table will then be divided into 12 segments because in both Power Pivot and Power BI, each segment fits 1 million rows. This is unlike analysis services in general, where one segment accommodates 8 million rows.
So if I have six cores in my CPU, all six cores will scan the first six of the 12 segments at the same time. Once they’re done, they will move on to the next six segments.
But if I’m working with analysis services where the default segment holds 8 million rows, only two of my six cores will be used — one segment will process 8 million rows while the other processes 4 million.
Working On Complicated Queries
Earlier, I mentioned that the import mode only supports basic operations like MIN, MAX, SUM, COUNT and GROUPBY. So what happens if you work on more complicated queries?
Let’s say you decide to use an IF statement in the row context, or a nested iteration like SUMX over the Products and Sales tables.
In this case, the storage engine won’t be able to resolve the query on its own. It will then call the formula engine, which will start solving the complex calculation row by row inside the storage engine. Some may think that this is a favorable scenario, with both engines working together — but this is far from the truth.
You see, when this happens, the data cache produced by the storage engine cannot be cached in case there’s a callbackdataID in that particular query. So if you refresh the visual, the same computation will have to be done by both the formula engine and the storage engine, even though you just executed the same query a few seconds ago. This will lead to performance delays and bad user experience.
Note also that the storage engine doesn’t know whether queries were executed using DAX or MDX. As we mentioned earlier, it’s the formula engine’s job to convert the queries into the right language before passing on the query plan.
Lastly, the formula engine sends queries into the storage engine one by one. This means that having multiple segments really is better so that the overall scanning time within Vertipaq can be reduced, with multiple segments being scanned at the same time.
***** Related Links *****
DAX For Power BI: Optimizing Using Formula Engines in DAX Studio
DAX Query Optimization Techniques And Lessons
Query Performance And DAX Studio Setup
Conclusion
Understanding the ins and outs of the storage engine truly helps in optimizing your DAX queries, especially if you’re using DAX Studio. If you’ve also gone through the tutorial explaining the formula engine, you can make better decisions on how to create better performing queries.
Although the formula engine serves as the top-level engine, there is no doubt that it cannot perform as well as it can if we don’t maximize both engines.
All the best,
Enterprise DNA Experts


