
If you’ve ever worked with text data, you probably know how challenging it can be to find and extract specific information from it. Regular expressions (regex) solve this problem by allowing you to search for specific patterns within the text, but it can be challenging to remember all the syntax and rules.
This article is a quick reference guide that provides an overview of the capabilities of regex syntax. This includes a list of symbols, ranges, grouping, assertions, and sample patterns that you can use to get started.
Whether you’re a beginner or an experienced developer, learning regex correctly is essential for you to save time and help you write more efficient code.


Let’s dive in!
What is Regex?
Regular expressions, or regex, are patterns of characters that describe an amount of text. They are used to search, replace, and manipulate text in various programming languages and applications.
One area where it is particularly useful is in the field of data mining. You can use regular expressions to extract useful information from the mined data.
You can check out data mining in action in our video tutorial on how to build a Google news aggregator in Power BI using Python below:
Our regex guide is particularly useful for beginners who are just starting to learn regular expressions. Additionally, even experienced developers can benefit from using a regex guide, as it allows them to quickly access information and refresh their memory on specific patterns.
So without further ado, let’s dive into some regex in Python!

How to Use Regex in Python
Regular expressions are universal to all programming languages. Each programming language has its own regex flavor.
Throughout this guide, we’ll be using the Python regex library for all our examples as it is very easy to use. The library is built into Python.
To import the library, simply run the command below:
import reIt contains two main methods that we can use for getting matches:
search(): The search() method looks for the first match in the entire string and returns a match object. The match object contains the index of the match within the string.
findall(): The findall() method looks for all the occurrences and returns them in a list.
Each command takes in two parameters; the Regex string and the string to be searched for example.
import re
b = re.findall('<regex string>','<text to be searched>' )It can be quite simple to use. However, for the sake of simplicity, we’ll be using a website called Regexr.
It offers a fun, colorful UI that you can use to easily visualize your regex matches. This is very helpful to beginners.
Basic Regex Syntax
If you’re new to regular expressions, the RegExp syntax can seem a bit daunting. However, once you understand the basics, you’ll find that they’re actually quite simple and powerful.
In this section, we’ll cover the basic syntax of regular expressions, including literals, metacharacters, and more.
1. Literals
Literals are characters that match themselves. For example, the regular expression /hello/ will find a match in the string “hello I’m home“.

The Regexr tool highlights the match in blue. Other examples include:
/a/ Matches the character “a“
/123/ Matches the string “123“
Note: Regular expressions are case-sensitive, so be sure to be careful when writing them. You can modify this using flags that we’ll discuss in a later section.
2. Boolean OR
The regex library offers an OR feature represented by the | symbol. You can place two regex patterns on either side of the symbol and it’ll search the text and return a match if it finds either of them.
For example, if we want to search a text for either ‘sun’ or ‘moon‘, we use the regex statement below:
/sun|moon/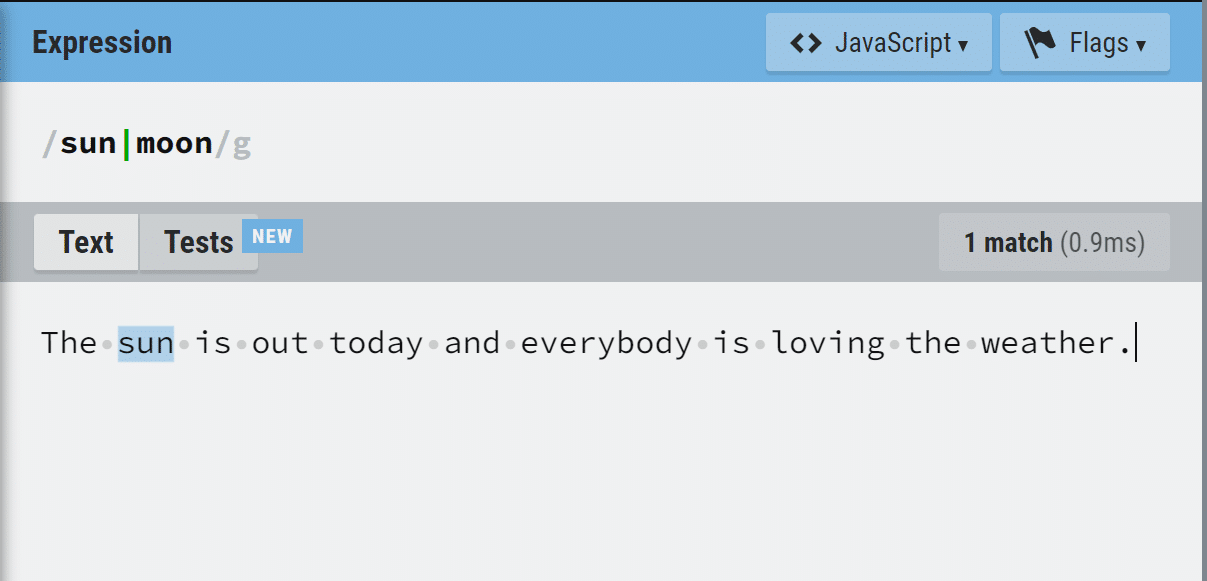
In this example, the left side of the separator finds a match in the text

3. Metacharacters
Metacharacters are special characters that have a special meaning in regular expressions. For example, the dot (.) metacharacter matches any single character except for a new line.
Let’s look at some more metacharacters.
. – Matches any single character except for a new line.
d – Matches digits (0-9).
D – Matches non-digit characters.
w – Matches alphanumeric characters, non-digit characters, and some symbols (a-z, A-Z, 0-9, and _).
W – Matches any character that is not a word character.
s – Matches whitespace characters (space, tab, carriage return, newline, etc.).
S – Matches non-whitespace characters
h – Matches horizontal whitespace characters (tabs, space, etc.)
v – Vertical whitespace character (new line, vertical tab, line breaks, escape sequences, etc.)
n – Matches newline character
t – Matches tab character
Let’s look at some examples:
If we want to match numbers with three digits in a sentence, we can use the regular expression below:
/ddd/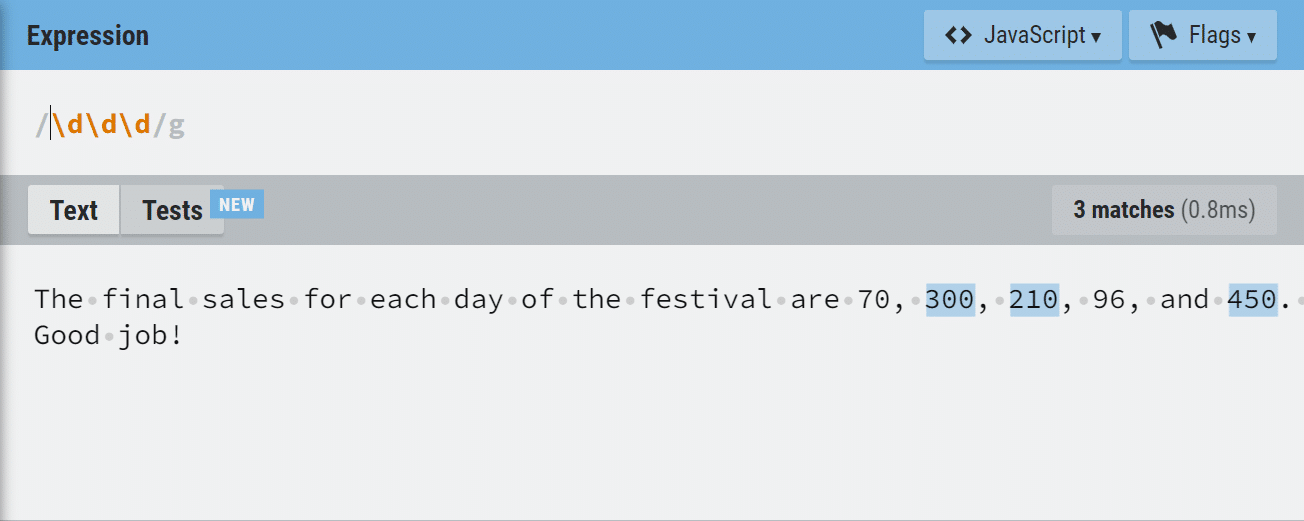
Also, if you want to match the whitespace characters in a piece of text, you can use the syntax below:
/s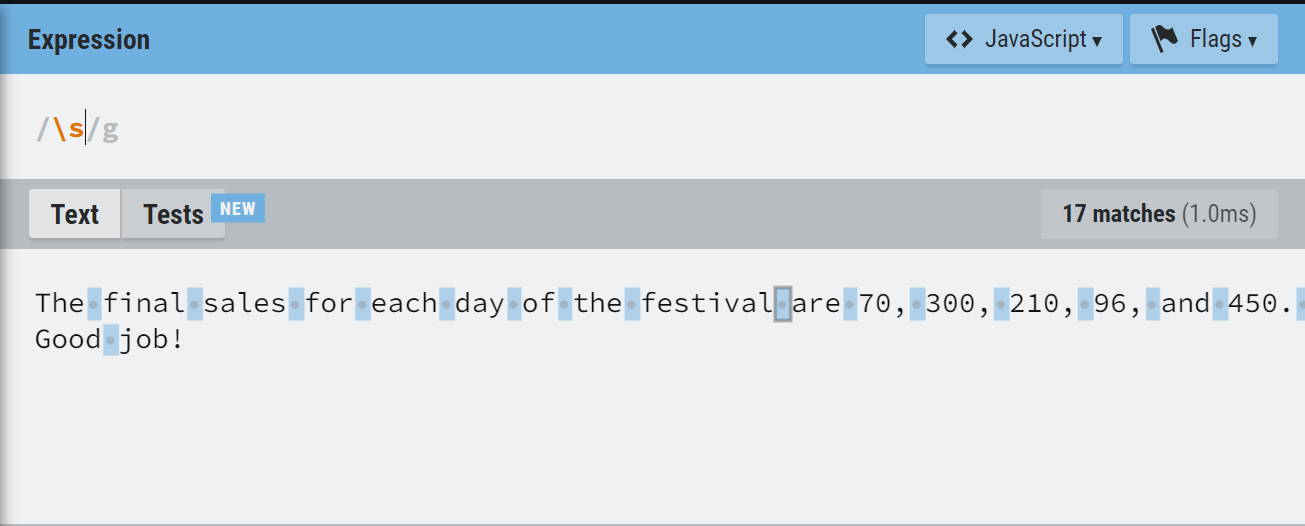
4. Quantifiers
Metacharacters can also be used with modifiers called quantifiers to specify how many times the preceding character or group should be matched.
For example, the * modifier matches the preceding character or group zero or more times.
* – Matches the preceding character or group zero or more times.
+ – Matches the preceding character or group one or more times.
? – Matches the preceding character or group zero or one time.
{n} – Matches the preceding character or group exactly n times.
{n,} – Matches the preceding character or group at least n times.
{n,m} – Matches the preceding character or group between n and m times.
Let’s look at some examples:
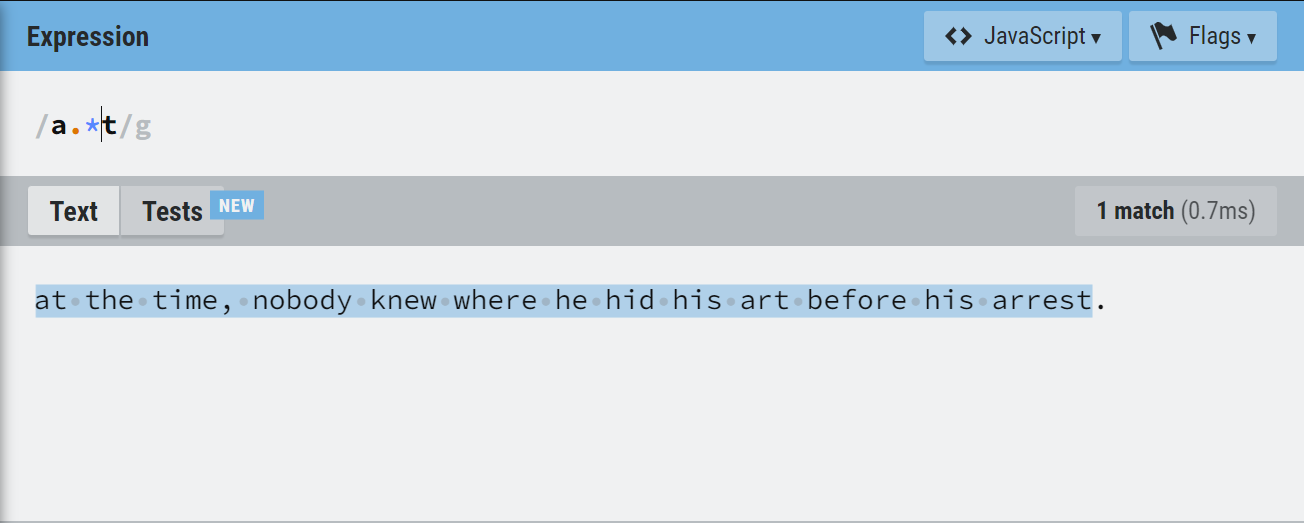
If we want to match the word ‘at’ and all variations of it with characters between ‘a’ and ‘t’, we use the expression below:
a.*?t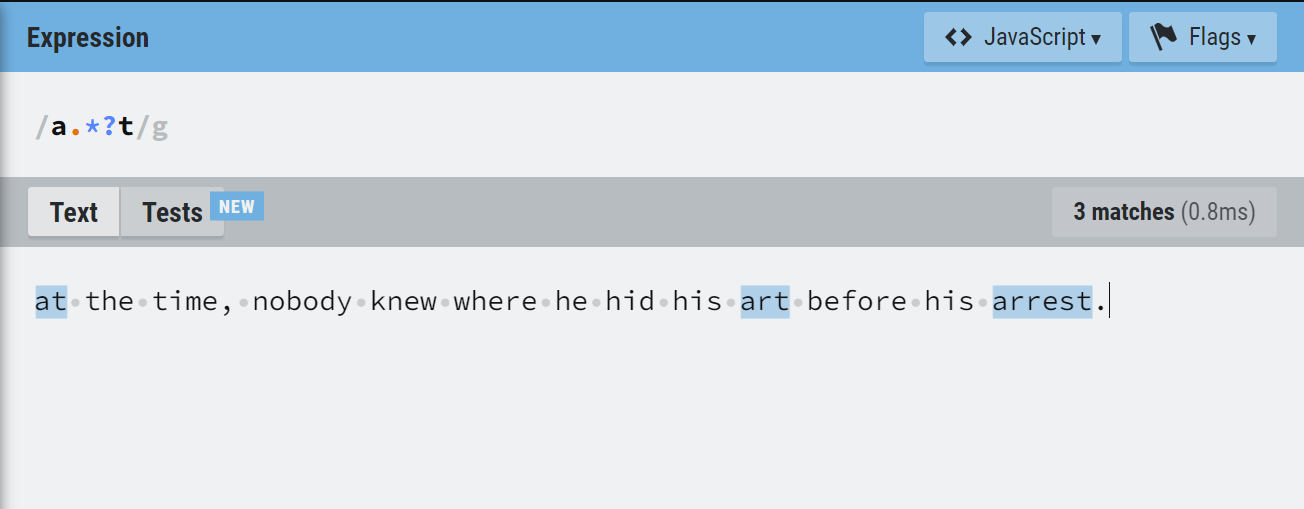
Note: The ? in the regular expression makes it lazy. That means the expression stops searching once it finds the first t after an a.
Without the lazy modifier, this is what we have.
Additionally, let’s say we want to match all words which have exactly two ‘e‘s in the middle. We can use the expression:
/w*e{2}w*/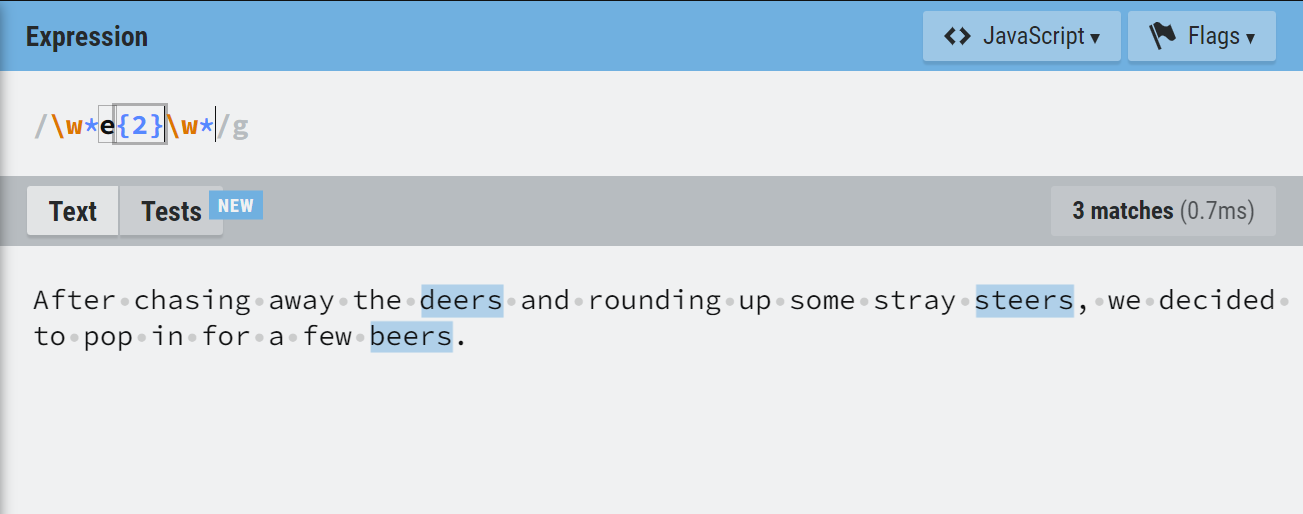
5. Anchors
Anchors can be used with metacharacters and character classes to specify the positions of the matches. Some of them include:
^ – Specifies the match should occur at the start of the string or line.
$ – Matches the regex pattern at the end of the string or line.
A – Matches the regex pattern at the very start of string.
z – Matches at the very end of string.
b – Matches a word boundary (the start or end of a WORD).
B- Matches a non-word boundary character
Let’s check out some examples.
If we have to check out if a sentence starts with the word ‘The‘, we use the expression below:
/^The/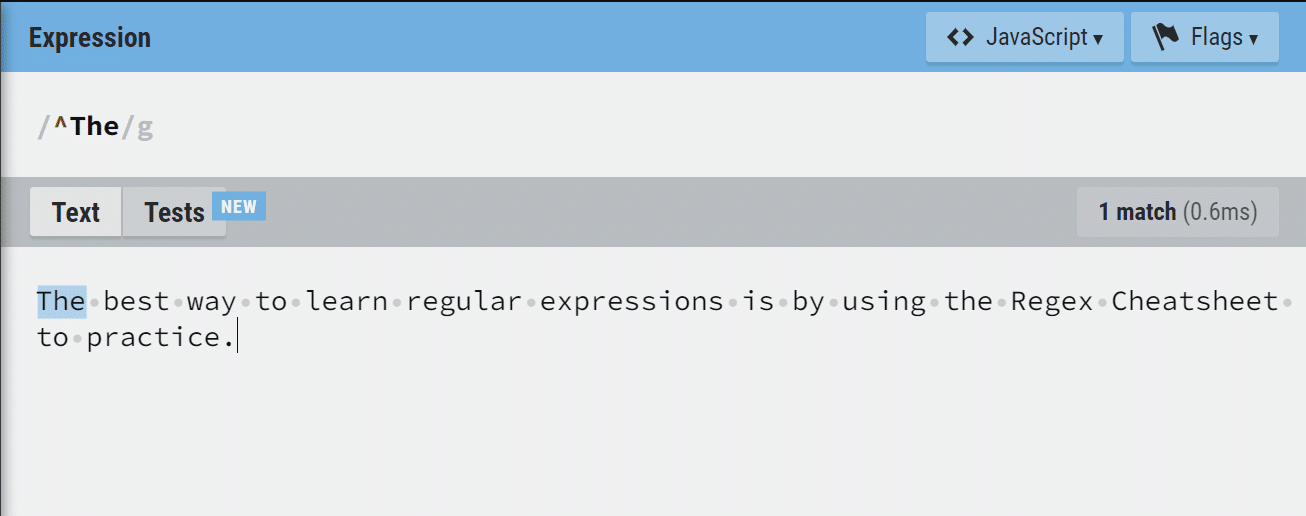
Also, let’s say we want to match the word dog only if it appears at the end of the sentence. We can use the pattern below:
/dog$/
Character Classes in Regex
A character class is simply a group or range of characters enclosed in a square bracket. The regex engine matches characters in the brackets.
To use it, you simply place all the characters you want to match side by side in the square brackets. For example, let’s look at the regular expression pattern:
/[abc]at/The example below, it matches cat and bat because they start with either b or c.

1. Range
Supposing you want to use the character class function to match any character within the range of a to m, you would have to type each alphanumeric character out individually. This can be quite stressful.

You can avoid this by using the range symbol ‘–‘. You can use it to specify a matching range for several characters, including alphanumeric or Unicode characters.
For example, you can if you want to match a character within the range of c to j, you can write as it is below:
/[c-j]/If you want to match a character within the range of a-z, or 3-9, you can also write:
/[a-z3-9]/2. Negation
The negation character matches all characters except the ones listed in the character class. Its symbol is ‘^‘ and it should precede all the characters in the class.
For example, if you want to match words ending with at apart from those starting with ‘c‘, you can use:
/[^c]at/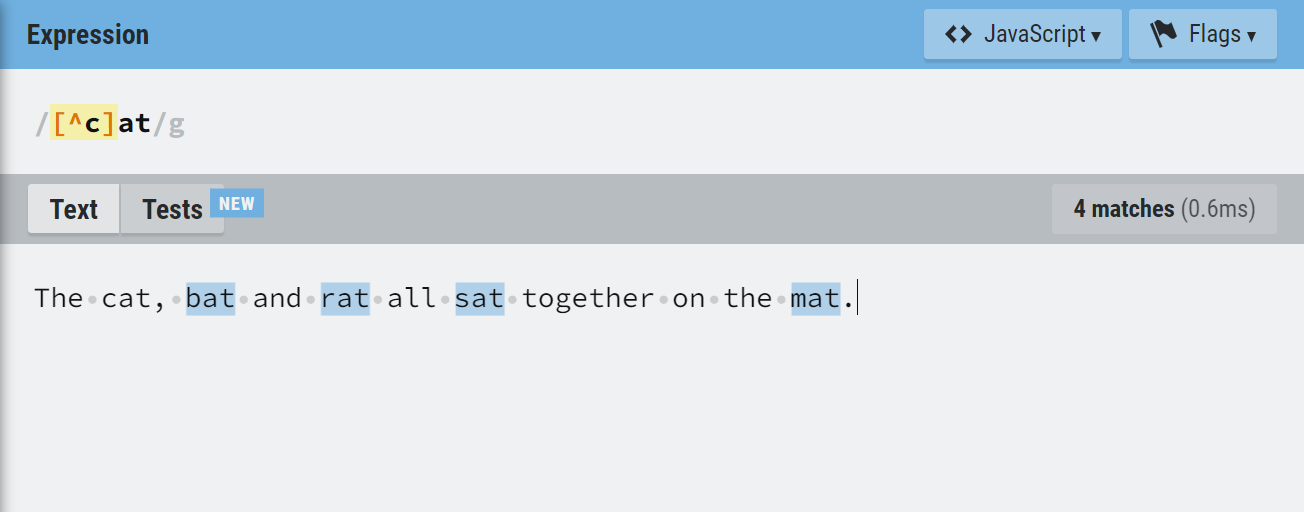
Regex Flags
Regex flags are modifiers you can add to your regular expression pattern to perform specific functions. With these flags, you can make your pattern case-insensitive, greedy, etc.
Let’s look at them:
a – Enables ASCII-only special character matching
g – Looks for all the matches within the text. Without it, only the first match is returned
i – Makes the regular expression case-insensitive.
m – Turn on multi-line mode which Ensures multiline inputs are treated as multiple lines, instead of one single string. So, ^ and $ respect the newline character and match the beginning and end of every string.
s – Makes the . character match new lines too.
To use the flag, you specify it after the regular expression pattern. For example:
/a-z0-9/iThis matches alphanumeric characters regardless of the case.
Also, if we take a look at some of our earlier example screenshots, we can see that the g flag is already enabled.

Without the flag, the regex engine would simply stop searching after the first match which is rat.

Unicode Character Classes in Regex
Sometimes, you might need to write regex that matches characters that aren’t in the normal alphanumeric range. These characters can include emojis, special characters, Chinese characters, control characters, etc.
You can match any character as long as they are under the Unicode rule.
To match them, you can use the Unicode character class with your regular expressions. You can use them by following the format below:
uxxxxAdvanced Techniques for Regex
1. Grouping and Capturing
When working with regular expressions, you may need to group multiple patterns together. This is where grouping and capturing come in.
Grouping allows you to apply quantifiers, alternations, and other operators to multiple patterns at once. Capturing allows you to extract specific parts of the matched text. To group patterns together, use parentheses.
For example, the pattern `(ab)+` matches one or more occurrences of the sequence “ab“. To capture a specific part of the matched text, use a capturing group.
Also, look at the pattern below
/(d{3})-(d{2})-(d{4})/It captures a phone number in the format “555-55-5555“.
2. Lookahead and Lookbehind
Lookahead and lookbehind are zero-width assertions that allow you to match patterns based on their context.
Lookahead matches a pattern only if it is followed by another pattern.
Lookbehind matches a pattern only if it is preceded by another pattern.
To use lookahead, use the syntax below:
/(?=<pattern>)/ For example, the pattern below matches any word that is followed by the letters “ing“.
/w+(?=ing)/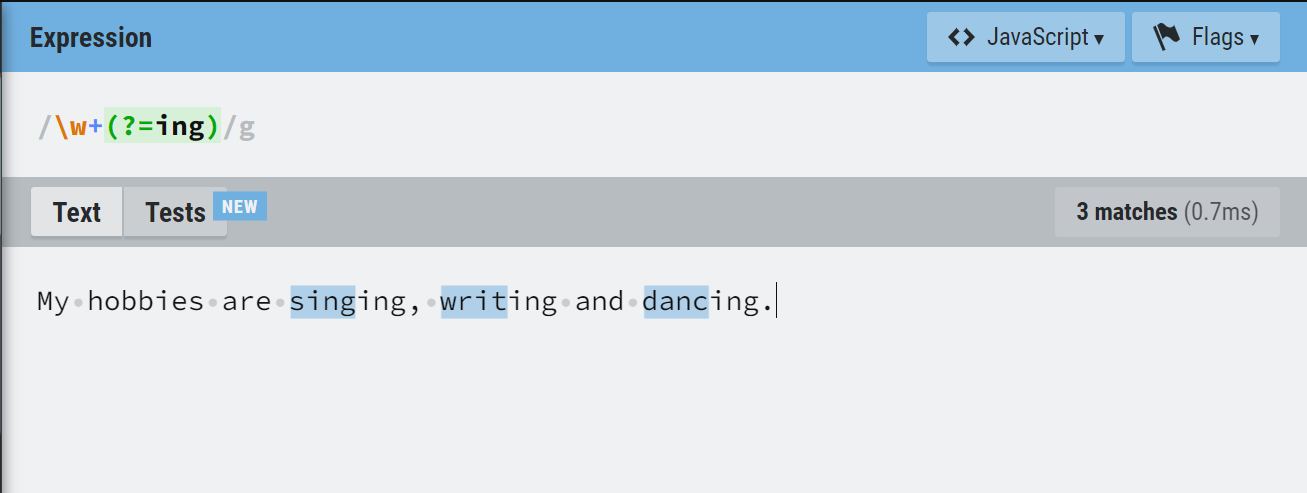
To use lookbehind, use the syntax:
/(?<=pattern)/For example, the pattern matches a decimal number preceded by a dollar sign.
(?<=$)d+.d{2}`3. Backreferences
Backreferences allow you to refer to a previously captured group within the same regex. This is useful for matching patterns that repeat.
To use a backreference, use the syntax `n`, where n is the number of the captured group.
For example, let’s look at the pattern below
/(w+)s1/It matches any word repeated twice, such as “hello hello” or “bye bye“.
Overall, these advanced techniques can help you write more powerful regular expressions that can handle complex patterns.
Keep in mind that they may not be supported by all regex engines, so be sure to check the documentation for your specific implementation.
Common Regex Patterns
If you’re just starting out with regular expressions, it can be helpful to know some common patterns that you’re likely to encounter.
In this section, we’ll cover some of the most common patterns and provide examples for each.
1. Email Addresses
One of the most common uses for regular expressions is validating email addresses. Here’s an example pattern you can use:
/[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/
This pattern matches any string that looks like an email address, including addresses with special characters like periods and plus signs.
2. Phone Numbers
Another common use for regular expressions is validating phone numbers. Here’s an example pattern you can use:
/d{3}-d{3}-d{4}/
This pattern matches any string that looks like a phone number in the format of ###-###-####.
3. URLs
Finally, regular expressions can be used to validate URLs. Here’s an example pattern you can use:
/^(http|https)://[a-z0-9]+([-.]{1}[a-z0-9]+)*.[a-z]{2,5}(([0-9]{1,5})?/.*)?$/
This pattern matches any string that looks like a URL, including both HTTP and HTTPS protocols and URLs with subdomains.
Remember, these are just a few examples of common patterns you might encounter while working!
Regular expressions can be used for a wide variety of tasks, so it’s important to familiarize yourself with the basics and build from there.
Final Thoughts
Congratulations! You’ve just learned about regular expressions and how they can be used to manipulate text.
By using a combination of symbols and characters, regular expressions can help you search, match, and replace text in a more efficient and precise manner than traditional string manipulation methods.
Remember that regular expressions can be a powerful tool, but they can also be complex and difficult to understand at times. Take your time to understand the syntax and logic behind regular expressions, and don’t be afraid to experiment with different patterns and expressions to see how they work.
If you enjoyed our guide, you can also check out our Python cheat sheet and Numpy cheat sheet!

