
SQL offers a plethora of tools and clauses to streamline data analysis. Among these, the PARTITION BY clause stands out for its unique ability to segment data into meaningful partitions.
In SQL, the PARTITION BY clause is used in conjunction with window functions to segment a result set into distinct partitions or groups. Unlike GROUP BY which aggregates data, PARTITION BY retains individual rows, enabling users to apply functions like rankings or cumulative sums within each defined partition while still displaying detailed records.
This article will discuss SQL’s PARTITION BY clause’s uses and benefits in data science. Understanding its role in organizing and analyzing complicated data can help you tackle difficult data management tasks and improve decision-making.

Let’s dive in!
What is PARTITION BY in SQL?

The ability to segment and analyze data is paramount in SQL. While there are multiple tools to achieve this, the PARTITION BY clause holds a special place due to its versatility and precision. This section will introduce you to the PARTITION BY clause, its purpose, and how to use it effectively in your SQL queries.
In SQL, the PARTITION BY clause is employed alongside window functions to segment a result set into distinct partitions or groups. This allows for specific calculations to be executed across defined subsets of data.
A key distinction between PARTITION BY and GROUP BY is that while GROUP BY aggregates data, PARTITION BY maintains individual rows. This means you can apply functions like rankings or cumulative sums within each partition and still view detailed records.
Basic Syntax for PARTITION BY
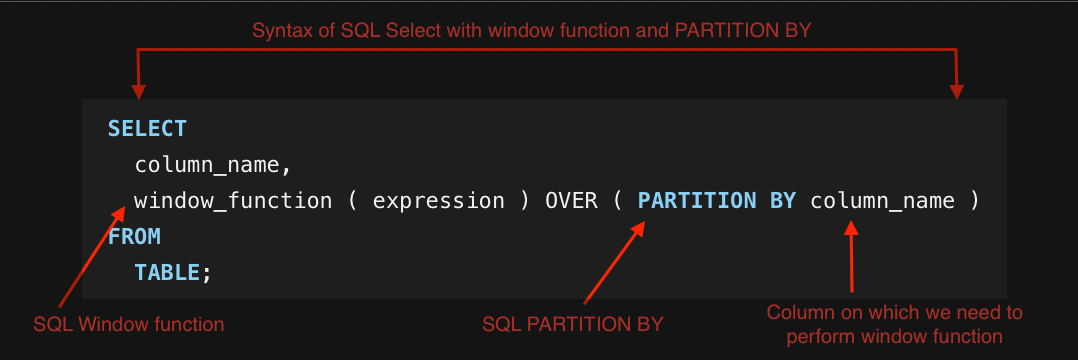
The general structure of a PARTITION BY clause is straightforward. When used with a window function, it typically follows this pattern:
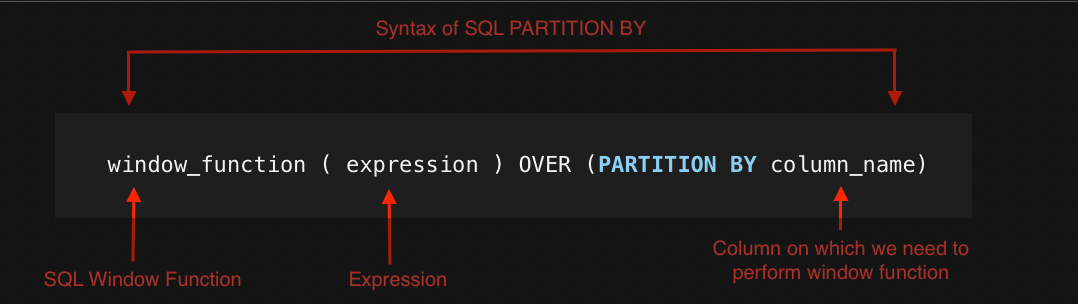
- window_function is the specific window function you want to apply.
- expression is the column or value you want to perform the window function on.
- PARTITION BY the column you want to partition the data by.
For instance, if you wanted to rank employees in each department based on their salaries, you could use the following query:


In this example, the PARTITION BY clause divides the data by department, and the RANK() function then assigns a rank to each employee within their respective department based on their salary.
Next, we’ll take a look at how you can use PARTITION BY in your databases.
How to Use PARTITION BY in SQL
As with many tools in SQL, while the basics of the PARTITION BY clause can be grasped quickly, true mastery lies in understanding its applications and nuances.
This section aims to shed light on some of the uses of PARTITION BY and provide tips to optimize its usage, ensuring that you can navigate any scenario with confidence.
1. Using ‘PARTITION BY’ with Multiple Columns
It’s possible to partition data based on multiple columns, providing a more granular level of segmentation. This can be especially useful when you need to analyze data across multiple dimensions.
SELECT year, region, product, sales,
SUM(sales) OVER (PARTITION BY year, region ORDER BY product) as cumulative_sales_by_product
FROM sales_data;
In this example, sales data is partitioned by both year and region, allowing for a cumulative sum of sales for each product within those partitions.
2. Combining PARTITION BY with ORDER BY within Window Functions
The ORDER BY clause can be used within window functions to determine the order of rows within a partition. This is particularly useful for functions like ROW_NUMBER(), RANK(), and cumulative aggregates.
SELECT team, player_name, goals_scored,
RANK() OVER (PARTITION BY team ORDER BY goals_scored DESC) as rank_within_team
FROM soccer_stats;
Here, players are ranked within their teams based on the number of goals they’ve scored.
3. Ranking Functions
SQL ranking functions let you rank each row in a result set depending on defined criteria. These functions, such as RANK(), DENSE_RANK(), and ROW_NUMBER(), are used with the OVER() clause and the PARTITION BY clause to partition the result set and apply the ranking function.
To rank sales by quantity, grouped by product, execute the following SQL query with the RANK() function:

4. Subqueries and Aggregates
Subqueries are necessary for building sophisticated SQL queries because they let you use one query’s results in another. A scalar subquery returns one value for the main query’s SELECT, WHERE, or HAVING clause.
To calculate statistics for each data partition, use aggregate functions like SUM() or COUNT() in a subquery.
Subqueries can reveal data segments when used with the PARTITION BY clause. For example, our sales_data table calculates product sales:
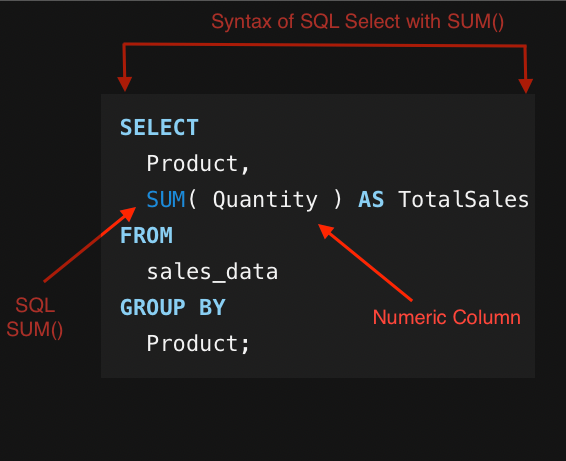
To retrieve the percentage of total sales that each sale contributes, you can use a scalar subquery within the SELECT clause:
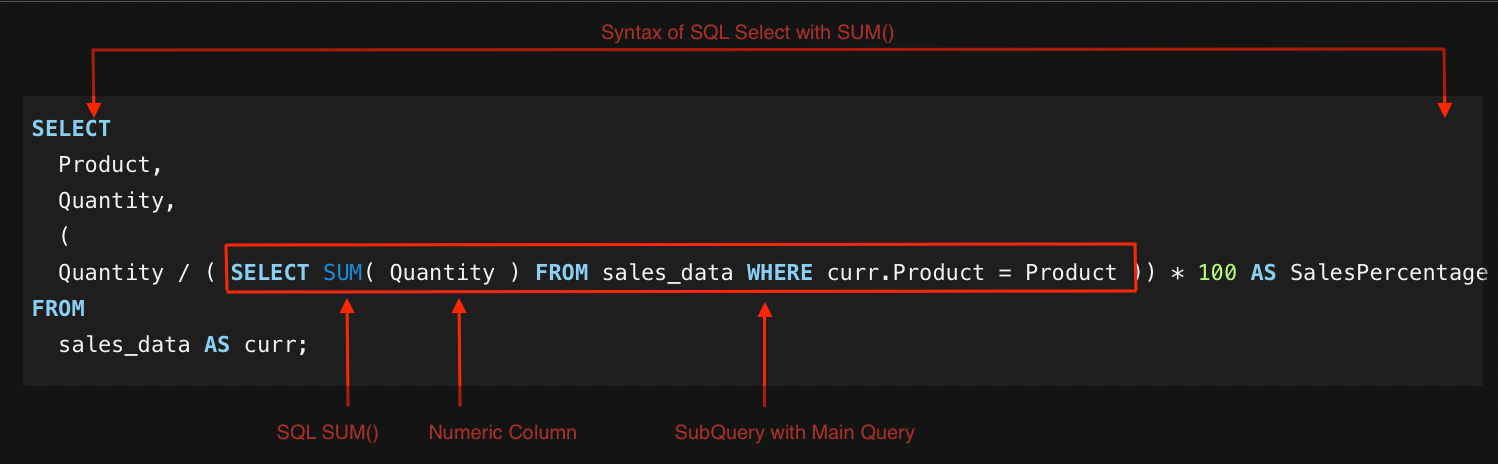
5. Top N Per Group Results
The PARTITION BY clause and window methods efficiently get the top N results per group. This method is useful for ranking or filtering data by criteria.

To extract the top 3 sales with the highest quantity for each product from the sales_data table, use the following query:
WITH RankedSales AS (
SELECT Product, Quantity, SaleDate, ROW_NUMBER() OVER (PARTITION BY Product ORDER BY Quantity DESC) as RowNum
FROM sales_data
)
SELECT Product, Quantity, SaleDate
FROM RankedSales
WHERE RowNum <= 3;This query uses the ROW_NUMBER() function to assign a unique row number to each sale in each product division, organized by the amount in descending order. Then, only the top 3 sales with the highest amount for the specified column for each product are filtered.
Combining PARTITION BY with Window Functions
Having grasped the essence of the PARTITION BY clause, it’s time to elevate our understanding by diving into its synergy with window functions.
Window functions, a powerful subset of SQL functions, operate over a set of table rows and return a single aggregated value for each row. They allow users to perform calculations across a set of table rows that are related to the current row.
When combined with PARTITION BY, these functions can produce results tailored to specific data partitions, offering a depth of analysis that’s hard to achieve otherwise.
Unlike aggregate functions, which return a single value for a group of rows, window functions return a single value for each row from the original dataset based on the provided window definition.
Common window functions include:
- ROW_NUMBER(): Assigns a unique sequential integer to rows within a partition.
- RANK(): Assigns a unique rank to each distinct row within a partition.
- DENSE_RANK(): Similar to RANK(), but without gaps between rank values for consecutive rows.
- SUM(), AVG(), and others: Aggregate functions that, when used as window functions, can compute cumulative sums, moving averages, etc.
Examples of PARTITION BY with Window Functions
1. Sequential Numbering within Partitions

This query assigns a sequential number to each employee based on their hire date within their respective department. Here’s how it works:
- SELECT Statement: The query is selecting the columns department and employee_name from the employees table.
- ROW_NUMBER() Function: This is a window function that assigns a unique number to each row within a result set. The numbering starts at 1 for the first row in each partition.
- PARTITION BY Clause: The PARTITION BY department part divides the result set into partitions or groups based on the department column. Essentially, it assigns a unique sequence number to each employee within their specific department.
- ORDER BY Clause: The ORDER BY hire_date part sorts the rows within each partition by the hire_date column in ascending order. This ensures that the sequence numbers are assigned based on the order in which employees were hired within each department.
The final result will be a list of departments, employee names, and an employee_sequence column that represents the unique sequence number for each employee within their department, based on their hire date.
2. Calculating Cumulative Sales:

Here, for each product, the sales are cumulatively summed up based on the date. Here’s how it works:
- SELECT Statement: The query is selecting the columns date, product, and sales from the sales_data table.
- SUM() Function: This is a window function that calculates the sum of the sales column.
- PARTITION BY Clause: The PARTITION BY product part divides the result set into partitions or groups based on the product column. Essentially, it calculates the cumulative sales separately for each product.
- ORDER BY Clause: The ORDER BY date part sorts the rows within each partition by the date column in ascending order. This ensures that the cumulative sum is calculated in chronological order for each product.
The final result will be a list of dates, products, and sales, along with a cumulative_sales column that represents the running total of sales for each product up to that date.
3. Ranking Scores within Categories
The following example ranks players based on their scores within each game category.

Here’s a breakdown of how it works:
- SELECT Statement: The query is selecting the columns category, player_name, and score from the game_scores table.
- RANK() Function: This is a window function that assigns a rank to each row within a result set. The rank is based on the score column, and rows with the same score will have the same rank.
- PARTITION BY Clause: The PARTITION BY category part divides the result set into partitions or groups based on the category column. Essentially, it’s like creating separate ranking competitions for each category.
- ORDER BY Clause: Within each partition created by the PARTITION BY clause, the ORDER BY score DESC part sorts the rows by the score column in descending order. This means that the player with the highest score in each category will get the rank of 1.
The final result will be a list of players with their corresponding categories and scores, along with a rank that is specific to each category. Players in the same category will be ranked against each other, and the ranking will restart for each new category.
The combination of PARTITION BY with window functions unlocks a realm of analytical capabilities in SQL. It allows for intricate calculations tailored to specific data segments, providing insights that are both deep and broad.
Final Thoughts
The PARTITION BY clause in SQL is a powerful tool that enables us to divide a result set into partitions or segments, allowing for more granular control over calculations and rankings.
Whether it’s ranking players in a game, calculating cumulative sales, or identifying top performers within various categories, PARTITION BY offers a flexible and efficient way to analyze data within specific groups or categories.
PARTITION BY is more than just a technical aspect of SQL; it’s a gateway to insightful data analysis. By mastering this concept, you can unlock deeper insights, create more efficient queries, and elevate your data-handling capabilities!
If you’d like to learn more about how to use SQL, particularly in Power BI, check out the video below:
Frequently Asked Questions
How to use ORDER BY with PARTITION BY in SQL?
To use ORDER BY with PARTITION BY in SQL, you can leverage the ROWS BETWEEN clause in your OVER clause. Here is an example:

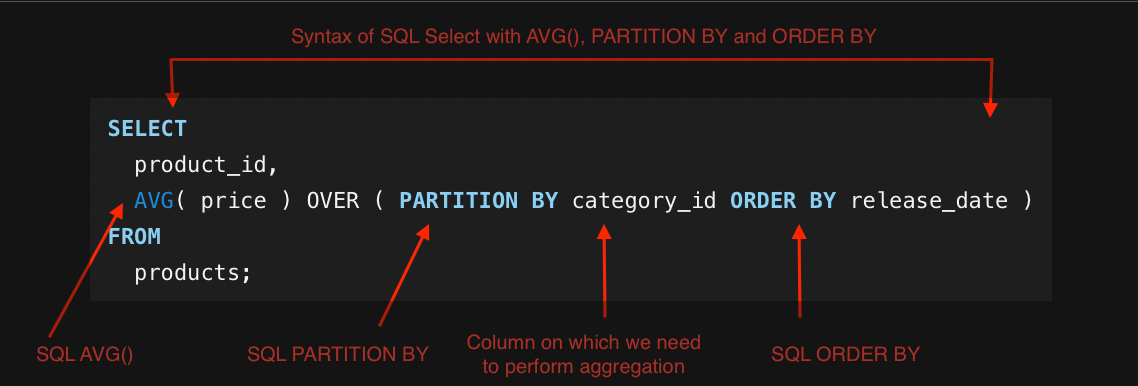
With this query, you can apply window functions over partitions defined by the PARTITION BY clause and have them ordered by another column within the partition.
What are the differences between PARTITION BY and GROUP BY?
Both PARTITION BY and GROUP BY segment data, but for different reasons. GROUP BY groups rows with comparable values into one row, while PARTITION BY maintains all rows and allows you to calculate over column-defined partitions. GROUP BY works with aggregate functions and PARTITION BY with window functions.
How is PARTITION BY implemented in MySQL?
In MySQL, PARTITION BY can be used with window functions within the OVER clause. Here’s an example:
SELECT column1, column2, RANK() OVER (PARTITION BY column1)
FROM table;This query would calculate the rank of each row within the partition created by the column1 values.
What are the similarities between the PARTITION BY clause and the OVER clause?
SQL’s OVER clause’s PARPARTITION BY partitions data. Both are used with window functions to calculate over partitions or windows. The PARTITION BY clause in the OVER clause is optional; window functions can be used without it.
Can you use PARTITION BY in PostgreSQL?
Yes, you can use PARTITION BY in PostgreSQL with window functions. Here’s an example:
SELECT column1, column2, SUM(column3) OVER (PARTITION BY column1)
FROM table;This query calculates the sum of column3 values for each partition based on column1 in PostgreSQL.
How to utilize PARTITION BY in Snowflake?
In Snowflake, you can use PARTITION BY with window functions within the OVER clause. Here’s an example:
This query calculates the average of column2 values for each partition based on column_name in Snowflake.


