
When it comes to data science and machine learning, the Julia programming language has been making a lot of noise. Why? Because it is designed to handle the heavy lifting of data analysis and machine learning algorithms.
Julia is a high-level, high-performance programming language that was specifically developed for scientific computing and data analysis. It is designed to be fast, easy to read, and write code in, and it can be used for many different tasks within the field of data analysis.
Julia’s design was motivated by the need for a programming language that could provide the speed and performance of low-level languages like C, while also being user-friendly and easy to learn like high-level languages like Python.

In this article, we will be discussing how you can leverage Julia’s power to perform machine learning tasks.
We will begin by going over some of the basics of the Julia language and how it compares to Python and R.
Julia Programming Basics

The Julia programming language is an open-source, high-level, and high-performance language designed for technical computing. It is often used in scientific fields such as machine learning, physics, and engineering, as well as for data analysis and visualization.
Why Julia?
Julia was designed with the aim of combining the best features of other programming languages. Some of the key features that make Julia unique are:
- Performance: Julia is known for its performance and is often compared to low-level languages like C and Fortran. It achieves this through just-in-time (JIT) compilation, where code is compiled to machine code at runtime, and type inference, where types are determined during compilation to optimize code execution.
- Multiple dispatch: Julia is a multiple dispatch language, which means that it can dispatch functions based on the types of multiple arguments. This allows for greater flexibility and more efficient code organization.
- Data analysis: Julia provides a wide range of packages for data analysis, including DataFrames.jl, which offers similar functionality to the popular pandas library in Python.
- Parallel computing: Julia has built-in support for parallel computing, which allows for the efficient use of multiple cores and distributed computing. This makes it well-suited for handling large datasets and complex computations.
- Interoperability: Julia can easily interface with other languages, including Python, C, and R, making it easy to integrate with existing codebases and take advantage of the extensive libraries available in those languages.
- Ease of use: While Julia is a powerful language, it also aims to be user-friendly, with a clean and readable syntax that is easy to learn and use.
What is the Syntax of Julia?
The syntax of Julia is similar to that of Python, and it uses whitespace to define code blocks. Some basic syntax features of Julia include:
- Variables: Variables in Julia are declared using the = sign, and the type of the variable is inferred from the value assigned to it.
- Control structures: Julia has control structures like if, for, and while loops, and uses the end keyword to denote the end of a block.
- Functions: Functions are defined using the function keyword, and can have optional type annotations. Functions can also be defined using the shorthand f(x, y) = x + y.
- Comments: Single-line comments start with a #, and multi-line comments are enclosed within #= and =#.
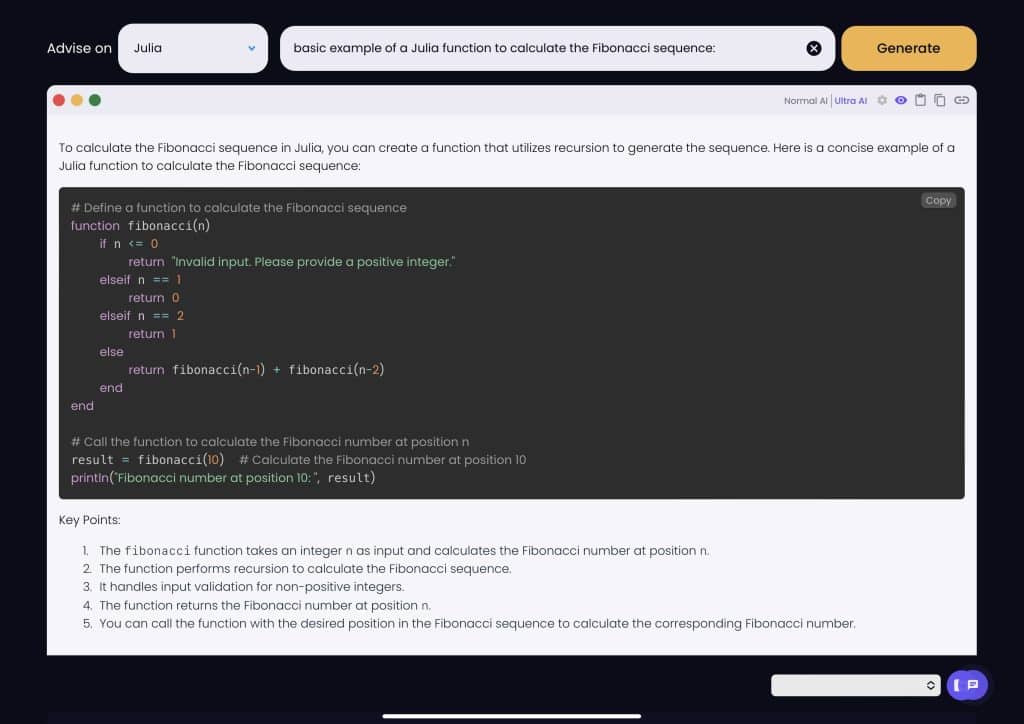
Here’s a basic example of a Julia function to calculate the Fibonacci sequence:

How to Work With Julia
There are multiple ways to work with Julia, and we will cover some of the popular ones.
1. Using the Julia REPL
The Julia REPL (Read-Eval-Print Loop) is a command-line interface where you can type Julia commands and see the results immediately. To start the REPL, simply type julia in your terminal or command prompt. You can use the REPL to write and execute Julia scripts, or to test and debug your code.
To run a Julia script in the REPL, you can use the include function. For example:
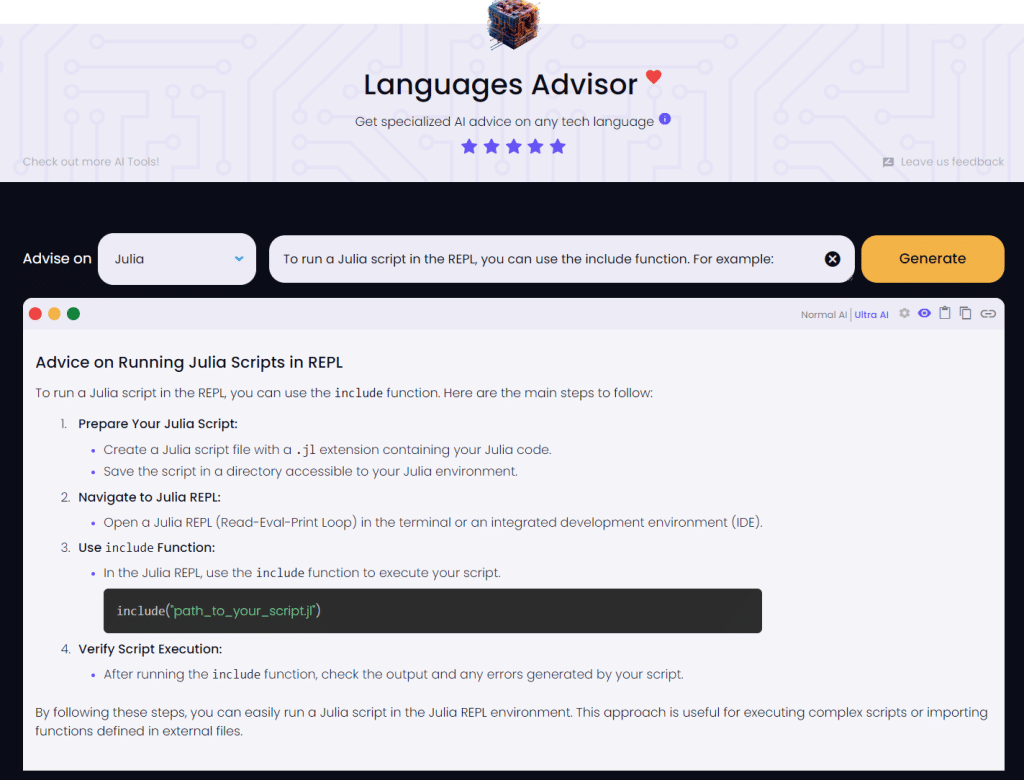
This will run the script my_script.jl, and you will see the output in the REPL.
2. Using Julia with Jupyter
Julia has strong support for Jupyter notebooks, which are an interactive way to write and execute code. You can install Jupyter notebooks with the IJulia package, which you can add using the package manager:
Then you can start a Jupyter notebook server using the following command:
This will open up a Jupyter notebook in your web browser, and you can create a new notebook by clicking on New and then selecting Julia.
You can then write and execute your Julia code in the notebook, and it will show the output below each cell. You can also use Jupyter to create visualizations, like plots, by using the Plots package.
3. Using Julia with Visual Studio Code
Visual Studio Code is a popular open-source code editor, and it has strong support for Julia through the Julia extension. You can install the extension by going to the Extensions tab in Visual Studio Code, searching for Julia, and clicking Install.
Once you have the extension installed, you can open a Julia file in Visual Studio Code and start writing and executing code. You can run the current file by right-clicking on the editor and selecting Run Julia File in REPL, or by pressing Ctrl+Enter. This will open a REPL and execute the code in the file.
You can also use the Visual Studio Code debugger with Julia by adding breakpoints in your code and clicking Debug in the sidebar, and then clicking the Run button.
4. Using Julia with IDEs
In addition to Visual Studio Code, there are several other IDEs that have strong support for Julia, such as:
- Juno for Atom: Juno is an IDE specifically designed for Julia, and it is built on top of the Atom editor. You can install Juno by going to the Settings tab in Atom, clicking on Install, and searching for Juno.
- Emacs: There are several packages available for Emacs that provide support for Julia, such as julia-mode and eglot-jl. You can install these packages through the Emacs package manager.
- Vim: There are also several plugins available for Vim that provide support for Julia, such as julia-vim and YouCompleteMe. You can install these plugins using your preferred Vim plugin manager.
- Sublime Text: Sublime Text has a Julia package available that provides syntax highlighting and some other features. You can install the package through the Sublime Text package manager.
- PyCharm: PyCharm has a Julia plugin available that provides syntax highlighting and some other features. You can install the plugin by going to Settings > Plugins > Marketplace, searching for Julia, and clicking Install.
- RStudio: RStudio has a Julia plugin available that provides syntax highlighting and some other features. You can install the plugin by going to Tools > Install Packages, searching for Julia, and clicking Install.
How to Use Julia for Machine Learning

In the world of machine learning, Julia is making a strong case for itself due to its ability to write high-performance, efficient code. The language has an extensive ecosystem of packages and tools for data analysis and machine learning, which makes it an excellent choice for ML tasks.
In this section, we will discuss how to use Julia for machine learning.
Getting Started With Julia Machine Learning
The first step to getting started with Julia for machine learning is to install the Julia programming language on your system. You can download Julia from the official website and follow the installation instructions provided there.

Once you have Julia installed, you can start using it for machine learning by loading the necessary packages. Julia has several machine learning libraries, including the popular Flux.jl and MLJ.jl. You can install these packages using the Julia package manager:
How to Install Flux.jl
Flux.jl is a powerful and flexible library for machine learning in Julia. It is designed to be simple and easy to use, making it a great choice for beginners and experts alike. You can install Flux.jl using the Julia package manager:
The Flux.jl library offers a wide range of functionality for machine learning, including various types of neural networks, optimization algorithms, and data preprocessing tools.
To get started, you can read the Flux.jl documentation and tutorials available on their official website.
How to Install MLJ.jl
MLJ.jl is a versatile and comprehensive machine learning library for Julia. It provides a wide range of tools and algorithms for data preprocessing, model training, and model evaluation. You can install MLJ.jl using the Julia package manager:
The MLJ.jl library offers a variety of functionality, including a unified API for interacting with different models, data types, and model evaluation metrics. It also provides tools for model tuning and model ensembling.
To get started with MLJ.jl, you can read the documentation and tutorials available on the official website.
How to Preprocess Data in Julia
In machine learning, preprocessing data is a crucial step that involves transforming raw data into a format suitable for training models. This can include tasks like normalizing features, handling missing values, and encoding categorical variables.
Julia provides a range of tools and libraries to perform data preprocessing tasks. The Flux.jl library, for example, provides functions for loading and preprocessing data.
Another popular library for data preprocessing is the DataFrames.jl package, which provides functionality for working with tabular data, including data cleaning and transformation.
To preprocess data in Julia, you can follow these steps:
- Load the raw data into Julia using a suitable data format, such as a CSV file or an SQL database.
- Use the available functions in the chosen package to preprocess the data according to your needs. For example, you might want to normalize features using the Flux.normalize function, or impute missing values using the DataFrames.impute function.
- Once the data is preprocessed, you can split it into training and testing datasets using functions like Flux.train_test_split.
How to Train and Evaluate Machine Learning Models in Julia
After preprocessing the data, you can start training and evaluating machine learning models in Julia. To do this, you can follow these steps:
- Choose a suitable machine learning model from the available options. Common models include linear regression, decision trees, and neural networks.
- Create an instance of the chosen model using its constructor function. For example, you can create a neural network model using the Flux.Chain constructor.
- Train the model on the training dataset using the Flux.train! function. This function requires the model, the training data, and a loss function to minimize.
- After training the model, you can evaluate its performance on the test dataset using suitable evaluation metrics. Common metrics include accuracy, precision, recall, and F1-score.
- If the model’s performance is not satisfactory, you can try different hyperparameters or preprocessing techniques to improve it.
- Once you are satisfied with the model’s performance, you can use it to make predictions on new, unseen data.
How to Optimize and Tune Models in Julia
Optimizing and tuning machine learning models is an essential part of the machine learning workflow. It involves finding the best set of hyperparameters for a given model and dataset to achieve the best possible performance.
To optimize and tune models in Julia, you can use tools such as the Flux.Optimiser module, which provides various optimization algorithms like gradient descent, ADAM, and RMSProp.
The MLJ.CrossValidation module is also useful for tuning models. It provides functions to perform cross-validation, which helps in choosing the best set of hyperparameters.
You can use the following steps to optimize and tune your models:
- Define a hyperparameter search space using the MLJ.Range module.
- Perform cross-validation using the MLJ.crossvalidate function with the chosen model and hyperparameter search space.
- Find the best hyperparameters by examining the cross-validation results.
- Train a new model using the best hyperparameters and the entire training dataset.
- Evaluate the final model’s performance on the test dataset.
- If the model’s performance is still not satisfactory, you can repeat the process with a different hyperparameter search space.
Final Thoughts

Julia is a powerful programming language with a growing community of users and a vast ecosystem of tools and libraries. Its speed, simplicity, and versatility make it an excellent choice for anyone interested in machine learning and data science.
Whether you are an experienced data scientist looking for a more efficient tool or a beginner trying to learn the ropes, Julia has something to offer. So, give it a try and see what it can do for you.
Try out the Languages Advisor in Data Mentor to learn almost anything about Julia!

Frequently Asked Questions

What is Julia in machine learning?
Julia is a high-level, high-performance programming language that is becoming increasingly popular in the field of machine learning. It is designed for scientific computing and data analysis, and its fast computation speed and easy-to-read syntax make it well-suited for machine learning tasks.

Why is Julia preferred over Python in machine learning?
Julia is preferred over Python in some machine learning applications due to its speed and performance. It is often faster than Python for large-scale computations, which can be important in machine learning, especially when dealing with big data.
What is the main difference between Julia and Python in machine learning?
The main difference between Julia and Python in machine learning is their performance. Julia is generally faster than Python for large-scale computations, making it a better choice for certain machine learning tasks, especially when dealing with big data. However, Python has a larger ecosystem and more machine learning libraries, which can make it easier to get started with machine learning.
Is Julia better than Python for machine learning?
Whether Julia is better than Python for machine learning depends on the specific use case. Julia is faster than Python for large-scale computations, making it a better choice for certain machine learning tasks, especially when dealing with big data. However, Python has a larger ecosystem and more machine learning libraries, which can make it easier to get started with machine learning.
Is Julia easier than Python for machine learning?
The difficulty of learning Julia compared to Python for machine learning depends on your background and the specific task at hand. If you are already familiar with Python, you may find it easier to get started with machine learning in Python, as it has a larger ecosystem and more machine learning libraries. However, Julia’s syntax is often considered more straightforward, and its speed can make certain tasks easier to implement.
How is machine learning in Julia compared to R?
Machine learning in Julia compared to R is generally faster due to Julia’s performance. Julia is designed for scientific computing and data analysis, and its speed and ease of use make it well-suited for machine learning. R also has a wide range of machine learning libraries and tools, but Julia’s performance advantage can make it a better choice for large-scale computations and big data applications.



