
In a world where data is king, the ability to harness the power of data warehousing and execute transformative querying tactics is the key to unlocking valuable insights and driving informed decision-making.
Transformative querying tactics for data warehouses enable users to dig deeper into their data, analyze trends, and uncover valuable insights. With these tactics, users can modify, transform, and optimize their data in ways that enhance its quality, relevance, and usefulness. These tactics empower users to maximize the potential of their data, drive informed decision-making, and stay ahead in the competitive landscape.
In this article, we’ll dive into the transformative querying tactics for data warehouses that go beyond storage, exploring how you can supercharge your data analysis and unlock its true potential.

Let’s get into it!
What Are Transformative Querying Tactics?

Transformative querying tactics are advanced techniques used to manipulate and extract valuable insights from data stored in data warehouses.
These tactics go beyond basic data retrieval and are designed to help users derive deeper meaning and value from their data.
What Is a Data Warehouse?

A data warehouse is a centralized repository that stores structured data from one or more sources. It is designed to support business intelligence (BI) and analytics applications.
Data warehouses are used to store and manage large volumes of data for reporting and analysis. They provide a single, unified source of truth for an organization’s data, allowing users to make informed decisions based on reliable, consistent information.
6 Transformative Querying Tactics

Data warehousing has become increasingly popular as organizations look to gain insights from the vast amount of data they collect.

Here are some transformative querying tactics that go beyond the basic storage capabilities of data warehouses and enable organizations to harness the power of their data for better decision-making.
1. Aggregations
Aggregations are a way to summarize and combine data to gain insights and identify trends. This technique is useful when dealing with large datasets and wanting to extract more meaningful information from them.
Data warehouses offer the ability to perform aggregations on various data points. By grouping and summarizing data, users can quickly identify patterns and trends.
Example of Aggregations:
Imagine you’re analyzing sales data and want to know the total sales for each product category. You could use an aggregation to group the data by product category and then calculate the sum of sales for each group.
2. Window Functions
Window functions are a powerful tool in data warehousing for performing calculations across a set of table rows that are related to the current row.
These functions enable users to perform complex analytical tasks and gain deeper insights into their data.
3. Temporal Queries
Temporal queries are used to retrieve and analyze data that is valid during specific time intervals. This is useful for analyzing historical data, as well as data that is valid for only a certain period.
In a data warehouse, temporal queries can be used to answer questions such as “What was the customer’s account balance at the beginning of the year?” or “What were the sales figures for a specific product last month?”
These queries are essential for understanding how data has changed over time and making data-driven decisions based on historical trends.
Example of Temporal Queries:
Let’s say you want to analyze the sales data for the last quarter. You can use a temporal query to filter the sales data for that specific time period.
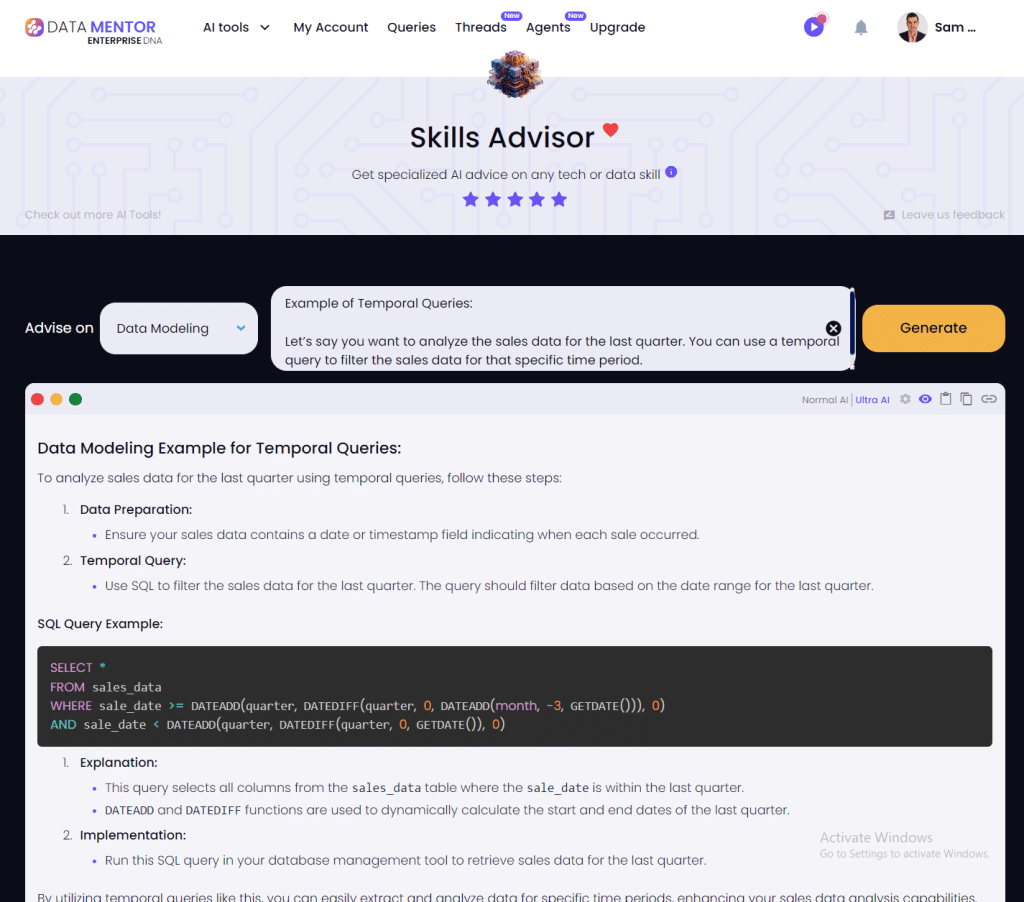
4. Recursive Queries
Recursive queries are used to work with hierarchical data structures. These queries enable you to traverse and manipulate hierarchical data, such as organizational charts or product categories.
With recursive queries, you can perform operations on each level of the hierarchy, making it easier to work with complex data structures.

Example of Recursive Queries:
Imagine you have an organizational chart that includes the hierarchy of employees in a company. You can use a recursive query to find all the subordinates of a specific manager, regardless of how deep the hierarchy goes.
5. Graph Queries
Graph queries are used to analyze and manipulate graph-structured data. These queries enable you to identify patterns and relationships within the data.
In a data warehouse, graph queries can be used to analyze data from social networks, supply chain networks, or any other networked data structure.
Example of Graph Queries:
Imagine you want to find the shortest path between two nodes in a network. You can use a graph query to perform this analysis and identify the most efficient route.
6. Predictive Queries
Predictive queries are used to forecast future outcomes based on historical data. These queries can be used to make data-driven decisions and anticipate future trends.
In a data warehouse, predictive queries can be used for tasks like sales forecasting, customer churn prediction, or inventory management.
Example of Predictive Queries:
Imagine you want to predict the sales figures for the next quarter. You can use a predictive query to analyze historical sales data and generate a forecast for the future.
4 Popular Data Warehouse Technologies

Now that we’ve gone over the transformative querying tactics and examples, you may be wondering what data warehouse technologies can help you implement these tactics.
Here are four popular data warehouse technologies that are known for their powerful and user-friendly data querying and processing capabilities.
1. Amazon Redshift
Amazon Redshift is a fully managed, cloud-based data warehouse service. It is designed to handle large-scale data analytics.
Amazon Redshift is known for its scalability and ability to process large volumes of data quickly. It offers a range of data warehousing features, including data loading, querying, and performance tuning.
Amazon Redshift uses a columnar data store, which is well-suited for data warehousing workloads.
2. Google BigQuery
Google BigQuery is a serverless, cloud-based data warehouse that is part of the Google Cloud Platform. It is designed for real-time analytics and large-scale data processing.
Google BigQuery is known for its fast query performance, thanks to its distributed architecture. It also offers a range of data warehousing features, including data visualization, machine learning integration, and support for SQL queries.
3. Snowflake
Snowflake is a cloud-based data warehouse platform that is designed for data storage, processing, and analysis. It is known for its flexibility and ability to support diverse data workloads.
Snowflake is a fully managed service that can automatically scale up or down based on demand. It offers features such as data sharing, strong data security, and support for semi-structured data.
4. Microsoft Azure Synapse Analytics
Azure Synapse Analytics, formerly known as Azure SQL Data Warehouse, is a cloud-based data warehouse platform that is part of the Microsoft Azure ecosystem.

It is designed to support both data warehousing and big data analytics workloads.
Azure Synapse Analytics offers features such as data integration, data exploration, and support for various data processing engines, including SQL, Apache Spark, and Apache Hadoop.
Each of these data warehouse technologies has its strengths and is well-suited for specific use cases.
When choosing a data warehouse technology, it is important to consider factors such as your organization’s specific requirements, budget, and existing technology stack.
Final Thoughts

Transformative querying tactics for data warehouses are the secret sauce that enables organizations to make the most of their data. By leveraging these advanced techniques, businesses can gain a deeper understanding of their data, uncover hidden insights, and make data-driven decisions with confidence.
In a world where data is increasingly valuable, the ability to query and analyze data effectively is a competitive advantage. So, embrace the power of transformative querying and take your data analysis to the next level.
Frequently Asked Questions

What are the essential components of a data warehouse?
The essential components of a data warehouse include data extraction, transformation, and loading (ETL) tools, a data storage system, and a front-end tool for data analysis and visualization.
What are the most common types of data warehouses?
The most common types of data warehouses include Enterprise Data Warehouses (EDWs), Operational Data Warehouses (ODWs), and Data Mart.
What are the key benefits of using a data warehouse?
Some of the key benefits of using a data warehouse include improved data quality and consistency, enhanced data accessibility, support for complex queries and analysis, and the ability to store large volumes of data.
What are the differences between data lakes and data warehouses?
Data lakes are designed to store raw, unstructured, or semi-structured data, while data warehouses are specifically designed to store structured data for analysis. Data lakes also support more flexible data processing and data exploration, while data warehouses are optimized for data retrieval and analysis.
What are some common data warehouse design patterns?
Common data warehouse design patterns include star schema, snowflake schema, and galaxy schema. These patterns are used to organize data into tables and relationships to support efficient data retrieval and analysis.
What are some of the most widely used data warehouse technologies?
Some widely used data warehouse technologies include Amazon Redshift, Google BigQuery, Snowflake, Microsoft Azure Synapse Analytics, and Oracle Data Warehouse.




