
Databases are an essential part of modern data management, and Structured Query Language (SQL) is one of the most popular languages used to interact with databases. When dealing with large amounts of data, optimizing your SQL queries is crucial for efficiency.
The key to optimizing SQL queries lies in indexing.
Indexing is a technique that enhances the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure.

Indexes in SQL are similar to indexes in books. They help locate information quickly by providing a pointer to where the data resides. Indexing in SQL involves creating a data structure that stores a subset of the data from one or more columns of a table, organized in a way that makes it quick and easy to find the rows in the table that match a particular search criteria.
In this article, we’ll explore the fundamentals of indexing, why it’s crucial for performance, and provide some practical tips for optimizing your queries.
Ready? Let’s get started!
The Importance of Indexing for Performance
When you first start working with a database, you might not be too concerned with its performance. But as your data grows, you’ll find that without proper optimization, simple queries can take minutes to execute.
Indexes are an essential tool in the optimization of SQL databases. They help improve the speed of data retrieval operations, allowing you to find and return the data you need more quickly. Without indexes, SQL Server has to perform a full table scan, meaning it has to look at every row in the table to find the data you’re interested in.
Indexing can be thought of as the “table of contents” of a database, which allows the database engine to find the data you’re looking for much more quickly.

When you index a column, you create an entry for each distinct value in that column that references the corresponding row(s) in the table. This allows the database to locate the specific rows that match your query without having to search through the entire table.
The speed at which you can retrieve data from your database can have a direct impact on your application’s performance. A well-indexed database can make your application more responsive and improve the overall user experience.
Indexing Basics in SQL

In SQL, indexing is a technique that improves the performance of database searches by reducing the number of database records that need to be examined. An index is a data structure that is used to quickly locate and access the rows in the table.
There are two main types of indexes in SQL:
- Clustered indexes: In a clustered index, the rows in the table are stored in the same order as the index. There can be only one clustered index per table, and it is typically created on the primary key of the table. This means that the primary key column(s) will have a clustered index by default, unless a non-clustered index is explicitly created on the primary key.
- Non-clustered indexes: A non-clustered index is a separate data structure from the table data that stores a sorted copy of the indexed columns. There can be multiple non-clustered indexes per table. Non-clustered indexes are useful for columns that are frequently searched, but not unique enough to warrant a clustered index.
In SQL, you can create an index using the CREATE INDEX statement. Here is the basic syntax:
CREATE INDEX idx_customer_id ON customers (customer_id);
To create a clustered index:
CREATE CLUSTERED INDEX IX_ClusteredIndexName
ON TableName(Column1, Column2);To create a non-clustered index:
CREATE NONCLUSTERED INDEX IX_NonClusteredIndexName
ON TableName(Column1, Column2);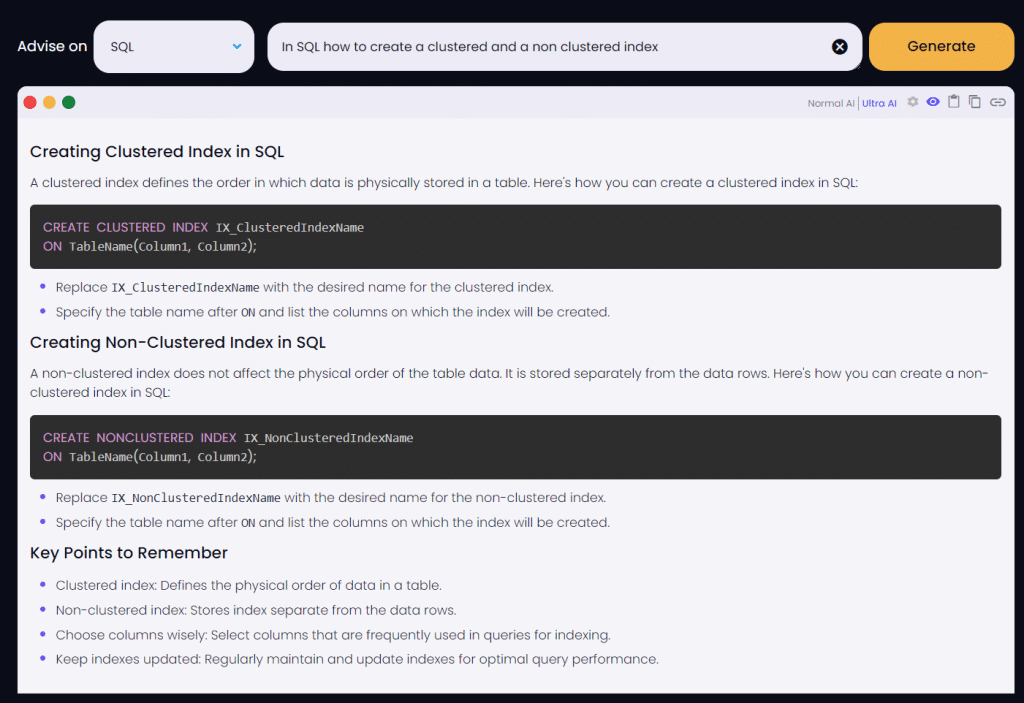
When you create an index, it’s essential to consider the trade-offs. Indexing can speed up data retrieval, but it can also slow down data modification. Every time you insert, update, or delete a row, the indexes must be updated, which can affect the performance of these operations.
Choosing the right columns to index is crucial. You should index columns that are frequently used in search conditions and have a high selectivity (i.e., columns with a large number of distinct values). Indexing columns with low selectivity can result in a large index size, which can slow down data retrieval.
In summary, indexing in SQL is a powerful tool for optimizing database performance. It helps reduce the number of database records that need to be examined, improving the speed of data retrieval. Understanding the basics of indexing, the types of indexes, and the trade-offs involved in index creation is essential for making the right decisions when optimizing your database.
Creating an Index

In SQL, creating an index involves defining the structure that will be used to speed up data retrieval. It is a multi-step process that can significantly improve the performance of your database queries.
To create an index, you will need to use the CREATE INDEX statement. This statement is used to define the name of the index, the table and column(s) that the index will be built on, and any other options or properties that are needed.
The basic syntax for creating an index is as follows:
The index_name is the name you want to give to your new index. The table_name is the name of the table on which the index will be created, and the column_name is the name of the column in the table that the index will be based on.
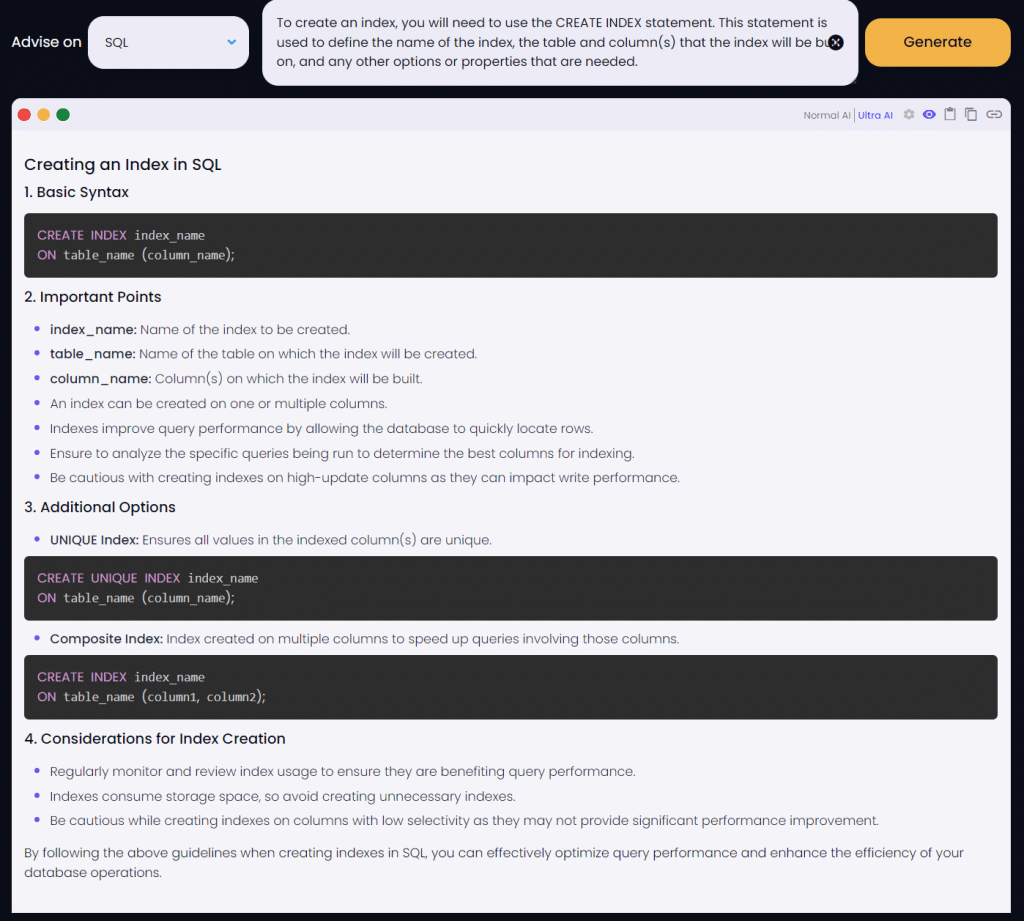
When creating an index, you will need to consider the following factors:

- Index Type: SQL Server supports different types of indexes, including clustered, non-clustered, unique, and filtered indexes. You should choose the index type that best suits your data and query requirements.
- Column(s): An index can be created on one or more columns in a table. The order of the columns in the index definition can impact the index’s performance, especially in the case of composite indexes.
- Index Name: Choose a meaningful name for your index. The index name should be unique within the database and should follow any naming conventions that your organization has in place.
- Table Name: Specify the name of the table where the index will be created.
- Column Name: Specify the name of the column(s) that the index will be based on.
- Options: Depending on the index type, you may need to specify additional options such as the fill factor, sort order, or padding.
- Index Maintenance: Regularly update and maintain your indexes to ensure optimal performance. This may involve reorganizing or rebuilding indexes, as well as updating index statistics.
After creating the index, you can use the DROP INDEX statement to remove it if necessary. Properly maintaining and optimizing your indexes is essential for the overall performance and efficiency of your SQL database.
In summary, creating an index in SQL is a crucial step in optimizing your database. By carefully choosing the index type, columns, and options, you can significantly improve the speed and efficiency of your database queries. Regularly maintaining your indexes and keeping them up-to-date is also essential for long-term performance.
Practical Tips for Optimizing SQL Queries

Optimizing SQL queries is essential for improving the performance of your database. To ensure your SQL queries are running as efficiently as possible, follow these practical tips:
- Use Indexes: As we’ve discussed in this article, indexing is crucial for query performance. Always make sure that the columns you frequently query are indexed. However, don’t go overboard with indexing; too many indexes can also hurt performance.
- Optimize Your WHERE Clauses: Try to make your WHERE clauses as selective as possible. That means they should filter out as many rows as possible. You can use different comparison operators, like =, \<, >, \<=, >=, and LIKE to achieve this.
- Limit the Use of SELECT* : When you only need a few columns, don’t use SELECT * to fetch all the columns. Instead, specify the columns you need in the SELECT statement.
- Use EXISTS Instead of IN: When you need to check for the existence of a value in another table, use the EXISTS clause instead of the IN clause. The EXISTS clause can often be more efficient.
- Avoid Using Cursors: In SQL, a cursor is a database object that can be used to manipulate the result set one row at a time. While they can be useful in some scenarios, they are generally not the most efficient way to process data in SQL.
- Minimize JOINs: If you can get the data you need without using a JOIN, that’s usually the best option. If you have to use a JOIN, try to make it as simple as possible.
- Use the Appropriate Data Types: Choose the most appropriate data type for your columns. Using the right data type can save storage space and improve query performance.
- Use Stored Procedures: Stored procedures can be pre-compiled and cached, which can lead to improved performance.
- Avoid Functions in WHERE Clauses: Using functions in your WHERE clauses can make it difficult for the database to use indexes. If possible, avoid using functions in WHERE clauses.
- Partition Your Data: If you have a very large table, consider partitioning it. Partitioning can improve query performance by dividing the table into smaller, more manageable pieces.
By following these tips and understanding the importance of indexing, you can significantly improve the performance of your SQL queries. Remember, the key to optimizing SQL queries is to write efficient and well-structured code, and to use the right tools and techniques for your specific needs.
Final Thoughts

Indexing is a critical part of database design and maintenance. It’s not just about improving query performance; it’s about enabling the database to handle larger datasets and more complex queries efficiently.
Understanding the fundamentals of indexing, knowing when and how to create indexes, and being aware of the potential trade-offs are all essential for success in database management. Whether you’re a seasoned database administrator or just starting with SQL, indexing will be a key aspect of your work, and mastering it will be key to optimizing the performance of your database.
So, keep learning, stay up-to-date with the latest techniques and best practices, and always strive to make your databases as efficient as possible.
Happy querying!
For more tips on how to speed up your SQL, check out Data Mentor – You can literally get advice on anything to do with data!
Frequently Asked Questions

What are the key index types in SQL?
The key index types in SQL are:
- Clustered Index: This type of index sorts and stores the data rows in the table or view based on their key values. There can be only one clustered index per table, as the data rows themselves are physically ordered based on the clustered index key.
- Non-Clustered Index: A non-clustered index is a separate structure from the data storage that contains the non-clustered index key values, each of which references the data row.
- Unique Index: A unique index is similar to a non-clustered index, except that it enforces the uniqueness of the values in the indexed columns. No two rows in the table can have the same values in the columns that are part of the unique index.
- Filtered Index: A filtered index is an index that includes only a subset of the data in a table. This can be useful when you want to create an index on a specific subset of the data, such as rows with a specific status or date range.
- Full-Text Index: A full-text index is a special type of index used for performing full-text searches on columns that contain large amounts of text data, such as varchar or nvarchar columns. It allows for more advanced search capabilities, including support for linguistic analysis and stemming.
How do you use indexing for SQL performance optimization?
To use indexing for SQL performance optimization, follow these steps:
- Identify the queries that are running slowly and analyze their execution plans.
- Determine which columns are being used in the WHERE, JOIN, and ORDER BY clauses of the slow queries.
- Create indexes on the columns identified in step 2 if they are not already indexed. Consider the appropriate index type (clustered, non-clustered, unique, etc.) based on the usage of the column.
- Regularly monitor and maintain the indexes in your database. This includes updating statistics, reorganizing or rebuilding indexes, and removing unused or redundant indexes.
How can I improve indexing in SQL Server?
To improve indexing in SQL Server, consider the following tips:
- Create indexes on columns that are frequently used in WHERE, JOIN, and ORDER BY clauses.
- Use covering indexes to include all the columns needed by a query in the index itself, rather than accessing the data from the table.
- Keep the number of indexes per table to a minimum, as too many indexes can degrade performance.
- Monitor and regularly maintain your indexes by updating statistics, reorganizing or rebuilding indexes, and removing unused or redundant indexes.
- Consider using the Database Engine Tuning Advisor (DTA) to analyze and recommend indexes for your database.
- Be cautious when using index hints, as they can lead to suboptimal query plans in some cases.
- Use the appropriate index type (clustered, non-clustered, unique, etc.) based on the usage of the column.
- Avoid creating indexes on columns with low selectivity or that are frequently updated.
What are some SQL index best practices?
Some SQL index best practices include:
- Only create indexes on columns that are frequently used in WHERE, JOIN, and ORDER BY clauses.
- Use covering indexes to include all the columns needed by a query in the index itself, rather than accessing the data from the table.
- Keep the number of indexes per table to a minimum, as too many indexes can degrade performance.
- Regularly monitor and maintain your indexes by updating statistics, reorganizing or rebuilding indexes, and removing unused or redundant indexes.
- Consider using the Database Engine Tuning Advisor (DTA) to analyze and recommend indexes for your database.
- Be cautious when using index hints, as they can lead to suboptimal query plans in some cases.
- Use the appropriate index type (clustered, non-clustered, unique, etc.) based on the usage of the column.
- Avoid creating indexes on columns with low selectivity or that are frequently updated.
- Always test the performance impact of new indexes on a staging environment before applying them to a production database.
What is the difference between a primary key and an index in SQL?
A primary key and an index in SQL are similar in that they both provide a way to quickly locate rows in a table, but there are some key differences:
- A primary key is a combination of unique and not null constraints. This means that it enforces the uniqueness of the values in the specified columns and also prevents those columns from containing null values.
- An index, on the other hand, is a separate data structure that is used to optimize the retrieval of data in a table. It can be created on one or more columns and can be either unique or non-unique.
- When a primary key is defined on a table, it automatically creates a unique, clustered index on the specified column(s). This means that the data in the table is physically sorted based on the primary key.
- An index, whether it is unique or non-unique, can be clustered or non-clustered. A clustered index determines the physical order of the data in the table, while a non-clustered index stores a separate, sorted copy of the data.


